- Blog
- 04.03.2024
- Data Productivity Cloud 101, Data Fundamentals
Be Productive with Dynamic Pipelines in Matillion

This blog, authored by a Matillion Commerical Senior Sales Engineer, sheds light on the power of creating “reusable” components and pipelines through the use of Variables. The first use of this is usually to answer the question, “What if I have 100 database tables I want to move into the data warehouse? Do I have to configure each table manually?” The good news is, they do not! Even better news is that the same techniques can be applied to SaaS applications like Salesforce or Netsuite or any of the 100s of others you might have. This is not limited to databases.
Let’s say we have a couple of databases, and we want to make sure we copy any tables from named schemas into Snowflake (or the data warehouse of your choice).
So long as we know the address/url of the databases, we know the name of the schema we want to get data from, and we have some login details for access, we can set up a reusable pipeline that we can pass just the required information into.
The “worker” job
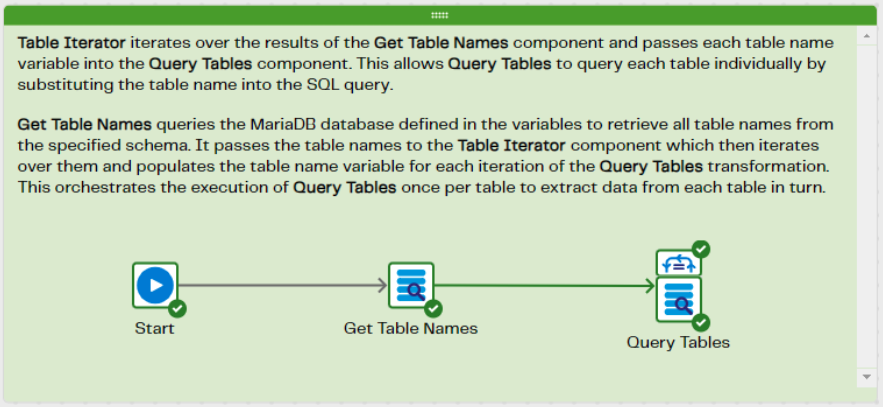
This job will run 2 different Queries.
The first Query will connect to the data source, retrieve a list of tables in a specified Schema, and save the result into a table in the data warehouse. This process makes use of a SQL query formatted similarly to the one below.
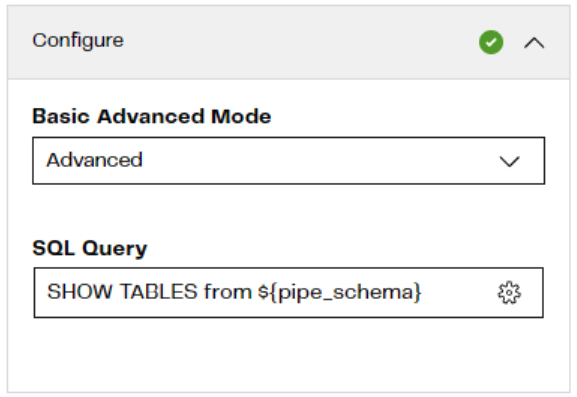
You’ll note the text ${pipe_schema}. This is a Variable containing the name of a schema. The value will be passed in from a parent job later.
(The exact syntax of the query will depend on the type of data source you are connecting to. I find asking ChatGPT for the query syntax to be pretty accurate).
The 2nd Query, will use the table names discovered earlier, and retrieve all the data from them.
To do this, the 2nd Query has a Table Iterator attached to the Database Query component. The Table iterator reads from a column in a specified table (where we stored all the table names) and maps the column to the variable we want to use.


The 2nd Database Query component, would then have a query similar to the one below.

The table being read from in the query is determined by the value passed in from the iterator. The schema name is the same as the name used to find the table names earlier.
The table name variable will typically be used in the destination table name as well.

With these two database queries, we can pull back data from all the tables in a specified database and schema. But, where are all the other variable details coming from for Schema and “prefix”?
These exist if we want to use this pipeline for multiple databases and schemas. Essentially, we’ve created a reusable pipeline that will get all the data from all the tables for a database and schema that we pass into the pipeline.
This is done with a parent job.
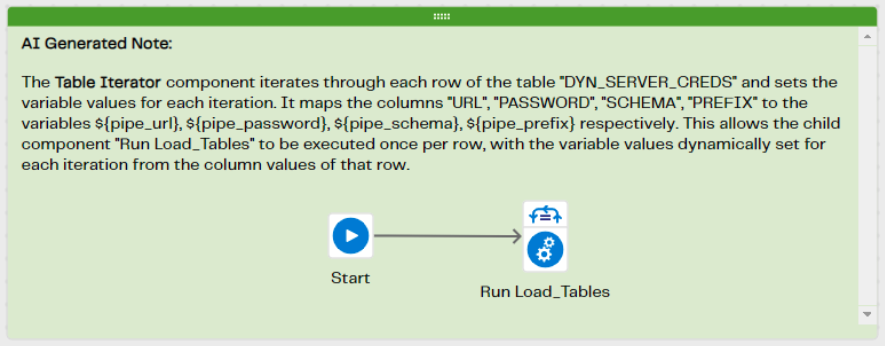
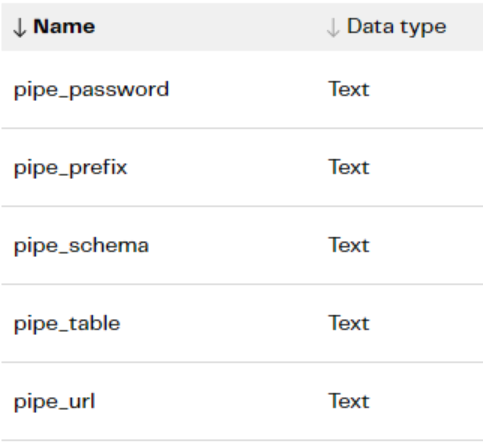
In this parent job, the iterator reads from a table and holds just a few key pieces of information. Secret name for a password in the password safe, database URL and schema name and a “prefix” that we want to add to the table name with it’s created. This will enable us to identify which database and schema the table will have come from. The Parent pipeline will, therefore, have Variables such as:
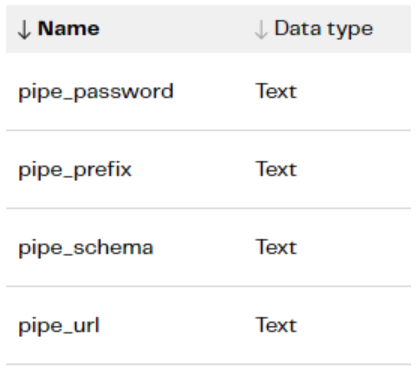
The iterator attached to the Child pipeline will, therefore, read a table with those pieces of information and map the columns to the variables:

In the child pipeline, we need entries for all these variables and the table name (that we discussed finding earlier)
How do the values get from the Parent pipeline to the Child pipeline?
This is done in the properties of the “Run Orchestration” component in the Parent pipeline.

Here, the values in “Variable” are the variables held in the Child job. The “Value” is either a fixed value to be passed into the Child Pipeline, or, as in this case, the name of a variable in the Parent job.
The child job, just needs all the locations where the secret name/url/prefix etc is required, to have the correct entry for the appropriate variable. E.g.

So once configured, all we need to maintain is a table in the cloud data warehouse, with a few key pieces of information, that we pass into a reusable pipeline. This allows us to maintain a few simple components but potentially move hundreds or thousands of tables.
Next steps
This article has described a full load pattern. Refer to this article on the Matillion Exchange for a deeper understanding of full-load data replication.
As a next step, you could change this to an incremental load pattern instead, by just taking the latest updated data from each table.
Matillion's Data Productivity Cloud contains all the data loading, data orchestration, and data transformation tools that you need to template these kinds of sophisticated, multi-step data processing patterns. Sign up at the Matillion Hub to start a free trial.
Phillip Bell
Commercial Senior Sales Engineer
Featured Resources
Data Productivity Cloud Now Offering Stronger Integrations For Databricks Users
Matillions Data Productivity Cloud on Databricks empowers data teams built around Databricks to be more productive and ...
BlogWhat Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
Share: