- Blog
- 02.07.2023
5 Best Practices for managing Azure DevOps CI/CD Pipelines with Matillion ETL
 Azure DevOps is a highly flexible software development and deployment toolchain. It integrates closely with many other related Azure services, and its automation features are customizable to an almost limitless degree.
Azure DevOps is a highly flexible software development and deployment toolchain. It integrates closely with many other related Azure services, and its automation features are customizable to an almost limitless degree.
Matillion ETL is a cloud-native data integration platform, which helps transform businesses by providing fast and scalable insights. Matillion ETL's DevOps artifacts are source code and configuration files, and they are accessible through a sophisticated REST API.
Great flexibility in both platforms means it's possible to integrate Matillion ETL with Azure DevOps in many different ways. It can be difficult to decide how best to proceed! To help with that, we present five best practices that will help you get the most out of Azure DevOps in a Matillion ETL software development context.
Things to know:
- The Matillion ETL application consists of a number of related jobs which between them perform data extraction, load and integration using a Cloud Data Warehouse (CDW).
- Configuration data that varies between CDW environments, such as role-based access control metadata in the form of grants and roles, is held in administrative scripts held under source control alongside the Matillion application.
- The CI/CD pipeline workflow is initiated when a developer saves updates into the source code repository. The goal of the automation is to deploy those changes to Production in a governed and efficient way.
Each of the following five best practices includes practical, hands-on code samples and screenshots taken from the above scenario. We will be using GitHub Actions as the CI/CD workflow provider. You can download the full YAML configuration file from among the links at the end of the article.
1. Choose your methodology
Every contemporary cloud-native application typically has many components and interdependencies. This particularly applies in the stateful world of data processing. Successful deployment of a cloud native data processing application typically requires the interoperation of multiple managed services. Automating the build and deployment needs a DevOps framework that is sophisticated enough to manage all the interdependencies.
In the deployment scenario we are following here, we have to make all of the following technology components work together:
- Azure DevOps itself
- GitHub-hosted Job Runners
- The Matillion Hub
- ARM templates
- Azure Network Security Groups
- Azure IAM
- The Matillion ETL REST API
- Cloud Data Warehouse
It's therefore vital to follow an application design methodology that gives the best opportunity for success, and use a DevOps methodology that’s capable of working in that context. A widely endorsed example is the Twelve-Factor application.
Here is a screenshot of the first twelve-factor application design principle in action inside Azure DevOps. The deployed service has exactly one codebase, and it is used for many deployments.
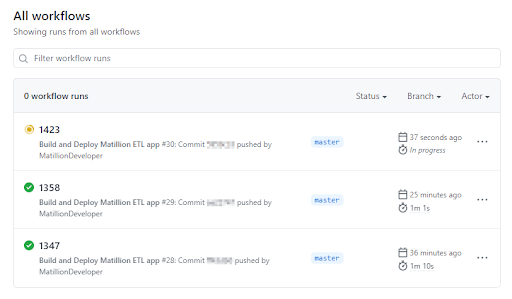
Another Twelve-Factor principle – the "Admin Processes" – is followed by keeping administrative scripts packaged in a GitHub repository alongside the Matillion application. This ensures that the scripts are available during the deployment stage, which means they can be used to automatically prepare the target Cloud Data Warehouse to receive the Matillion application.
2. Secure service integrations
Let's take a closer look at one of the integrations mentioned in the previous section: the Matillion ETL REST API.
During every software deployment, the GitHub job runners need to interact with the target Matillion ETL instance's REST API. Specifically, they require:
- Credentials to authenticate with Matillion ETL
- Network access
Securing the credentials is straightforward using GitHub Actions Secrets. Below is a screenshot of how they appear in this scenario. METL_SECRET contains the credentials for the target Matillion ETL server. The other secrets shown are the URL of the target instance and the Group name to be used in the deployment. 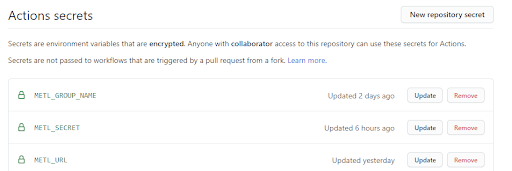 Establishing network access is rather more complex. GitHub runners are created on demand as short-lived container instances. They exist in an entirely separate virtual network with–as you would expect–absolutely no access to any resource in your Azure account. They do follow documented IP ranges, which you can find here under the "actions" section. But there are far too many ranges to add individually to a network security group (NSG).
Establishing network access is rather more complex. GitHub runners are created on demand as short-lived container instances. They exist in an entirely separate virtual network with–as you would expect–absolutely no access to any resource in your Azure account. They do follow documented IP ranges, which you can find here under the "actions" section. But there are far too many ranges to add individually to a network security group (NSG).
The solution is to apply some efficient automation:
- Find the IP address of the runner
- Adjust the NSG of the Matillion instance to permit the required ingress
One of the early deployment steps in this example solution finds and saves the public IP address of the runner instance like this:
IP=$(curl -s http://checkip.amazonaws.com) echo "PUBIP=$IP" >> $GITHUB_ENV
The Azure CLI provides this method to adjust an NSG. But it will only work once the CLI has been logged in to Azure. So another GitHub Actions Secret is needed for the Azure login credentials:  The resulting deployment script uses the credentials to login and adjust the NSG in two steps, like this:
The resulting deployment script uses the credentials to login and adjust the NSG in two steps, like this:
# Azure Login
- name: Azure Login
uses: azure/login@v1
with: creds: ${{ secrets.AZURE_CREDENTIALS }}
# Update the Azure NSG
- name: Update the NSG
uses: azure/CLI@v1
with: inlineScript: | az network nsg rule update ...
--source-address-prefixes "${{ env.PUBIP }}/32"
This section has shown a worked example of how to use features of the DevOps platform to securely and automatically integrate different managed services.
3. Govern access privileges
Governance of security is high up on the list of typical DevOps interoperability challenges. So in this section we will deep dive into managing the role-based access control (RBAC) that the GitHub runners use during the Matillion software deployment scenario we are following.
In the previous section, we were using an Azure identity named AZURE_CREDENTIALS to gain access to updating a network security group. This has in turn been using the transient RBAC provided by a Service Principal within Azure Active Directory.
Here is a summary of the solution:
- A Service Principal is created as an App Registration in the Microsoft identity platform
- It has an application password, which is shared with GitHub as an Actions Secret
- The App Service Principal is granted the minimum privileges required to fulfill its purpose of updating the NSG
App Registrations are performed in the Azure console within the Azure Active Directory blade. The one we have been using in this scenario looks like this: 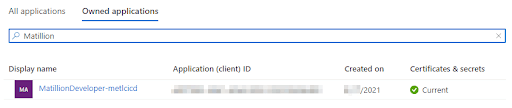 The GitHub AZURE_CREDENTIALS Actions Secret is a JSON fragment containing the subscriptionId, the clientId, the clientSecret and the tenantId all supplied by Azure. The GitHub runner uses the built-in azure/login@v1 action to exchange this authentication information for an Azure CLI access token.
The GitHub AZURE_CREDENTIALS Actions Secret is a JSON fragment containing the subscriptionId, the clientId, the clientSecret and the tenantId all supplied by Azure. The GitHub runner uses the built-in azure/login@v1 action to exchange this authentication information for an Azure CLI access token.
The only role assignment this needs in Azure is to modify the NSG. We used the contributor role, and it appears like this after setup. 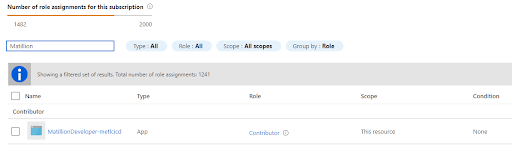 This section has been a short worked example demonstrating how we governed the Azure privileges granted to the CI/CD process, ensuring that only the minimum necessary access was granted.
This section has been a short worked example demonstrating how we governed the Azure privileges granted to the CI/CD process, ensuring that only the minimum necessary access was granted.
4. Build teams, not silos
In the data transformation and integration world, we are used to the word "silo" implying a data silo. However, in the context of CI/CD, a silo is usually a team, a tool, or a process.
Here's a practical example of that:
- The data engineering teams will talk about data transformation and integration. Data science teams will build upon that with statistical and AI/ML processes running against integrated data.
- The IT teams will talk about physical infrastructure, and the primary concern with their processes is around efficiency and automation.
- The business teams will talk about operations, and their processes are focussed on gaining insights which can help drive the business forward.
Where's the common ground?
In this case the silos are broken down with the help of the Matillion ETL REST API.
- The data engineering teams use the Matillion ETL REST API to export their work in a portable way. As part of a unified data science and BI environment, the data science teams can similarly save their source code and configuration files alongside the corresponding Matillion jobs. The entire interrelated codebase is then stored in a single place ready for automated deployment.
- The IT teams can create DevOps processes which start by picking up the artifacts from the previous step. They are automatically deployed to the appropriate physical infrastructure, and launched to fulfil their purpose.
- The business teams then have access to the latest data insights, without having to get involved with (and potentially block) the previous activities. They can continue the loop by speaking to the data engineering and data science teams to request the next round in the cycle.
In this worked example, the steps begin with an export of Matillion jobs by the data engineering teams, for example like this:
curl -o jobs/METLJob.json ...
https://...job/.../export
The DevOps pipeline uses further Matillion REST API calls to delete and recreate each job in the change set. No manual intervention is needed. The relevant part of the event stream from a deployment run is shown below.
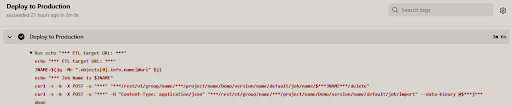
Good DevOps capabilities and practices go a long way toward removing the risk of silos forming during the application lifecycle. The upshot is–of course–faster time to insight for the business.
This section also shows how the "API First" and "Port Binding" Twelve-Factor principles help remove the risk of silos between teams and processes.
5. Enable Agility
One of the main goals of CI/CD is to make it easy to perform continuous integration and deployment. In order to implement any agile methodology you must always be able to quickly deploy the latest working code to a target environment. Data processing software poses a unique challenge in this area because data has state. It's not feasible to re-build and reload an entire data warehouse every time a minor change is made to the code.
| This situation does not exist for stateless applications such as microservices. It's no problem to drop and recreate a function. But if you drop and recreate a database table, all its data is lost. Furthermore, any changes to the data transformation and integration logic might mean the dropped table would be populated differently. |
A good solution for streamlining data processing pipelines and making them run efficiently is to make them highly targeted. In the Matillion software deployment scenario we are following, that means:
- The data engineers and data scientists only commit artifacts that they have changed
- The DevOps pipeline runs for every commit
- In a Matillion ETL context, the DevOps pipeline deliberately targets only the changes that involve the Matillion ETL codebase
Gathering and committing the changed artifacts is done using the Matillion ETL REST API, as we saw in the previous section.
With Azure DevOps you can easily make a pipeline run upon every commit. You choose the name of the GitHub event that should trigger the workflow by setting the "on" element in the root map. In our worked example, it looks like this:
name: Build and Deploy Matillion ETL app
on:
push:
branches:
- master
Matillion's REST API generates JSON files for the job definitions. Within the workflow, it's not difficult to isolate the changes by checking out the entire repository into the runner, and then using a git metadata query. Our implementation does as follows:
# Checkout the repo so the workflow can access it
- name: Sync repository
uses: actions/checkout@v2
with: fetch-depth: 0
# List the changed files
- name: List changed
run: | git diff
--diff-filter=AM
--name-only
${{ github.event.before }}..${{ github.event.after }}
A section of the event stream from a full deployment run is shown below. It only contains a single Matillion ETL job:  In summary, the DevOps workflow has determined that only one Matillion job was changed, so that's the only one that needs to be replaced on the target Matillion ETL instance.
In summary, the DevOps workflow has determined that only one Matillion job was changed, so that's the only one that needs to be replaced on the target Matillion ETL instance.
This last best practice focuses on making sure the DevOps process only involves aspects of the solution that have been changed. This approach enables you to start small and scale later as the project requires. It's highly targeted and quick to run. This is a vital enabler for the early and continuous delivery of valuable software.
Next steps
This article has focused on best practices for managing Azure DevOps CI/CD Pipelines using one specific technique with Matillion ETL. As next steps, you might consider taking advantage of more sophisticated features such as:
- Approvals
- Adding more Azure service deployments, for example to integrate with Azure Queue Storage and the corresponding Matillion ETL functionality
- Adding pipelines to your Azure Boards as part of agile project management
- Introducing Exploratory & Manual Testing
- Visiting the CI/CD solution ideas area in the Azure documentation
Downloads
For reference, you can download the full GitHub workflow script that we have been using.
Integrate Matillion ETL with the data tools you use
To learn more about how Matillion works with some of the most commonly used data tools, including the ones that your team uses every day, request a demo.
Andreu Pintado
Featured Resources
The Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
BlogBuilding a Type 2 Slowly Changing Dimension in Matillion's Data Productivity Cloud
A Slowly Changing Dimension (SCD) is a dimension that stores and manages both current and historical data over time in a data ...
BlogEnhancing the Data Productivity Cloud via User Feedback
Find a data solution that allows you the option of low-code or high-code, extreme amounts of flexibility, tailored for cloud ...
Share: