- Blog
- 03.07.2023
Dynamic Data Standardization with Matillion ETL
In today’s world, where organizations load data from dozens of different data sources, it is vital for companies to apply standardization practices to align data in a common format. However, this standardization practice can be extremely complex to apply, so it is often overlooked and results in inconsistent or error-prone data.
Fortunately, Matillion ETL provides various components that allow you to build a data standardization framework that can be applied to your data pipelines, all driven by metadata stored in your cloud data platform.
In this blog post, we will cover an example of a data standardization framework that applies metadata-driven cleansing rules built entirely using METL native components. Note: To use this framework, you must be running Matillion ETL version 1.64 or higher (Grid Variable support in the Calculator component was released in v1.64).
The DDS framework utilizes the bronze/silver/gold medallion architecture, which is just a representation of the different phases that the data moves through. You can look at this the same way as the raw data layer/ business layer/ presentation layer.
- Bronze layer: Data in its raw format from the source. This can be a raw query extract from a source database, a flat file load, api request payload, etc.
- Silver layer: This is where data lives after it has been filtered and cleansed. Think of these rules to be applied unilaterally, such as masking of SSN numbers, hashing credit card numbers, etc.
- Gold layer: This is where data lives after business rules and aggregations have been applied. This data is ready to be presented/analyzed/consumed by end users or other applications. An example of a business specific gold rule might be to round all dollar ($) amount columns to the 2nd digit after the decimal, except for finance where they might want to round data to the 3rd digit after the decimal, aggregating YOY revenue amounts into a table, or converting invalid values to null for a business specific reason.
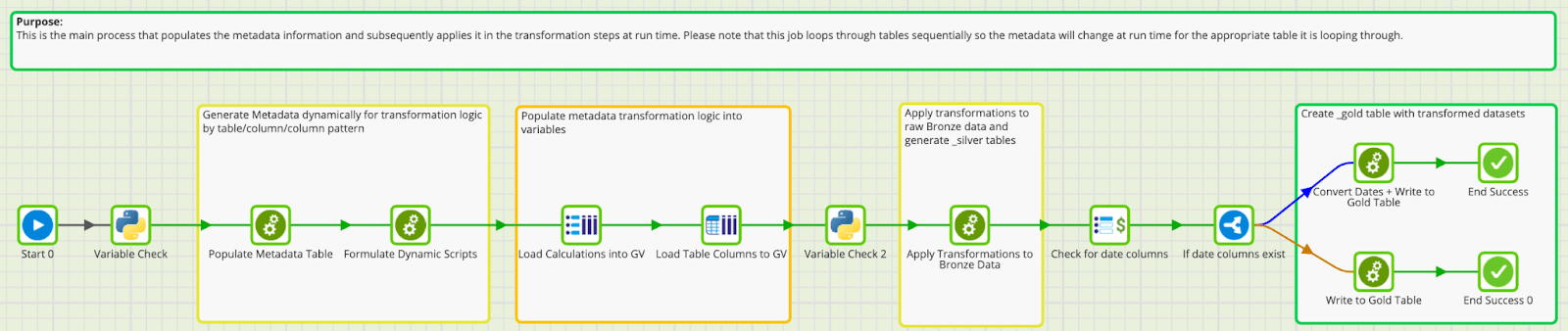
Project Overview
The project extracts provided will populate an 'Examples' folder, with a subfolder called 'Dynamic Data Standardization'. At the root of the subfolder, you will find an orchestration file called Dynamic Data Standardization. This is the only orchestration you need to run for this process. A more detailed breakdown of all the steps that this process goes through is found below. 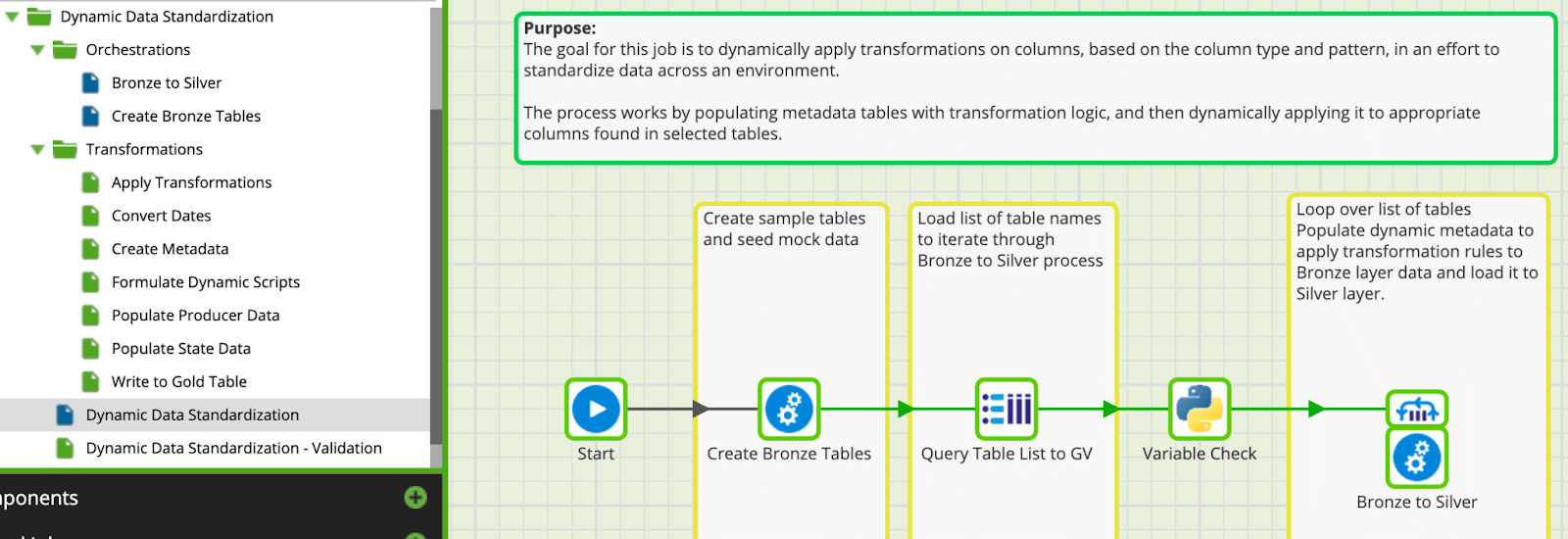 You will also see a transformation job called Dynamic Data Standardization - Validation. You can use this job to view the various tables and metadata tables that were created as part of this process. Its simply a consolidated view of the objects that are created by and leveraged in the DDS process.
You will also see a transformation job called Dynamic Data Standardization - Validation. You can use this job to view the various tables and metadata tables that were created as part of this process. Its simply a consolidated view of the objects that are created by and leveraged in the DDS process. 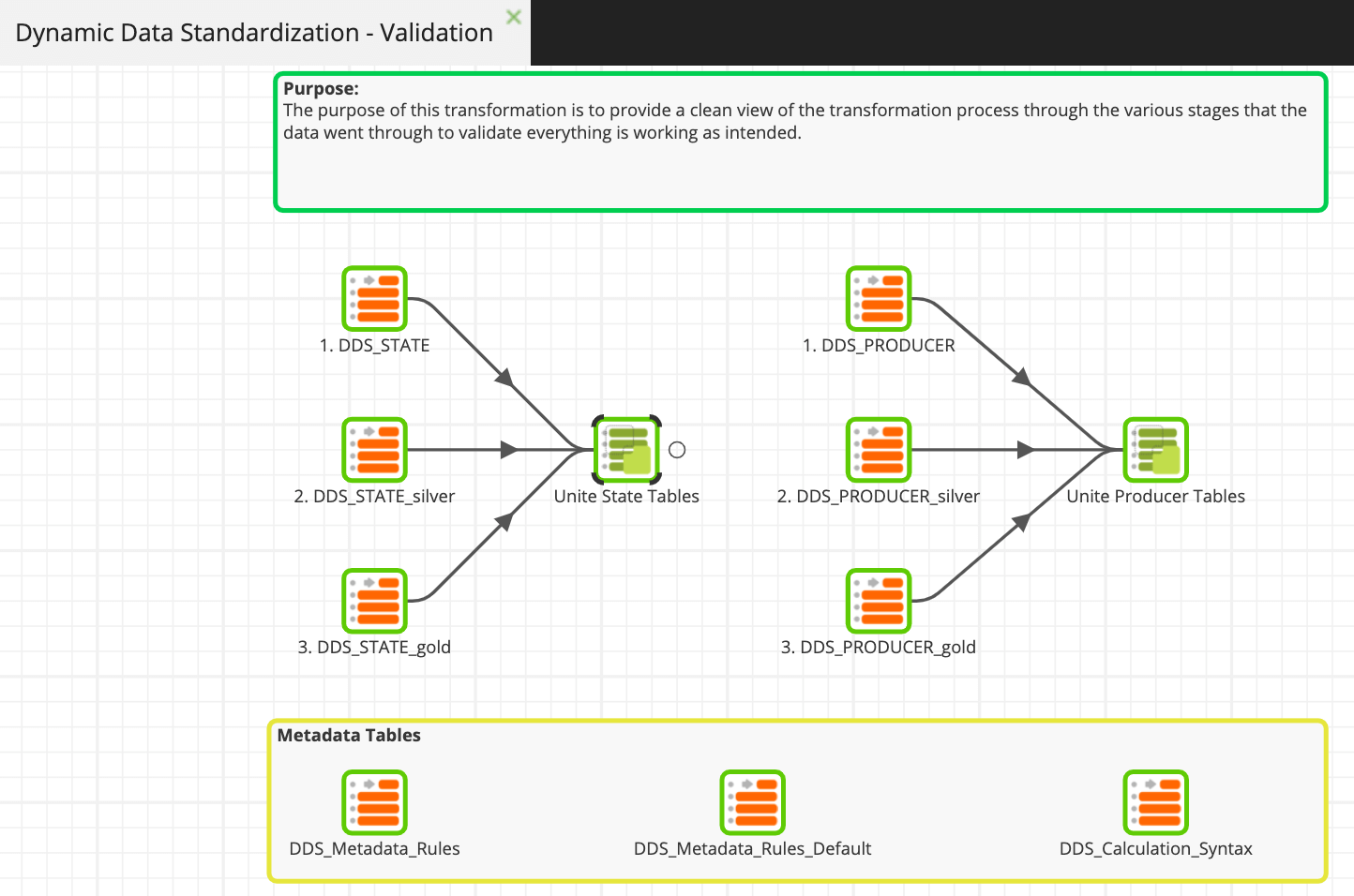
Creating Bronze Layer Data
To provide a working example out of box, we will need to create mock data and load it into the cloud data warehouse. This data is purposely ‘dirty’ to showcase the standardization rules that are applied throughout the process. We will create two tables, DDS_STATE and DDS_PRODUCER. These will represent our bronze layer, as this data is in its raw format and has no business rules applied. 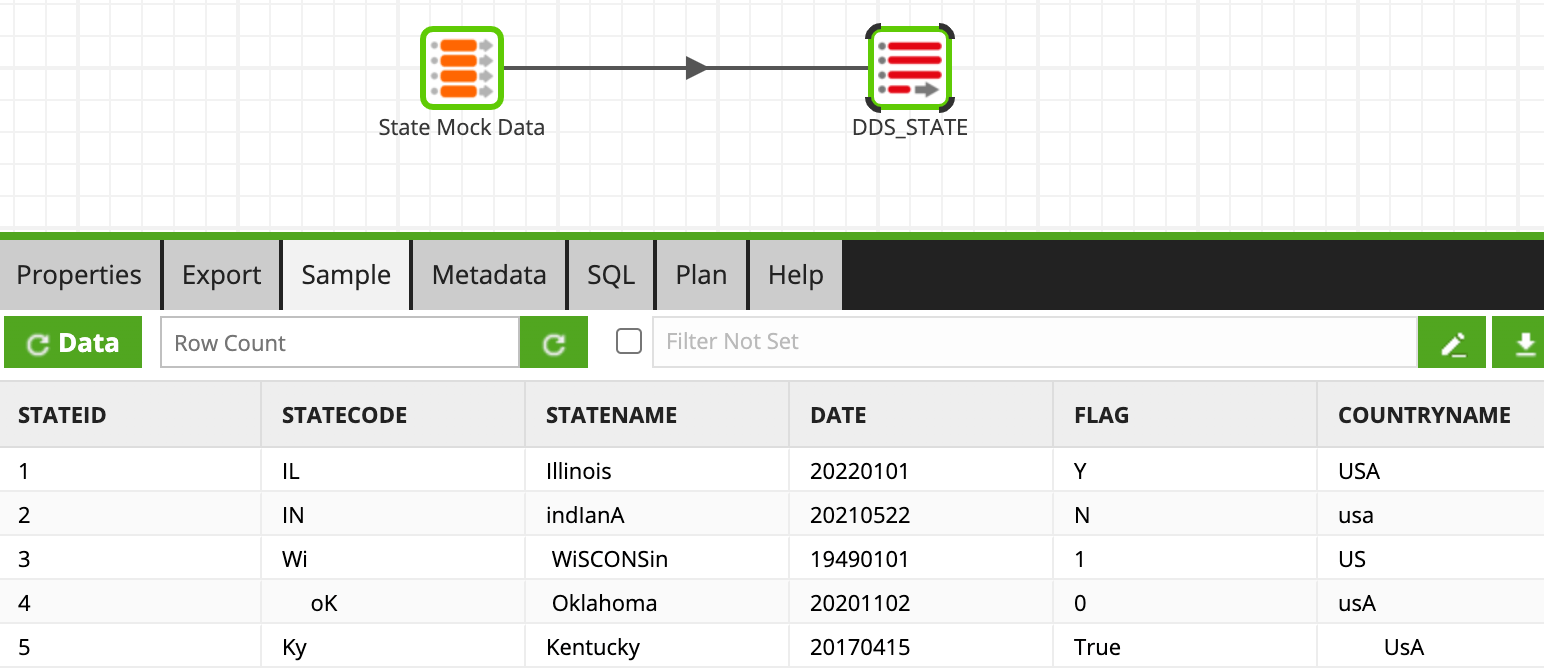
Populate Data Standardization Rules
The dynamic data standardization framework (DDS) utilizes metadata tables in the cloud data platform that hold the standardization syntax that should be applied at run time. For this framework, we have two sets of rules that can be applied, explicit rules or default rules.
- Explicit Rules: This table holds standardization rules at the table/column type/column pattern level. The rules found in this table apply when a row exists for a table, and the column type + column pattern (column name contains the value found in column_pattern) are found in this table. I.e. if a text column named USER_CODE exists in DDS_STATE table, then the following standardization rule would be applied at run time: UPPER(NVL(TRIM(USER_CODE),' '))
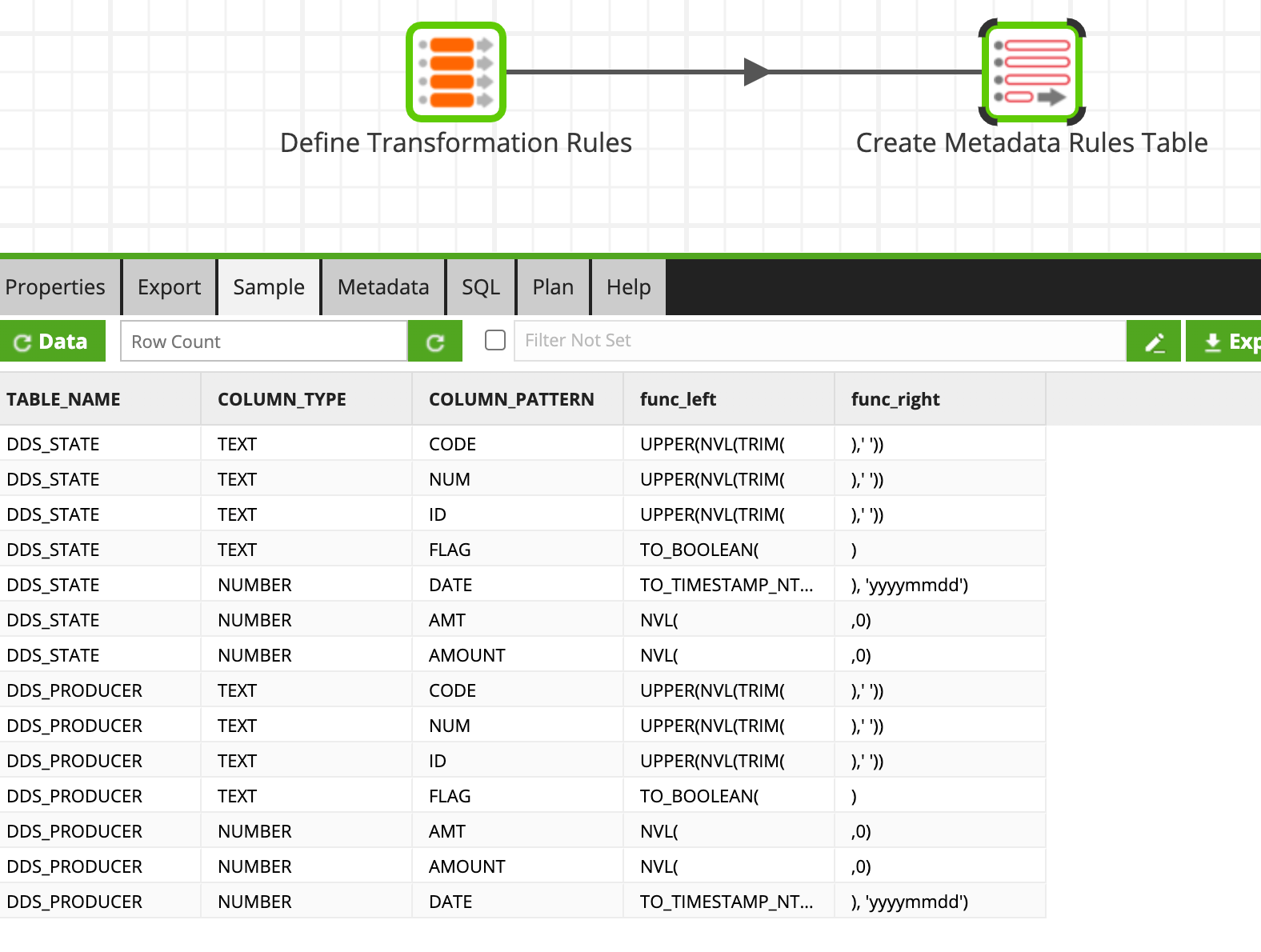
- Default Rules: If no explicit rules apply to the data being processed through this framework, then a default rule will be applied if it meets the criteria.
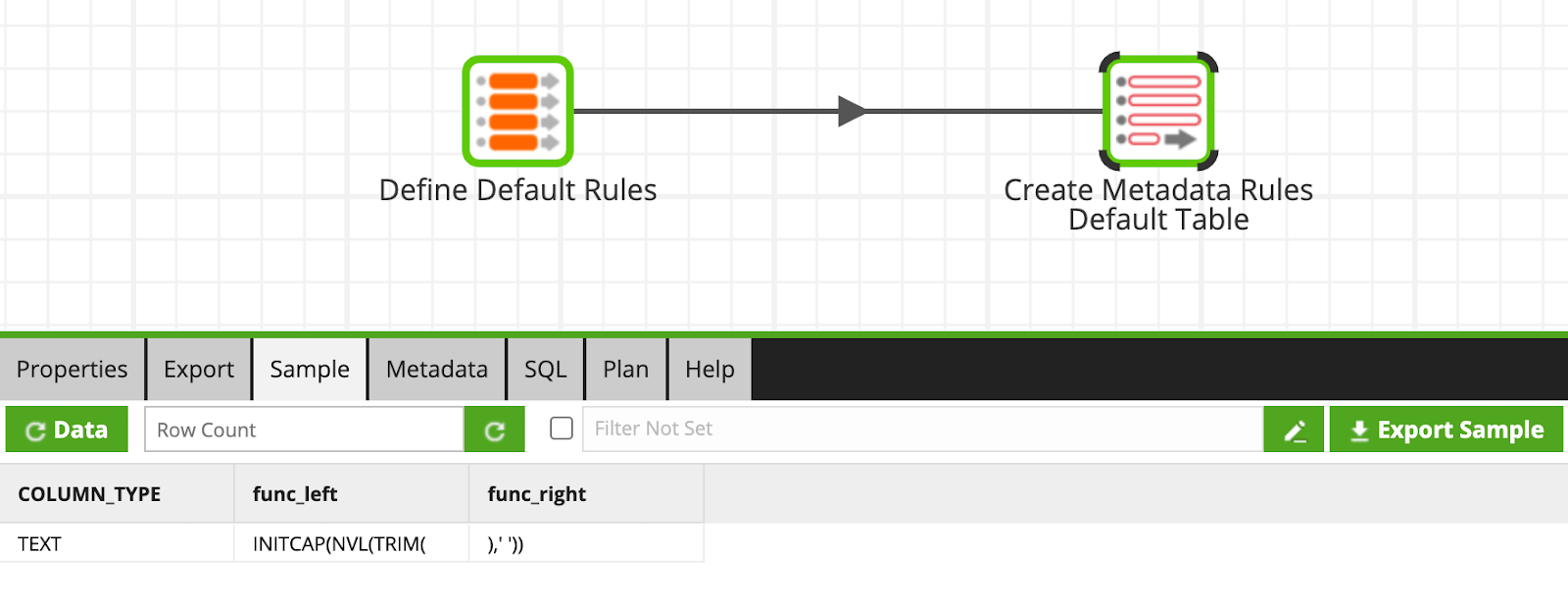
Load Appropriate Standardization Rules into Variable
The Formulate Dynamic Scripts transformation is where the DDS framework decides which rules will be applied to the column at run time. It checks for explicit table rules in the first join, then checks for default rules in the next join, and decides the calculation that should be applied. These calculations are loaded into a temporary metadata table and subsequently loaded into a grid variable named gv_calculations. 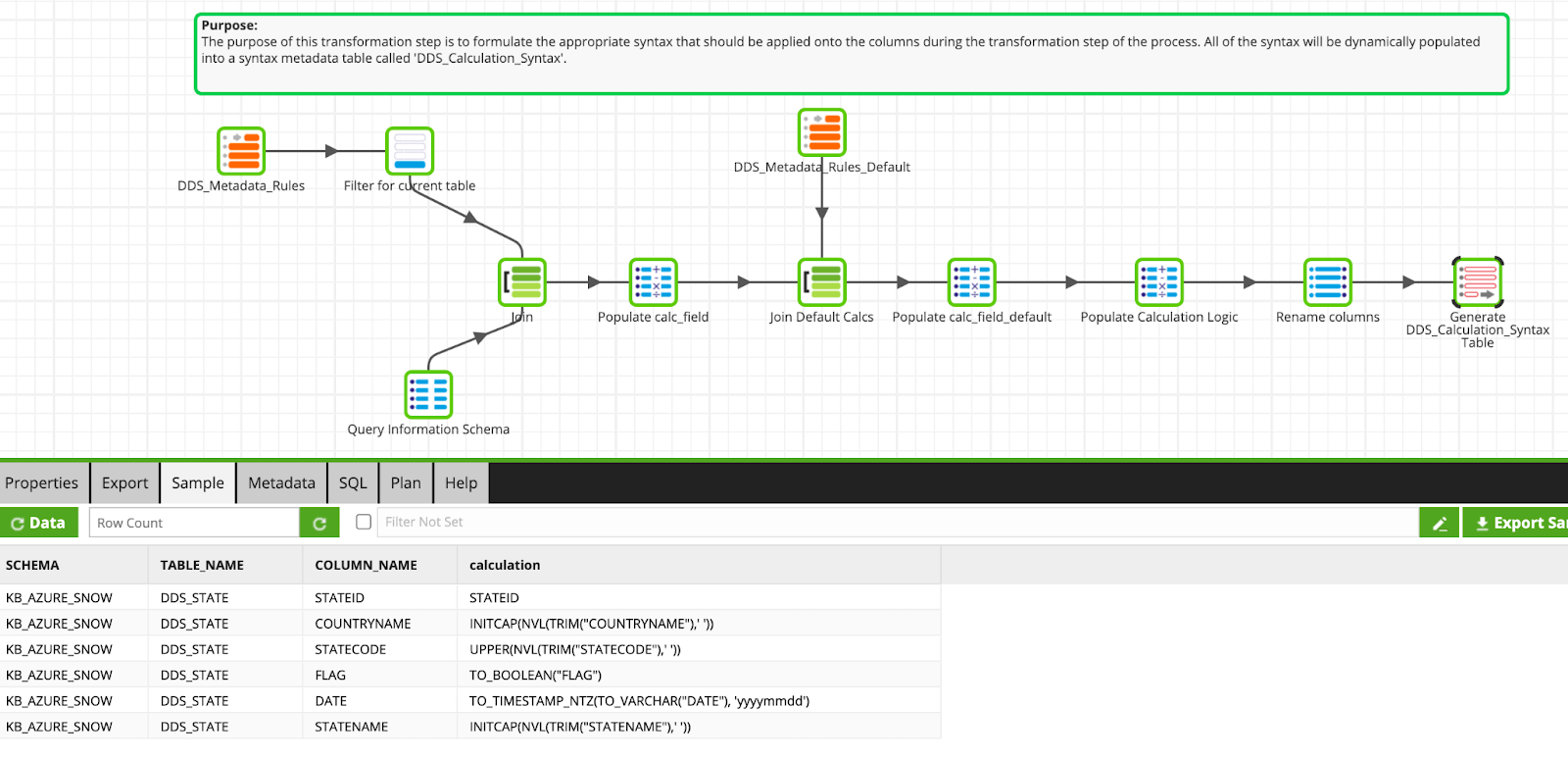
Apply calculations and load silver layer (_silver) tables
METL allows you to store calculations in grid variables and apply them in the calculator component. We leverage that functionality in the Apply Transformation job to standardize the data with the rules that were loaded in the previous step. The resulting data is loaded into a new table with a _silver suffix. 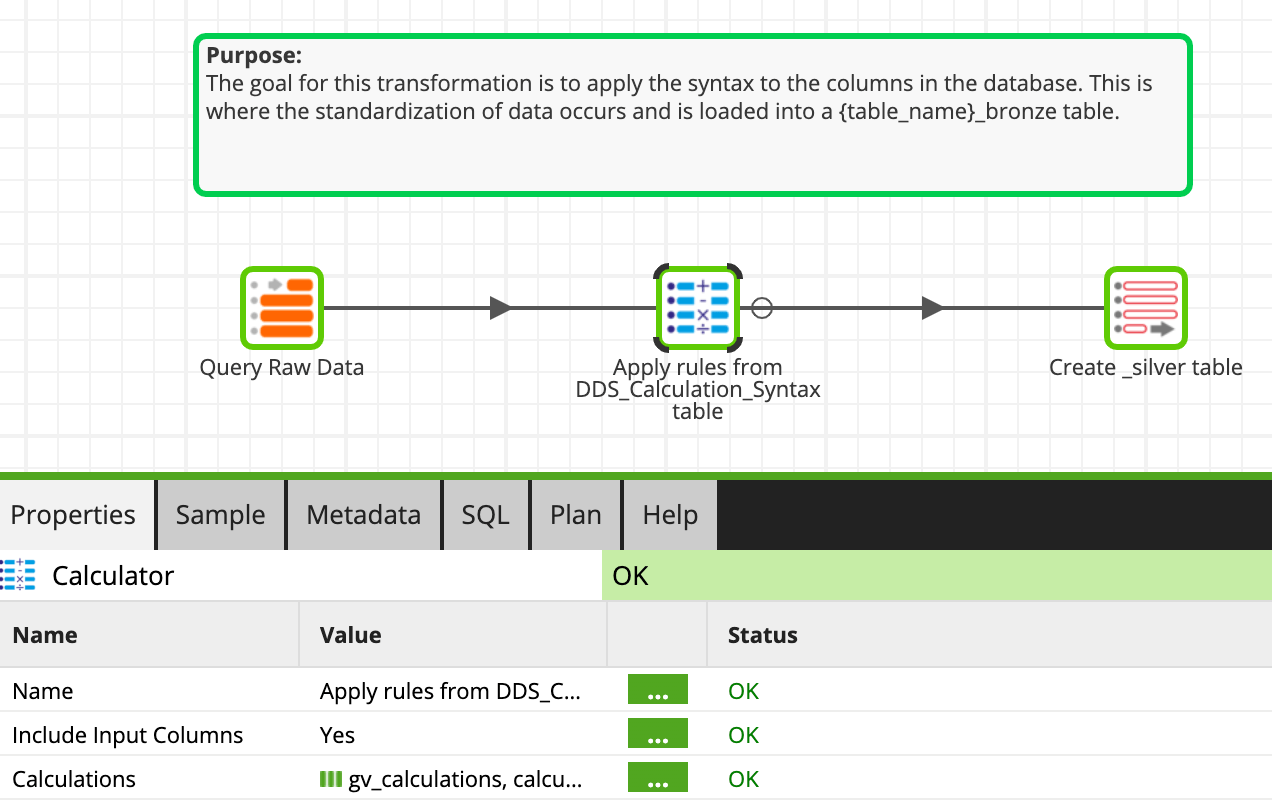
Conditional secondary standardization to populate Gold layer (_gold) tables
This framework also demonstrates further standardization rules (business level cleanse to presentation level cleanse). For this step, we first check if the table that we are running the process on has a timestamp column, and if so, sets any of the dates that are before 1950-01-01 to NULL. If no date column exists, then the data just moves as is to a new table to a table with a _gold prefix. 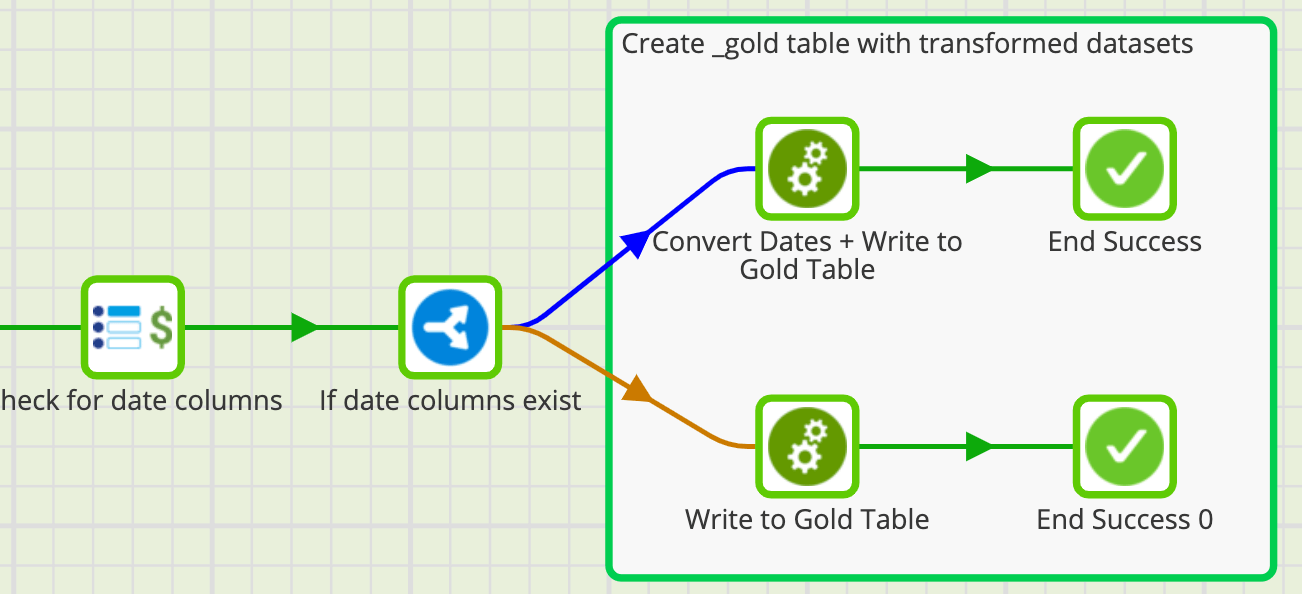
Results
After the process loops over the list of tables, you are able to see the journey of the data in the Dynamic Data Standardization - Validation job. Notice the changes that happen as the data moves from raw (bronze) to silver and gold layers. As you can see, there is still a final standardization that can be applied to fix some of the country names. We will leave that door open for you to write another gold transformation that uses fuzzy match functions to standardize the values. 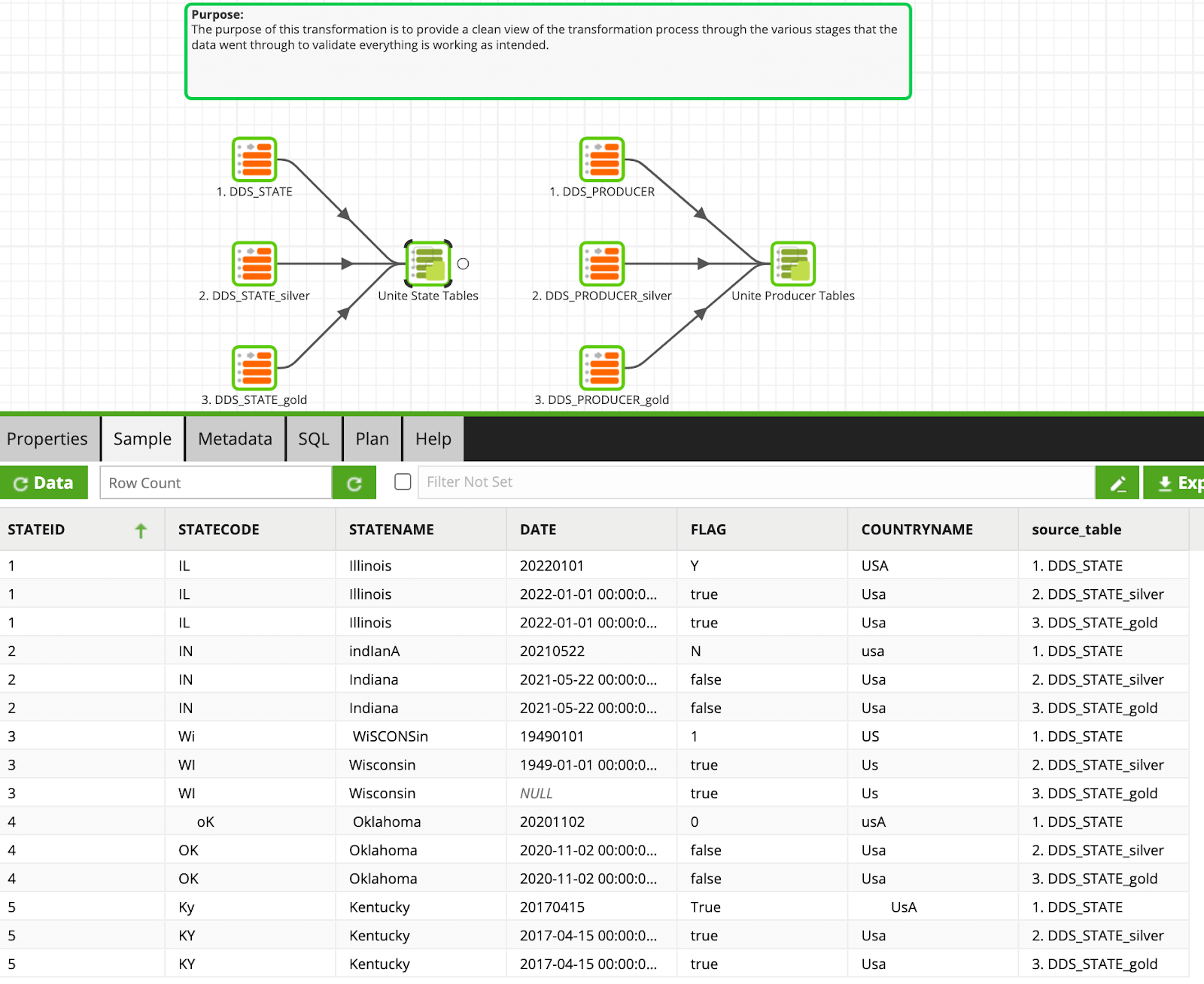 By having a data standardization framework in place within METL, you can ensure that all data flowing through to your CDP are having common rules applied. This makes your data more trustworthy, accurate, and clean for your end users/BI applications.
By having a data standardization framework in place within METL, you can ensure that all data flowing through to your CDP are having common rules applied. This makes your data more trustworthy, accurate, and clean for your end users/BI applications.
You also benefit from a lot of time saved since the framework is flexible (i.e. you can add new tables/rules as you deem fit within the metadata tables), so you are able to get actionable insights at a much quicker pace than ‘hand-scrubbing’ the data manually.
Download the job from the Matillion Exchange:
Andreu Pintado
Featured Resources
Custom Connector for Public Statistics (Police API)
A demonstration of the practical steps for setting up components, manipulating and validating data, creating and scheduling ...
BlogMastering Git At Matillion. An In-Depth Guide To Merging
Merging in Git is the process of integrating changes from one branch into another. Merging is the backbone of collaboration in ...
BlogWhat is an API?
What is an API? An API is an application programming interface that is a way for two or more computer programs or components ...
Share: