- Blog
- 01.26.2022
Matillion Architecture – Amazon Redshift
Your business needs a way to move all your business’ diverse data to a centralized location. Matillion is a data transformation solution that orchestrates the data loading process and then transforms that data into meaningful insights. Before you get started you will want to understand how Matillion works with your Amazon Redshift warehouse and other AWS, Business Intelligence, and visualization services.
Built for Amazon Redshift, Matillion is spun up as an EC2 instance within your own AWS account. This means you have complete control over that instance and Matillion cannot access it, unlike SaaS tools that send your data to an external ETL server. Matillion’s model, is, therefore, an ideal alternative for data-sensitive industries like health and finance. The following recommended architecture will help you make the most of your Amazon Redshift cloud data warehouse and Matillion.
Recommended Architecture in AWS
We recommend that Matillion is launched in the same region as Amazon Redshift, in either the same VPC or in a peered VPC. Matillion can either be launched as an Amazon Machine Image (AMI), which you can fit into your existing architecture or as a Cloud Formation template which an spin up the required resources in conjunction with spinning up Matillion from the AMI.
An S3 Bucket will be required in the same region as Amazon Redshift. Matillion uses S3 to stage your business data to before it is copied into Amazon Redshift. You can also use S3 as a data lake if you wish to have a copy of your data outside of Amazon Redshift.
Matillion’s access to AWS resources is controlled by the IAM role which the Matillion instance is running as. This can give Matillion access to a number of AWS services that will streamline your data processes, such as, SNS, SQS, Cloudwatch, RDS, S3 and Amazon Redshift.
A security group for the Matillion instance controls who has access to that instance on which ports. We recommend only opening ports 80, 443 and 22 and to restrict these to known IP addresses.
This is what the architecture will look like once everything is spun up:
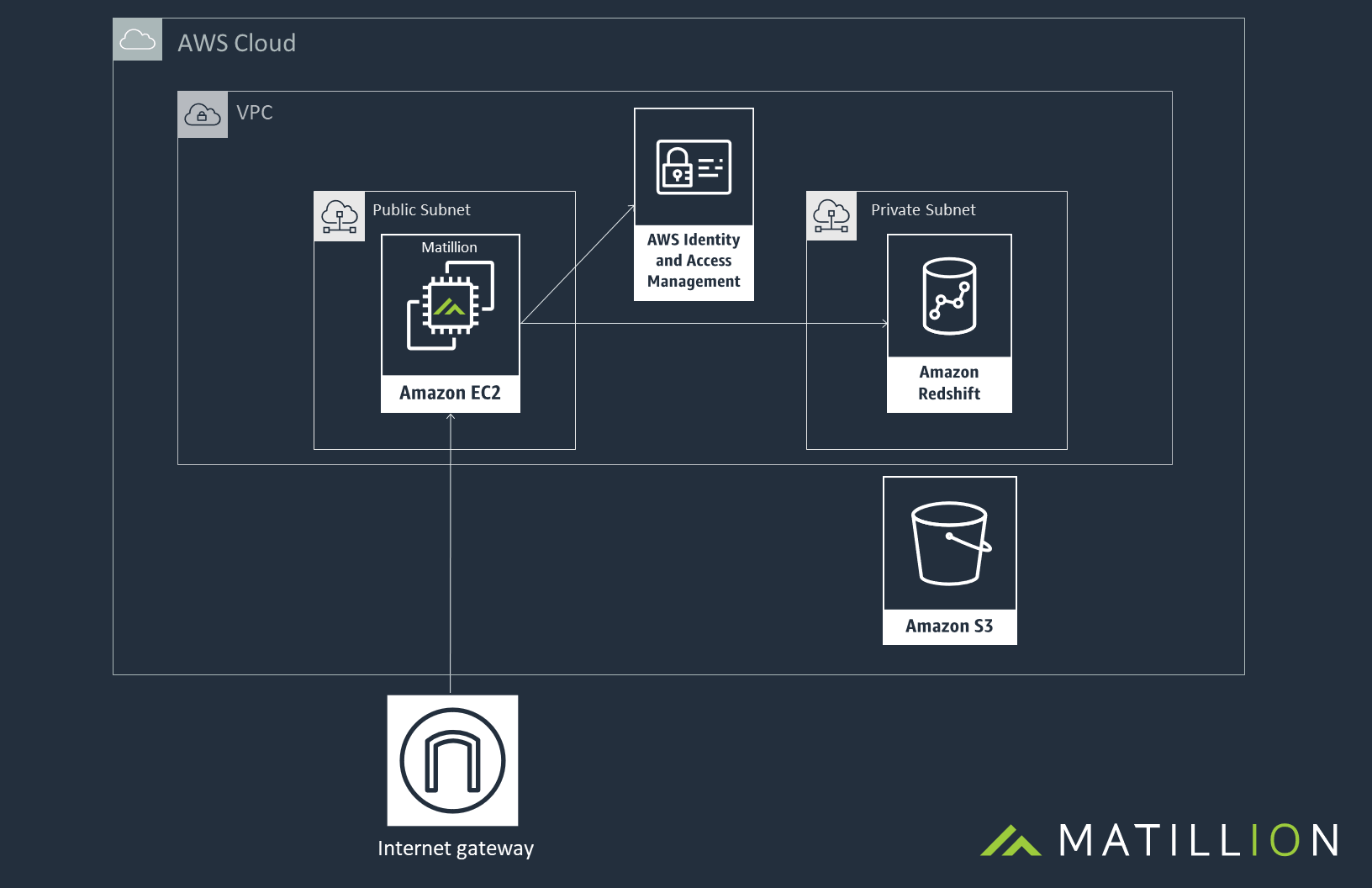
Matillion works by instructing Amazon Redshift. Amazon Redshift does the heavy lifting on behalf of Matillion. Data never leaves the cloud and is only held in memory on your Matillion instance. It is never pushed to an external Matillion ’server’.
Once your architecture is established you can start loading and transforming your business data.
Orchestration job
In Matillion an Orchestration Job is used to bring data from external sources into Amazon Redshift and a Transformation Job is used to perform the business logic, cleanse and prepare data for analytics and reporting within Amazon Redshift. Here we look at the architecture behind the different Matillion jobs.
Orchestration jobs come with over 50 pre-built data connectors, that take data from different sources and load that data into Amazon Redshift. Despite which connector you are using, they all work in a similar way: stream batches to a staging file, or a series of staging files, in Amazon Simple Storage (S3) and then uses an Amazon Redshift COPY command to load the contents of that file to Amazon Redshift.
Matillion allows you to keep a copy of those stage files in S3 if required. If not, Matillion will delete the file immediately after the load has completed.
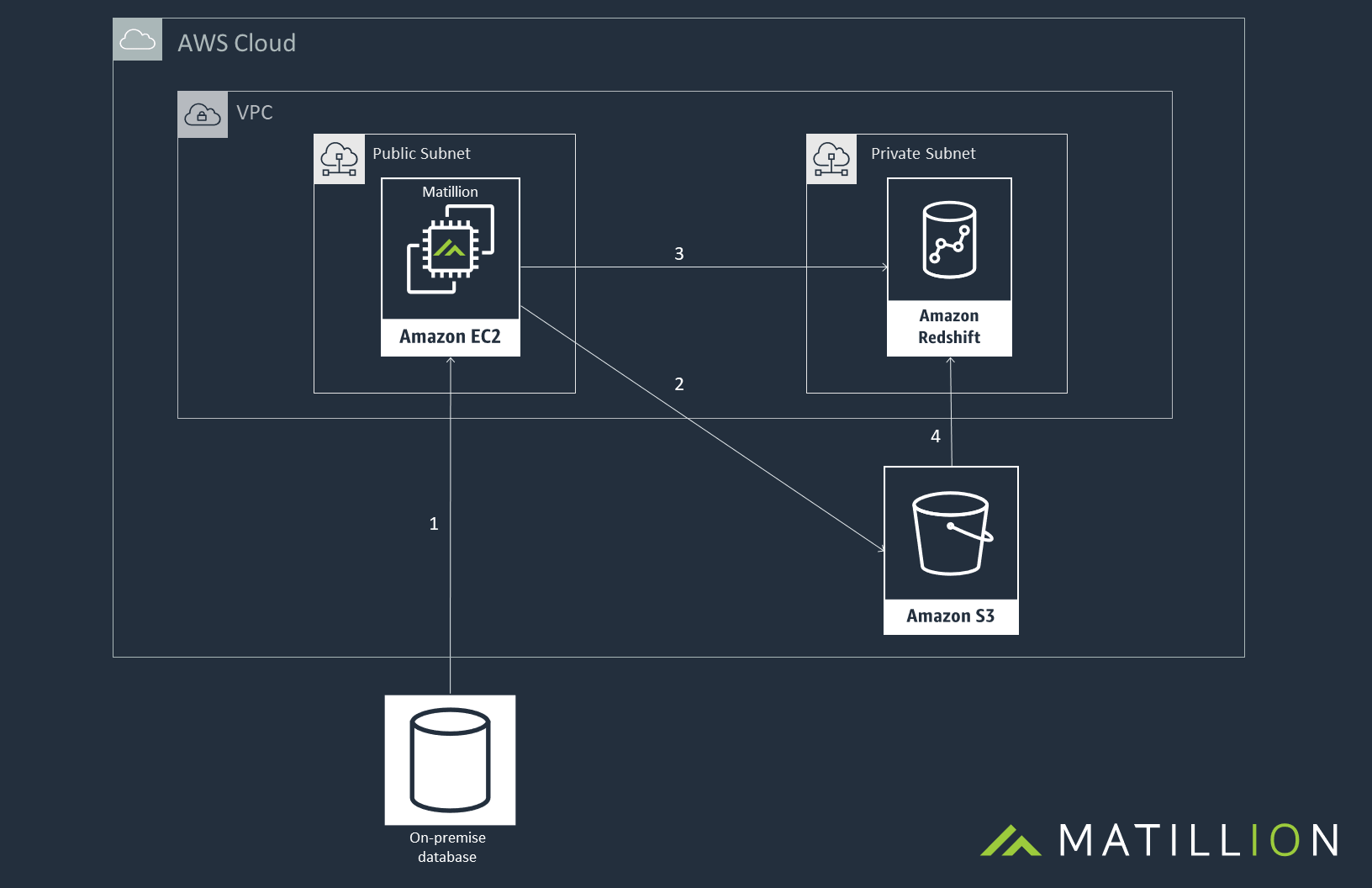
The above diagram shows how the loading process works in Matillion:
- First, connect Matillion with the required data source, this can be either on-premise or a data source in the cloud. Matillion will query the source data and stream it to the memory in the Matillion instance.
- This data will then be streamed from the instance up to the file(s) in S3.
- Next Matillion issues an Amazon Redshift COPY command, to trigger the data load.
- Amazon will then load the data from the file(s) down to Amazon Redshift.
Transformation job
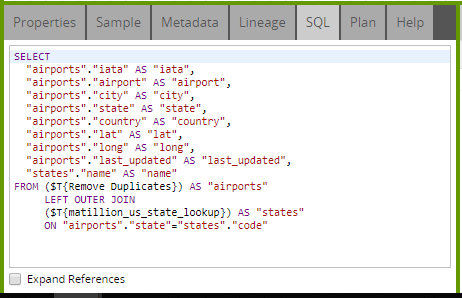
Once the data is available within Amazon Redshift, your business will most likely have a requirement to transform the data. You do this by adding new calculations, aggregating data and joining together different data sources. Matillion has many components to visualize and create this transformation. Each Transformation component works by generating a SQL statement. This SQL statement will be based on the prior component(s) and when the job is run, the final SQL statement in the job is sent down to Amazon Redshift to perform the Transformation required. If a Write component is used, the output of the SQL transformation will persist in Amazon Redshift as either a table or a view. The SQL generated can be seen in the SQL tab of any valid Transformation component:
Begin your data journey
Want to learn more or ready to get started?
The post Matillion Architecture – Amazon Redshift appeared first on Matillion.
Featured Resources
VMware and AWS Alumnus Appointed Matillion Chief Revenue Officer
Data integration firm adds cloud veteran Eric Benson to drive ...
BlogHow Matillion Addresses Data Virtualization
This blog is in direct response to the following quote from ...
BlogMastering Git at Matillion. Exploring Common Branching Strategies
Git-Flow is a robust branching model designed to streamline the development workflow. This strategy revolves around two main ...
Share: