- Blog
- 05.03.2024
- Data Fundamentals, Data Productivity Cloud 101
Enabling DataOps With Data Productivity Language

“The goal of DataOps is to deliver value faster by creating predictable delivery and change management of data, data models, and related artifacts.” [Gartner glossary]
When designing Matillion Data Productivity Cloud, the foundation was Git. Every pipeline created in DPC is stored in a Git repository. The files stored in the repository are in a human-readable format we’ve called Data Productivity Language (DPL). We started with Git as a foundation and created DPL because we knew our customers wanted to implement DataOps processes.
Data Warehouse Automation
Scenario: A company regularly creates standardized projects. Each project has its own website with underlying databases and exists for a limited time (~6 months). The projects are created via an automated process. To gain insights from all the projects, the data needs to be centralized in a data warehouse, and the pipelines to do this should be part of the automated process that creates the project databases.
How can Matillion assist?
To start, Matillion Data Productivity Cloud is an ELT solution designed to orchestrate getting data from multiple data sources into a Cloud Data Warehouse and running transformations against that data to integrate it.
The key part for the use case. The pipelines must be created automatically along with the campaign. Traditionally, a Matillion data pipeline would be created by a user using the UI. But now, we want to create a pipeline as part of the DevOps/DataOps style process, where pipelines can be created/edited programmatically as part of a wider implementation. This is where the Data Pipeline Language (DPL) comes into play.
The Matillion Data Pipeline Language (DPL)
Based on YAML format files, DPL provides human-readable files that define Matillion pipelines. For instance, the two screenshots here represent the same simple Orchestration job with a single Salesforce connector and all its settings.
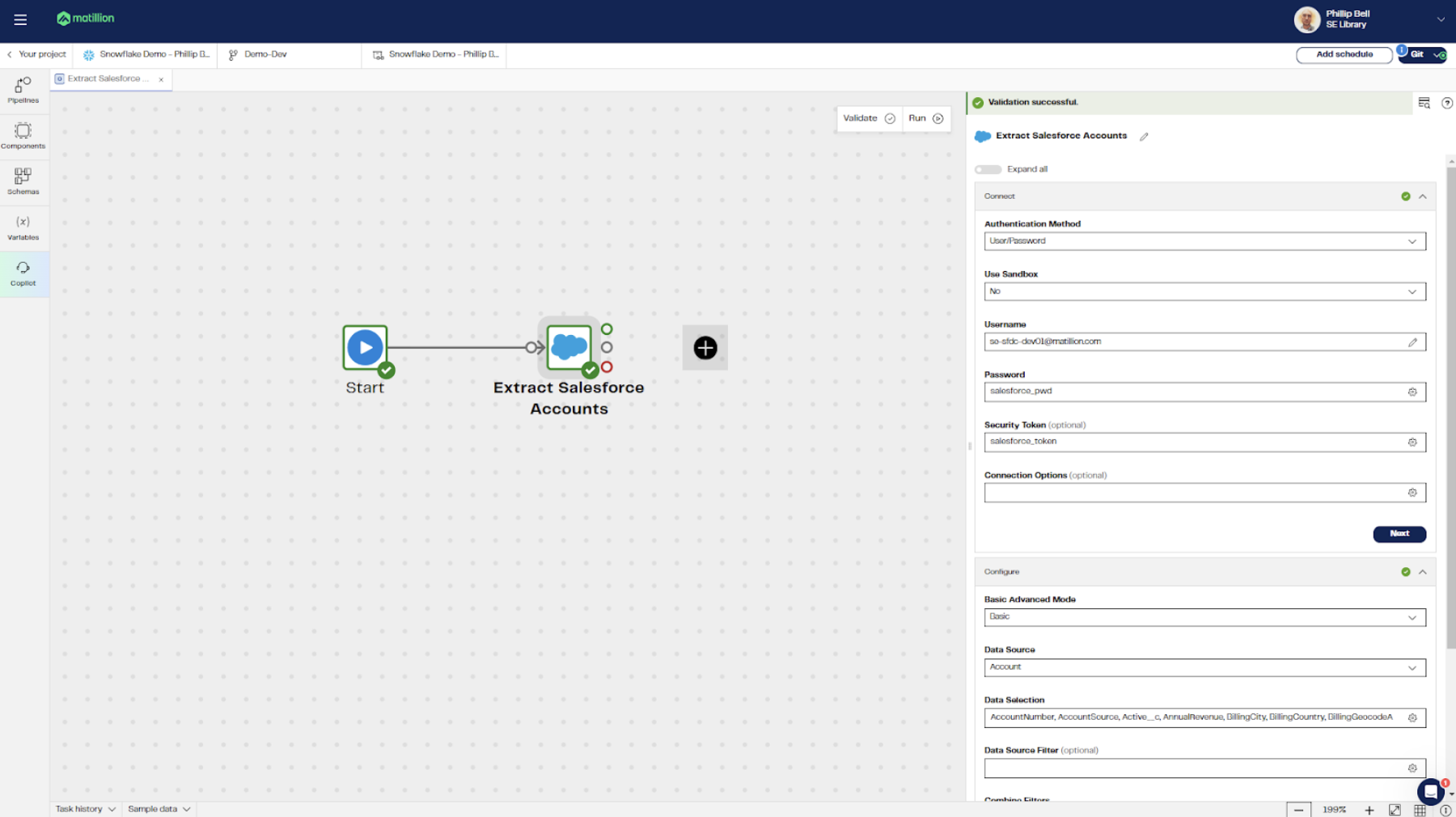

DataOps with Matillion
If, for instance, the username needed to be changed, we could use the Matillion UI. Alternatively—and more open to automation—we could open the pipeline in git and edit the username there. The same applies for any other settings or parameters. You could even add new components to a pipeline directly in the DPL file.
Given the simple to understand and edit DPL files, the solution to our scenario should be relatively straightforward.
- Within the Matillion Designer interface, create a folder and a series of “default” example jobs
- When a new Campaign is required, the automated process creates the required databases for the campaign and runs the following automated steps:
- Access the organization's Matillion git repository
- Create a new appropriately named folder
- Copy the sample jobs into there
- Change details in the pipelines such as the user, password name, database name etc, to match the details of the new campaign.
- Test run the new pipelines in Matillion (which could be automated as part of the DevOps process)
- Schedule the pipeline
Summary
I’m not suggesting this automation use case is the only use for DPL.
Of course, you might prefer to build/edit pipelines using DPL. That’s all part of what makes Matillion “Everyone Ready”. Work done in DPL can be reviewed/used by users who prefer to work in the Low-Code UI. Working on the same project in the ways each team member prefers.
What’s not to like?!
To get started with enabling DataOps in Matillion’s Data Productivity, try for free!
Phillip Bell
Commercial Senior Sales Engineer
Featured Resources
Yes, Matillion Democratizes AI for Snowflake Users
Matillion is excited to announce our availability and support for ...
Blog5 Tips for Implementing Slowly Changing Dimensions with Matillion and dbt
What does it take to excel in the world of data engineering and ...
BlogThe Business Value Artificial Intelligence Adds to Data Pipelines
As Artificial Intelligence (AI) continues to grow into a more and ...
Share: