- Blog
- 03.30.2023
- Dev Dialogues, Data Productivity Cloud 101
A Prescriptive Data Analytics Maturity Model
Traditional data analytics maturity models are descriptive. They contain lagging indicators that measure how much a business is gaining from its data. They all essentially look like this: 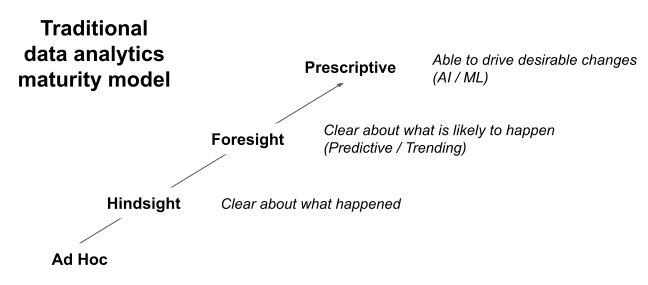 In this article I would like to move onwards, and present a forward-looking model with leading indicators. A prescriptive data analytics maturity model starts from a data analytics team's point of view, and examines:
In this article I would like to move onwards, and present a forward-looking model with leading indicators. A prescriptive data analytics maturity model starts from a data analytics team's point of view, and examines:
- what steps can be taken to move along a traditional maturity model
- what pitfalls to avoid along the way
The traditional style of data analytics maturity model implies that forecasts and AI/ML techniques replace hindsight. This is very misleading. The reality is that the steps are additive. They need to build upon each other. Good results from AI/ML algorithms depend on reliable input data, exactly the same as reporting in hindsight.
A new kind of maturity model is needed. One that helps us progress from data being an expensive liability, towards data being a valuable asset.
A Prescriptive Data Analytics Maturity Model
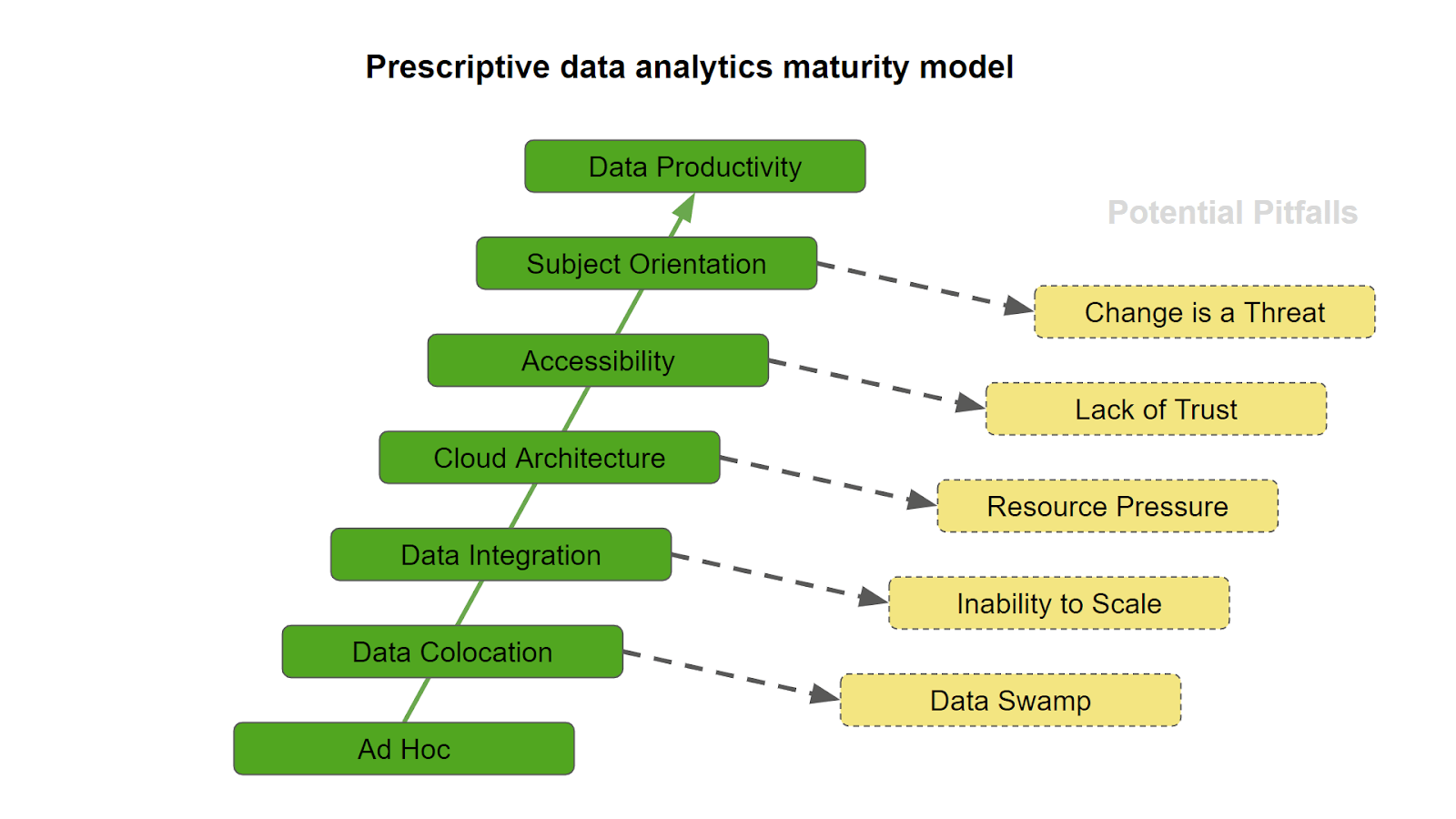 Entry is an ad hoc state of relative disorganization. Data may be delivering value in isolated cases, but overall there is a lack of strategy.
Entry is an ad hoc state of relative disorganization. Data may be delivering value in isolated cases, but overall there is a lack of strategy.
Moving forwards, the first step is simply getting hold of the data. Accessing all the potentially valuable source systems, and centralizing the resulting data using one chosen technology stack. This is known as data colocation.
Data Colocation
Data Colocation involves acquiring data from all available sources, and getting it together into one place.
It may be done by physically copying data - for example using a change data capture (CDC) process. Alternatively it may be done using virtualization or federation - in which case copying only happens at the moment the data is read.
It is relatively simple to connect to a source system and extract the data. There are two practical difficulties:
- The ever-growing number of ways that data can be accessed
- The ever-growing range of formats in which data can be delivered
In other words, data colocation deals with format proliferation.
However, data colocation is just a technical exercise. On its own, copying it from place to place does not immediately make data much more valuable. The data is of high quality, but is not very consumable - not easy to read correctly without remediation. 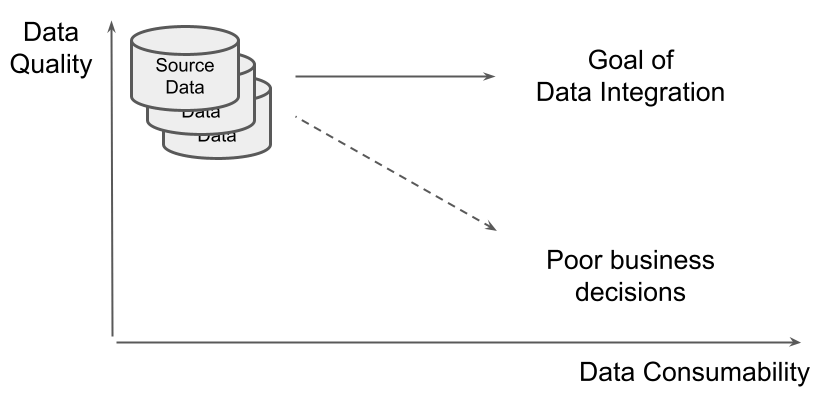 Trying to wring value out of fundamentally raw data sets can lead to the dead end of a data swamp.
Trying to wring value out of fundamentally raw data sets can lead to the dead end of a data swamp.  Getting past this stage, and starting to make data useful in the context of many other data sets, requires data integration.
Getting past this stage, and starting to make data useful in the context of many other data sets, requires data integration.
Data Integration
Data Integration starts with colocated data from multiple sources. Work is needed to:
- Bring consistency to all the different source domains and models
- Ensure that related data really does link together
- Make it clear and easy to read
This work is known as data transformation. It deals with the problem of source proliferation.
Organizations typically have large and diverse datasets to transform. It is far beyond the capabilities of a legacy on premises data center to do this efficiently and cost effectively. Cloud Data Warehouse (CDW) and Lakehouse services exist for this reason.
When using a CDW or Lakehouse, the data processing itself must be able to take full advantage of these new cloud technologies. Trying to handle large and diverse datasets using legacy techniques and tools greatly reduces the ability to scale your data integration solution.
You can avoid this potential pitfall by using a true cloud architecture.
Cloud Architecture
Many different services are available in a cloud-based technology stack. The list is constantly growing and evolving, too. All this choice represents an excellent opportunity to perform data integration securely, scalably and cost effectively.
Techniques and best practices for all these services are diverse. Furthermore, best practices for cloud services are very different from those in legacy on-premises solutions. Cloud data integration can easily become a realm for experts only. This causes chronic resource pressure, resulting in delays and long turnaround times.
I have placed Cloud Architecture relatively early in this maturity model for one main reason. You should not have to think about it. Data integration should be available for everyone to contribute, and take advantage of cloud services while doing so.
Innovations such as Low-Code / No-Code are key. They make sophisticated data integration accessible to all.
Accessibility
To reach the accessibility milestone, your data integration framework must meet two conditions. First, it must be open to all contributors: coders and non-coders. Second, this openness must not compromise functionality.
I will introduce the concept of a cloud data integration platform at this stage. A platform wraps the technical implementation details, and delivers the benefits of hand-coding without:
- the need for years of expertise
- the maintenance overhead associated with hand-coding
Using a cloud data integration platform, everyone can take full advantage of all the cloud services in their organization's unique technology stack.
Once cloud data integration is open to all, some level of coordination is needed. Without this, different departments will work independently - creating their own rules and definitions. This can lead to duplication of effort and lack of consistency. Typical symptoms to look out for are:
- Multiple copies of what seems to be the same data
- Totals and subtotals inconsistent between departments. Nobody agrees how many widgets there actually are
- Difficulty drilling into figures cross domain. Total widgets by product differs from total widgets by region
- Data science teams duplicating data engineering work
- Data mesh teams that don't cooperate with each other
Note that cataloguing alone does not solve these problems. In the catalog below there be dragons in more than one place. Which is right?  Without coordination, a corrosive lack of trust can develop. In turn, this makes it difficult to confidently take data driven business decisions.
Without coordination, a corrosive lack of trust can develop. In turn, this makes it difficult to confidently take data driven business decisions.
To move onwards, get all data on one subject into just one place, and do the relevant data transformation work only once. This is known as Subject Orientation.
Subject Orientation
This milestone is all about focus. Finding all the data about one subject should mean only having to look in one place. 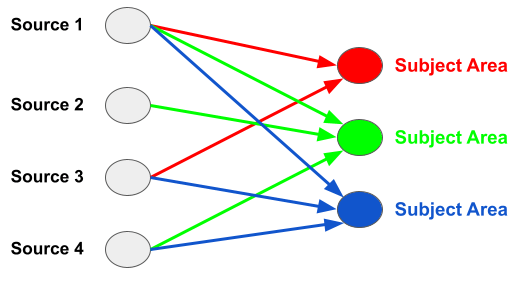 If data integration is centralized, the team must transform all the source data to merge it by subject area. They must also publish the resulting data model and definitions.
If data integration is centralized, the team must transform all the source data to merge it by subject area. They must also publish the resulting data model and definitions.
If data integration is decentralized - data mesh style - then everyone has
- The right to create and use data for their own needs
- The responsibility to publish the definitions they own
- The responsibility to use the definitions owned by others
Subject Orientation deals with reliability and trustworthiness. There can be no disagreement about what a "widget" is (or a "product", or a "region") because there is only one version of that information to consume.
It becomes possible to reliably drill across domains:
- Subject orientation makes reports add up
- Subject orientation makes data catalogs useful
Differentiating between hindsight, insight and foresight is spurious. The really important thing is that the data underpinning those activities can be trusted.
It has taken a lot to reach this point in the maturity model. Data is being acquired and integrated using the best cloud technologies. Everyone in the business is able to contribute, and everyone is working together towards a common, subject oriented data model.
Incoming change requests are a good sign that data is being genuinely useful. But there is a danger that complexity has built up to the extent that making changes presents a risk.
- Can anybody actually understand the current logic?
- Will a new use case break the governance?
- Is schema drift likely to make the data transformations misbehave?
Getting past this complexity challenge is the final step. It requires a cloud data integration platform that can deliver data productivity.
Data Productivity
The data productivity milestone means being able to easily change data transformation and integration, without sacrificing governance and reliability.
A good indicator is when data teams are able to participate in the same development methodologies as those at source. Project scope includes the concept of "data".
Cloud data integration platform features supporting data productivity include:
- A data centric UX - so data processing is easy to understand and maintain
- The ability to create and deploy templates - for reusability
- Declarative governance - so it is included automatically
- Data Lineage - backwards for problem analysis: forwards for impact assessment
- Data Cataloging - making integrated data more consumable
- The ability to quickly take advantage of the ever increasing cloud service landscape, for example in the area of AI/ML
- DataOps features such as API integrations, that treat software as a byproduct of data integration, not a goal
With this support, change requests become an opportunity, not a threat.
The same set of subject oriented data underpins hindsight, insight, foresight and AI/ML. Congratulations! Data has become a valuable asset, no longer an expensive liability.
Andreu Pintado
Featured Resources
Enhancing the Data Productivity Cloud via User Feedback
Find a data solution that allows you the option of low-code or high-code, extreme amounts of flexibility, tailored for cloud ...
NewsVMware and AWS Alumnus Appointed Matillion Chief Revenue Officer
Data integration firm adds cloud veteran Eric Benson to drive ...
BlogHow Matillion Addresses Data Virtualization
This blog is in direct response to the following quote from ...
Share: