- Blog
- 09.27.2022
Parsing Unstructured Data with Matillion and AWS Textract
At Matillion, our mission is to make the world's data useful. In service of that mission, we take it upon ourselves to simplify complex data operations. This week, our Solutions Engineering team built a Matillion Shared Job to parse unstructured data. Leveraging the power of existing services like Amazon Textract, we've been able to orchestrate a simple Matillion job that will take unstructured PDF input, and parse the text of that input into a Snowflake table for consumption and analysis.
What is a Matillion Shared Job?
A Matillion Shared Job is a set of operations built in Matillion ETL that is packaged as a single Matillion ETL Orchestration Component for you to consume. All of the configuration you need to do will be filled out in a guided way via the properties of the shared job. For our use case today, you can think of the textract shared job like an API that you feed a piece of unstructured data, in this case a PDF, to extract (or Textract) into a table inside your Snowflake warehouse.
Prerequisites and dependencies
- A Matillion ETL machine deployed in AWS for Snowflake. In this shared job, we are directly leveraging our tight integrations with Snowflake and AWS to execute the complexities of parsing text data out of images. Stay tuned for versions of this job that can be deployed to different cloud providers and data warehouses!
- The Textract Synchronous API, which this job leverages, allows for 10MB files to be uploaded
- You'll need to fill out the Job Variables in this shared job in order to run it, details in the image below
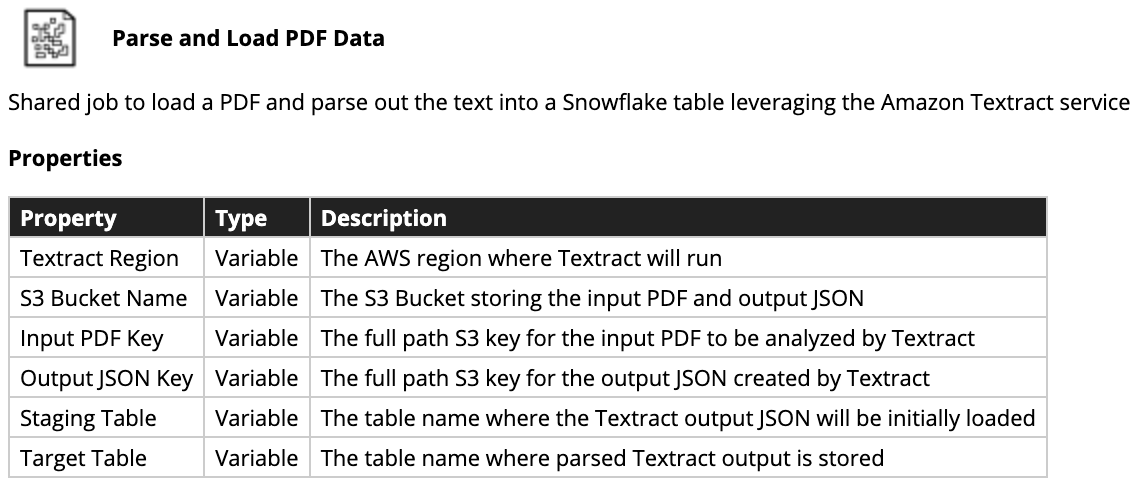
The Use Case
We could pass any single page PDF into this job, and for our example we will be passing a PDF of a Matillion Certification certificate. We could go on to build some analysis on the parsed dataset in Snowflake to see what the certificate is. In this case, it’s a Matillion Certification, certifying an ability to build data ingest and transformation pipelines with the power of a modern, cloud-native ELT solution in Matillion ETL.
What's under the hood?
We leverage a number of native Matillion components to:
- Send the Document through the Amazon Textract API
- Load the JSON output of the Textract API into Snowflake
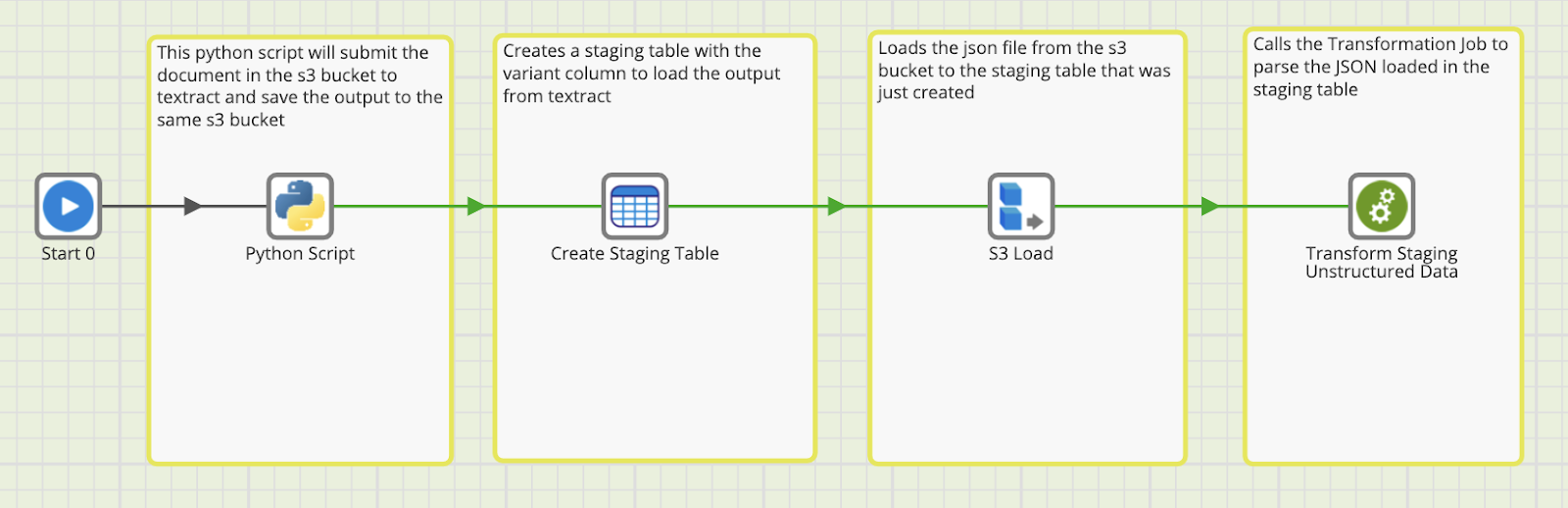
- Flatten the JSON data in Snowflake into a tabular format to save in a Snowflake table, enabling us to do further analysis on the data!
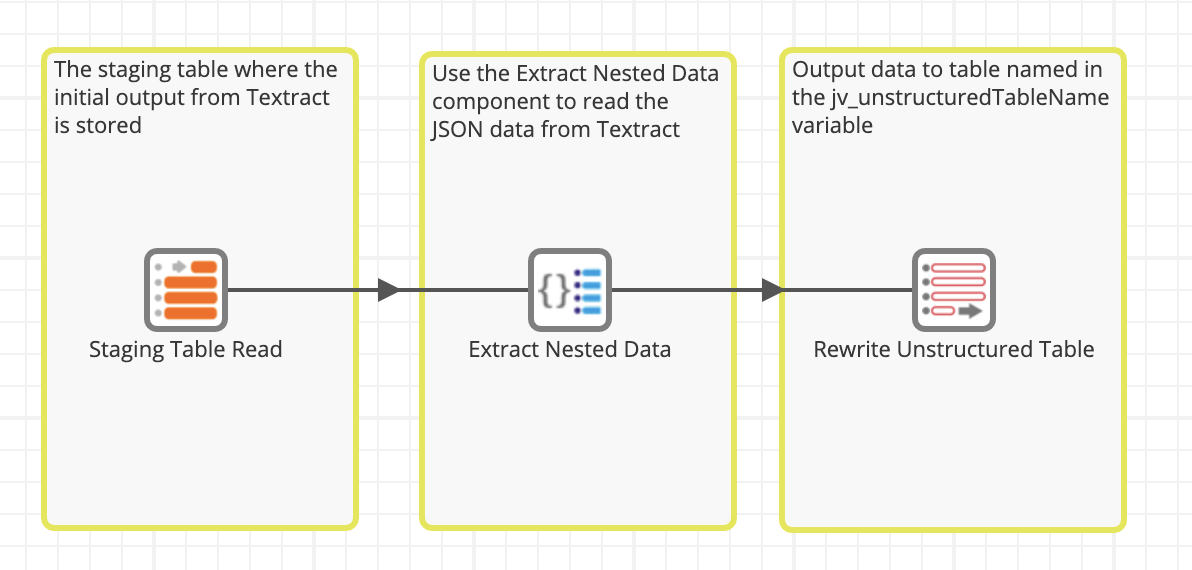
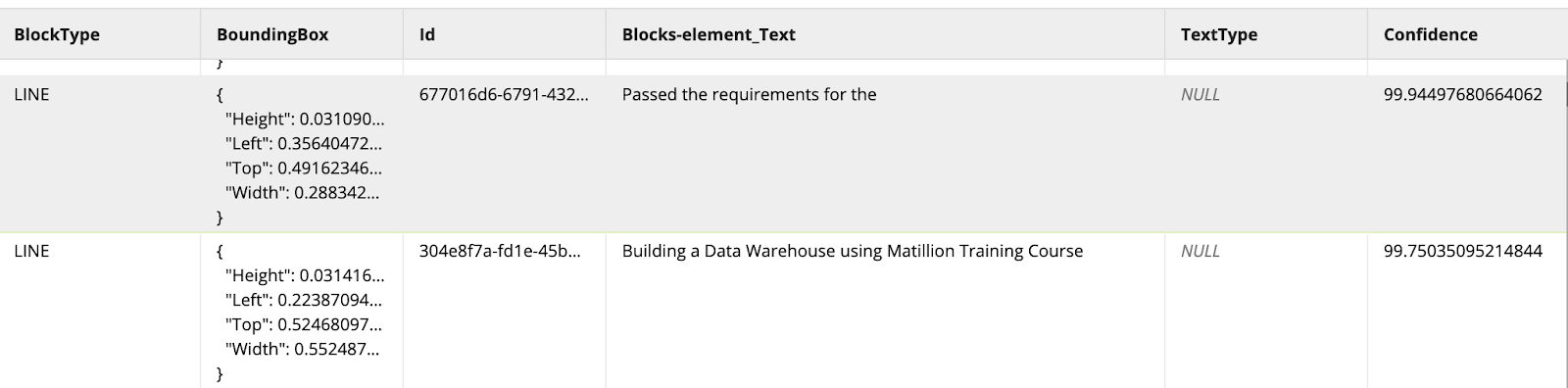
 Final output
Final output
Once the job completes, we get a tabular dataset in a Snowflake table. For our example use case, we can see that textract has a 99.8% confidence in the text extraction of "Building a Data Warehouse using Matillion Training Course" – get your Matillion Associate Certification today!
The Future of the Textract/PDF Extract shared job and Matillion
Keep an eye out for a version of this job that can read in multi-page images and PDFs, expanding to capture and leverage more of the functionality of the AWS Textract API!
How to find and install
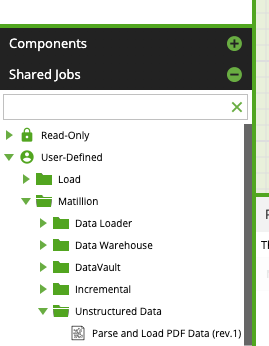
You can find the Textract Matillion Shared job listed at the Matillion Exchange. You'll log in with your existing Matillion credentials, and download the shared job. After downloading the shared job, unpack the zip file and import the job relevant to your platform by using the ‘Manage Shared Jobs’ menu. The .melt file will clearly state which platform it can run on, and for our case today, that will be Matillion ETL for Snowflake on AWS (e.g. Parse_and_Load_PDF_Data_Snowflake.melt). Once imported, the job will then appear as a user-defined shared job in the shared job palette as below:
New to Matillion?
To leverage this job, as well as all of the powerful and easy-to-use data load and transformation capabilities that Matillion provides, sign up for a free trial of Matillion ETL. The same team that built the Textract Shared Job will be there to guide you in your evaluation of Matillion's ability to solve your modern data challenges.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: