- Blog
- 07.06.2022
- Dev Dialogues
Building a Star Schema with Matillion
This is an article for data modelers using Matillion. It describes how to implement a Star Schema design that includes Dimension and Fact tables.
Prerequisites
The prerequisites for building a Star Schema with Matillion are:
- Access to Matillion ETL
- You have already extracted and loaded the necessary data into your Cloud Data Platform (CDP) – for example, using Matillion ETL or Matillion Data Loader
- Familiarity with the downstream requirements regarding reporting, dashboards, analytics, and data science
- Some data modeling experience is useful
Star Schema concepts
A Star Schema is a data modeling approach designed to deliver highly consumable data to end users. It is a tried and tested method that has been in widespread use since the 1990s. Star Schemas help make data actionable and analytics-ready; they are simple to understand and fast to query.
Star Schema design is sometimes known as dimensional modeling. There are two types of database tables in a dimensional model:
- Dimension tables – the “by” criteria – especially the descriptive, textual information that provides context and drill
- Fact tables – all the transactions, amounts, and measurables
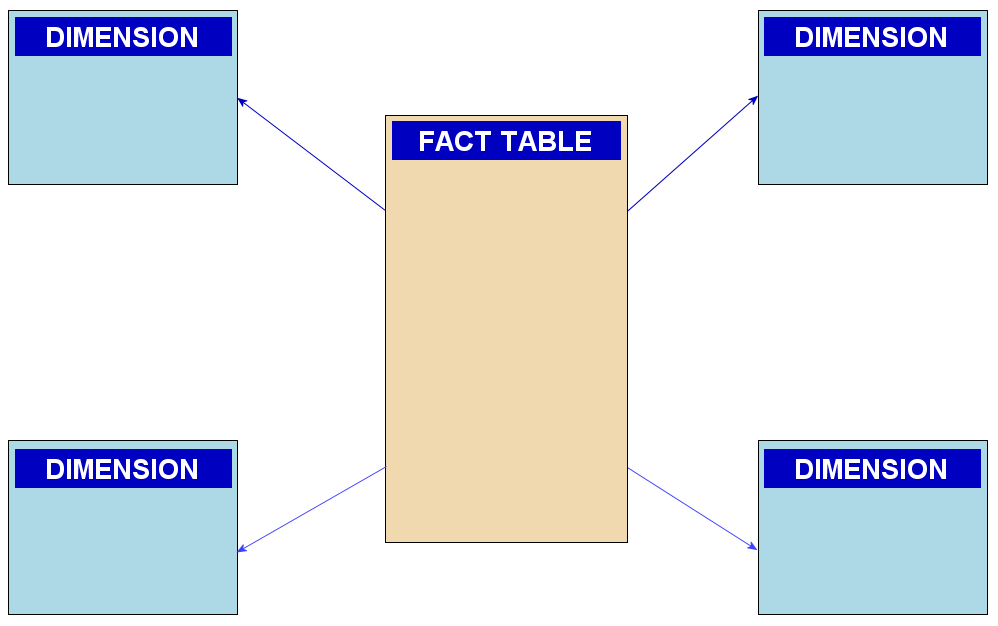
When they are shown as an Entity Relationship Diagram, Dimension and Fact tables always appear in a star shape, with the Fact table in the middle and the Dimensions as the “points.”
Both Facts and Dimensions are ordinary relational database tables, so it can be hard to tell them apart.
Implement a table naming standard that distinguishes Dimension tables from Fact tables |

Creating Dimension tables
Dimensions provide the main structure of a Star Schema. They determine how the Facts can be compared and aggregated.
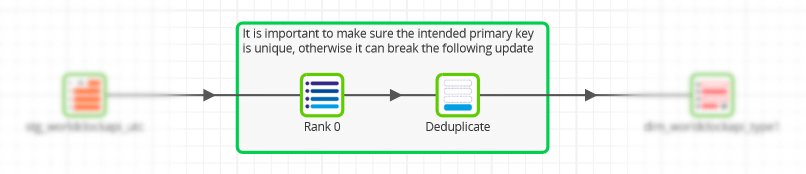
It is vital to have a clear understanding of what combination of fields makes every record in a Dimension table unique. This is known as the business key, and it defines the granularity.
In a Matillion ETL Transformation Job, use a Rank and Filter combination of components to ensure uniqueness. The screenshot below is from the “example scd type 1 update” job in the downloadable examples.
Dimension tables are characterized by having two sets of unique fields:
- A unique key – known as the business key. As described above, this is for deduplication when adding records to the table
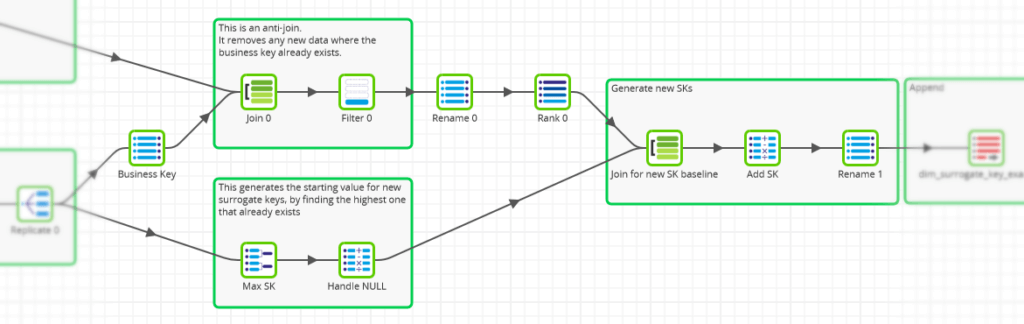
- A primary key – known as a surrogate key. This is a single field, created during data transformation and used to link the Facts and the Dimensions
There are many advantages to using a surrogate key for linking. It is much simpler to consume and join queries usually run faster. Surrogate keys also offer some protection against schema drift.
To generate unique surrogate keys for new records in a Matillion ETL Transformation Job, use an anti-join, a parallel aggregation, and an analytic function. The screenshot below is from the “example surrogate key pattern transform” job in the downloadable examples.
It is also possible to deploy meaningful surrogate keys. This is most common with date and time Dimensions; for example, the integer surrogate key 20200129 would always refer to 29th January 2020.
Dimension tables normally contain special records for missing or unknown values. Add them using a Fixed Flow and a Unite component like this:
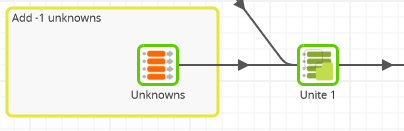
After all the Dimension tables contain data, you can move on to the Fact tables.
Creating Fact tables – defining Lookups
Fact tables hold all the figures in a Star Schema, especially numeric values that can be summed and averaged.
The granularity of a Fact table depends on the combination of Dimension tables it links to. Fact tables are characterized by having many foreign key fields that reference the surrogate keys on those Dimension tables.
Most of the work when creating Fact table records is looking up the correct record from the Dimension tables – finding the surrogate key given the business key. In a Matillion ETL Transformation Job this is done with Join components. The screenshot below is from the “example datamodel xform 3nf to star part 3” job in the downloadable examples.
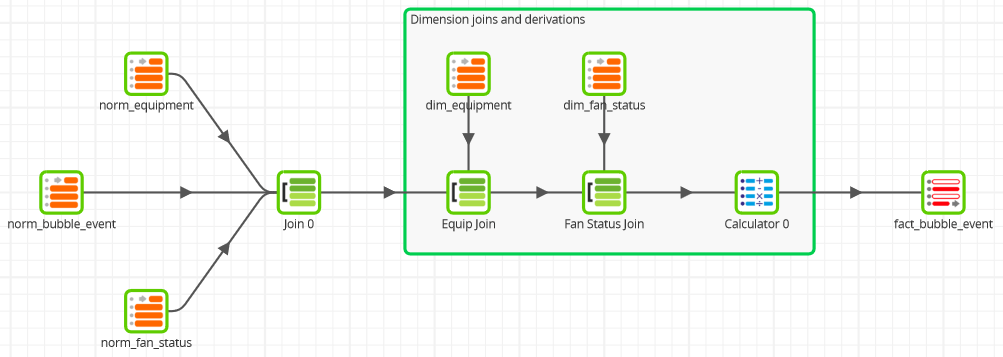
This is a very common way to prepare Fact table records. The example job contains:
- Three initial joins to generate the Fact data at the correct granularity. The naming standard norm* indicates that the source is a normalized data tier
- Two more joins to Dimension tables – named dim* – to find the right surrogate key for all the Dimension values
- More transformation – with a Calculator component – to apply defaults for missing values, and to set meaningful surrogate keys such as dates
Fact table Transformation Jobs often end with a Table Output component that just appends the new records to the target table. This is a great strategy for transactional and time series data such as IoT, where there may not be a unique key.
The example above is a little more sophisticated. The Fact data does have a natural, unique key, so the job ends with a Table Update component instead. This makes the job rerunnable, at the expense of slightly slower performance.
Most Fact tables contain additive, numeric columns, but that is not mandatory. It is possible to record that an event happened using only Dimensions, for example, Event Type and Date. A Fact table with no numeric attributes is known as a Factless Fact.
There are several more variations, too:
- Aggregate – produced by grouping an existing Fact table on a smaller number of Dimensions
- Accumulating Snapshot – representing the state of a long-lived event, such as order fulfillment. These tables often contain many timestamps, and are calculated from more granular Fact tables
- Periodic Snapshot – recording a status at predictable intervals, for example, end-of-day balances
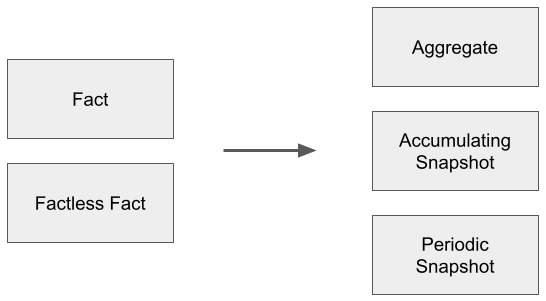
It is always important to be aware of what kind of Fact table you are operating on. The choice greatly influences the optimal strategy regarding appending, updating, or re-creating the table each time.
Next Steps
Learn more about building a scalable data architecture:
- Learn about different database schema types and examples
- More about creating highly consumable data
- Implement time-variant data with slowly changing dimensions
- Decide which data tiers to deploy
- Compare data vault vs. star schema
- Aim for a modern data-driven culture focused on data sharing
- Prepare to iterate data rapidly and track lineage
Featured Resources
How Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
BlogBuilding a Type 2 Slowly Changing Dimension in Matillion's Data Productivity Cloud
A Slowly Changing Dimension (SCD) is a dimension that stores and manages both current and historical data over time in a data ...
Share: