- Blog
- 06.02.2022
Database Schema: Types, Examples, and Benefits

Having the right schema is a key factor supporting modern data analytics. Database schemas can be confusing, but this article will help you design the right schema for your data stores – starting right from the definition of a “database schema” itself.
What is a database schema?
In the context of data models, a “schema” means the overall data model and design of the data structures. The act of designing a schema is known as data modeling.
Semi-structured data is a fast-growing part of the ever increasing data diversity in modern data analytics. The “schema” is the logical layout that exists within a semi-structured document.
However, the word “schema” can also mean a physical part of a database. Many cloud data platforms – including Amazon Redshift, Snowflake and Azure Synapse Analytics – have the concept of a “database” as their main unit of structure. One database can contain many schemas, and the schemas contain the schema objects such as tables, columns and keys of the data.
Types of database schema models
The very simplest type of database schema is a flat model. A flat model contains standalone tables that are not related to each other. It also implies that all the columns are simple strings and numbers, rather than being semi-structured. The most widely used flat database schemas are CSV files.

A hierarchical database schema model contains parent-child relationships, exactly like a family tree. Hierarchical models have been used for more than 50 years, especially for high performance OLTP systems such as Adabas. Every JSON or XML document contains a hierarchical data model.
With a graph model, data points known as nodes are related to each other using “edges”. Just like in the real world, there are no constraints on what nodes can be linked. This makes graph models perfect for knowledge encoding as RDF, for example using Neo4j or Gremlin. Network models are a subset of graph models in which the schema defines a clear hierarchy. For example one account contains many transactions – not the other way around.

Relational models have tables that relate to each other using primary key and foreign key columns. When represented graphically, a relational database schema is called an Entity Relationship Diagram (ERD). If you have an ERD, you have a relational data model.
For data presentation purposes, nothing beats the simplicity of having one table of transactional facts, linked to many dimension tables of “by” criteria. When drawn as an ERD this kind of model has a star shape, and so is known as a star schema.
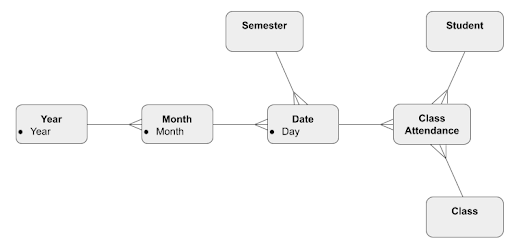
There may be a significant amount of repetition in a star schema. For example, in a date dimension every single year-level attribute is repeated 365 times. You can cascade those out into sub tables, for example day – month – year. That gives the ERD an appearance more like a snowflake, and so is known as a snowflake schema.
Entity relationship diagram examples
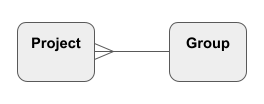
In relational models the most common relationship is one-to-many. For example if one Group can contain many Projects, it would be drawn like this:
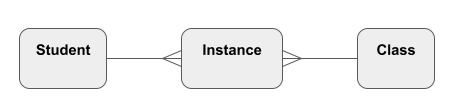
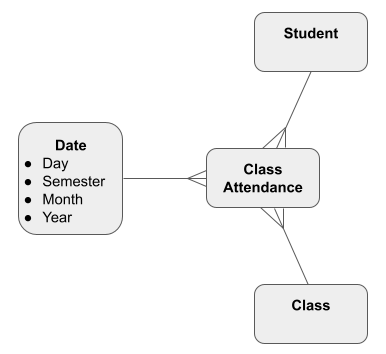
Sometimes the relationships are more sophisticated. For example, one Student takes many Classes, and one Class contains many Students. A Many-to-Many relationship is usually replaced with an intersection entity like this:
As a star schema, with a class attendance fact table, it might look like this:
And finally, as a snowflake schema, like this. Note the addition of sub tables, leading to less data repetition but more joins:
How to handle semi-structured data
The main feature of semi-structured data – such as JSON – is that it’s the most convenient format for the writer of the data.
In fact, semi-structured data is highly structured, but in a flexible way that allows endless wriggle room for changes – known as “schema drift.” The rows in a semi-structured table might not all have exactly the same attributes, and there is no way to actually find out other than going ahead and reading it. This is called “schema on read.“
The goal of data integration is to increase data consumability while keeping the data quality at its original high level. Usually this means “flattening” semi-structured data by converting it into a relational model.
- Hierarchies → Multiple tables
- Schema on Read → Named columns
However semi-structured formats can still be a useful way to postpone data integration, for example in Data Vault Satellite tables.
What is data normalization and why is it critical?
Data normalization is a data modeling (schema design) process. It ensures that a relational model adheres to basic quality controls. The main standard is known as third normal form (3NF) and has these requirements:
- Tables have a unique identifier, removing duplication
- Relationships are one-to-many rather than many-to-many, reducing confusion
- Columns have defined data types, avoiding inconsistency
- Columns contain single values such as strings and numbers, clearing the way for efficient integration, which solves the problems of decentralization
In fact, star schemas – used by almost every data warehouse – are deliberately somewhat denormalized. They often contain some duplication to make queries simpler and faster. The key to implementing a star schema successfully is to use a transformed and normalized data layer as the source. That way, there is a data quality control to guarantee that the data retains its value.
Importance and benefits of good database design
Having a data architecture with a well defined – and, ideally, normalized – schema helps maintain data quality by taking advantage of database constraints such as consistent formatting and enforcing referential integrity during lookups. It also helps minimize data duplication. Both of these things underpin reliable analytics.
In terms of security, having a schema helps with governing access to data. This applies especially when protecting personally identifiable information (PII) that normally needs extra layers of protection such as tokenization.
Learn about the differences between Domain Modeling, Physical Modeling and Logical Modeling.
Understanding the data model of a database
The best way to understand a data integration system at the top level is to look at what kinds of data models – or schemas – have been used in the different logical data layers.
As data consumability moves through bronze, silver, and gold stages, the data models change too. For this reason, you should know all about how to compare data vault vs star schema vs 3NF.
- Early on, in the bronze stages, data models are dictated by the sources, and may be semi-structured or even unstructured. This is the place for Flat, Hierarchical, Graph and Network models.
- In the mid-tier, silver stages, relational models such as 3NF and Data Vault predominate
- For presentation to users, the best choices are star schemas or snowflake schemas
What is the best way to move data between these layers? The short answer is an extract, load and transform process (ELT).
Database schemas and their relationship to data warehouses
From bronze to silver, the main problem is finding the data you need from among the data that is actually available. ELT is the process of getting hold of the raw data, and converting it into the standardized format.
From silver to gold, the main problem is choosing the data the consumers need, and presenting it in the most consumable way.
Next steps
Read about how to use schemas to keep data quality high while improving consumability.
Learn more about how Matillion provides a complete data integration and transformation solution that is built for the cloud and has numerous database connectors to replicate your data in the cloud.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: