Data Engineer’s Guide to AI Prompt Engineering - 3

Building AI-Powered Data Pipelines: Enrichment from Open Sources and Classification
Hi, again — it’s Julian Wiffen, Director of Data Science for the Product team at Matillion. In the previous installment of Data Engineer’s Guide to AI Prompt Engineering, we discussed how LLMs also enable a data engineer to work with large blocks of unstructured data without the need to use hand coding and complex natural language processes.
In this blog, we are going to cover some more ways a LLM can be used within a data pipeline, generating analytical insights from some free text based data.
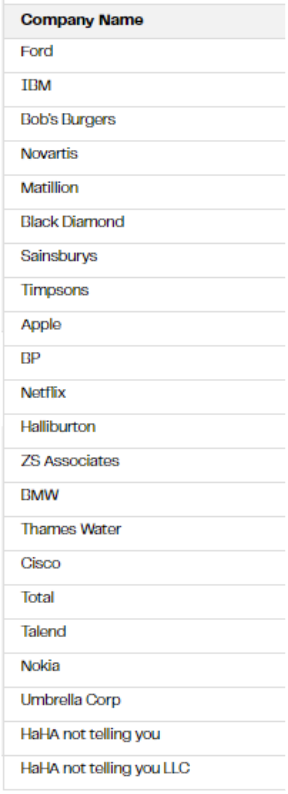
In this example, we imagine some of our marketing and sales teams have returned from an event with details of attendees that stopped by our booth. Let’s say we want to understand the type of companies that have people attending this particular conference, to better target our content in future years. We would likely have a list of people’s names along with their self-reported company name used when they registered for the conference. In the interests of privacy we have arbitrarily created a list of companies rather than using real data.
Note: This a hypothetical exercise to explore the capabilities of an LLM — we make no claim to have any particular relationship with the companies named below, but some real company names are used to test the OpenAI model’s ability to give an accurate description of them based on its knowledge of web scraped data.
We know some delegates are not altogether serious when filling out their company details so have added a few made up names to the list.
Using the prompt component on the Data Productivity Cloud we can take that list of company names and ask the LLM (OpenAI’s GPT4 in this case) to enrich the entries with general knowledge:
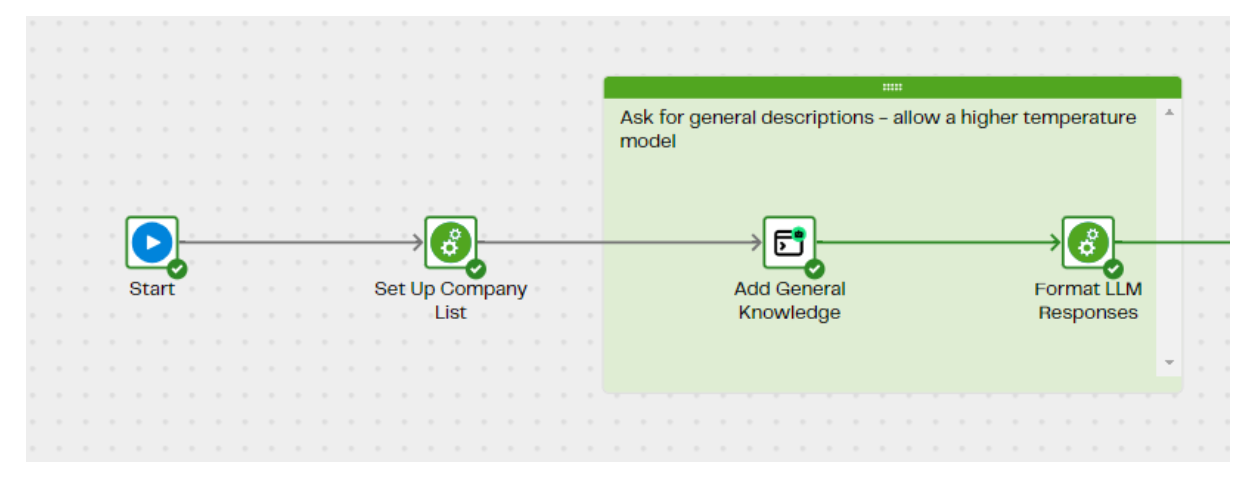
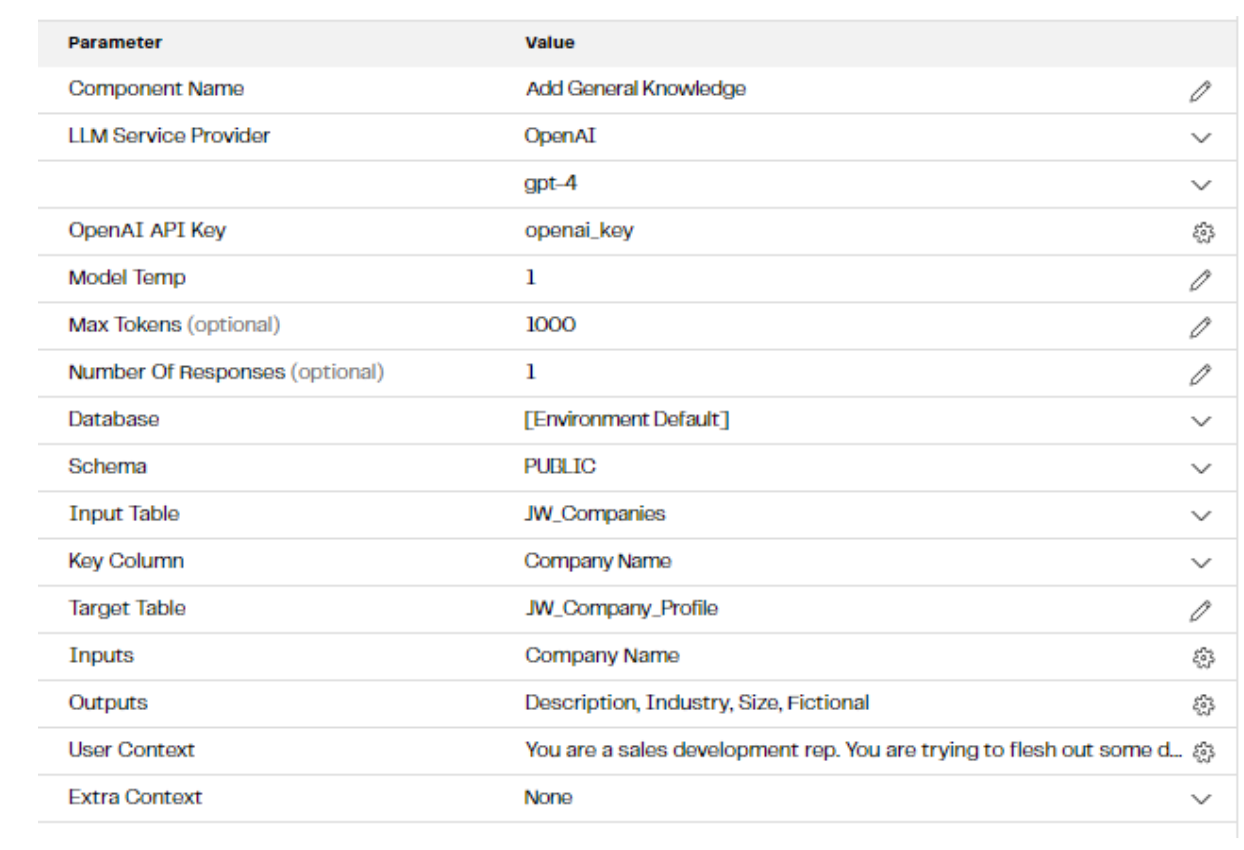
In the Add General Knowledge step, we create a prompt for each line of data in the table, concatenating the company name field to a question built up from a user context field to give the model general background information and then a list of specific questions we want it to answer.
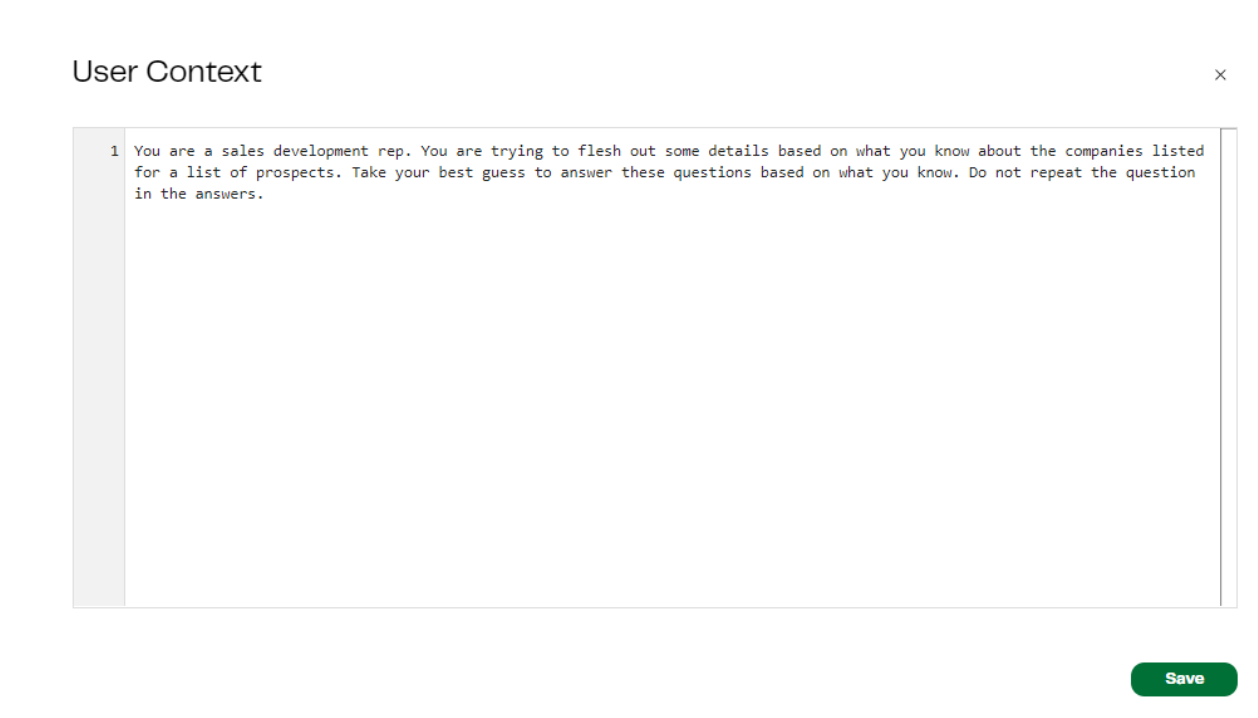
User Context: You are a sales development rep. You are trying to flesh out some details based on what you know about the companies listed for a list of prospects. Take your best guess to answer these questions based on what you know. Do not repeat the question in the answers.
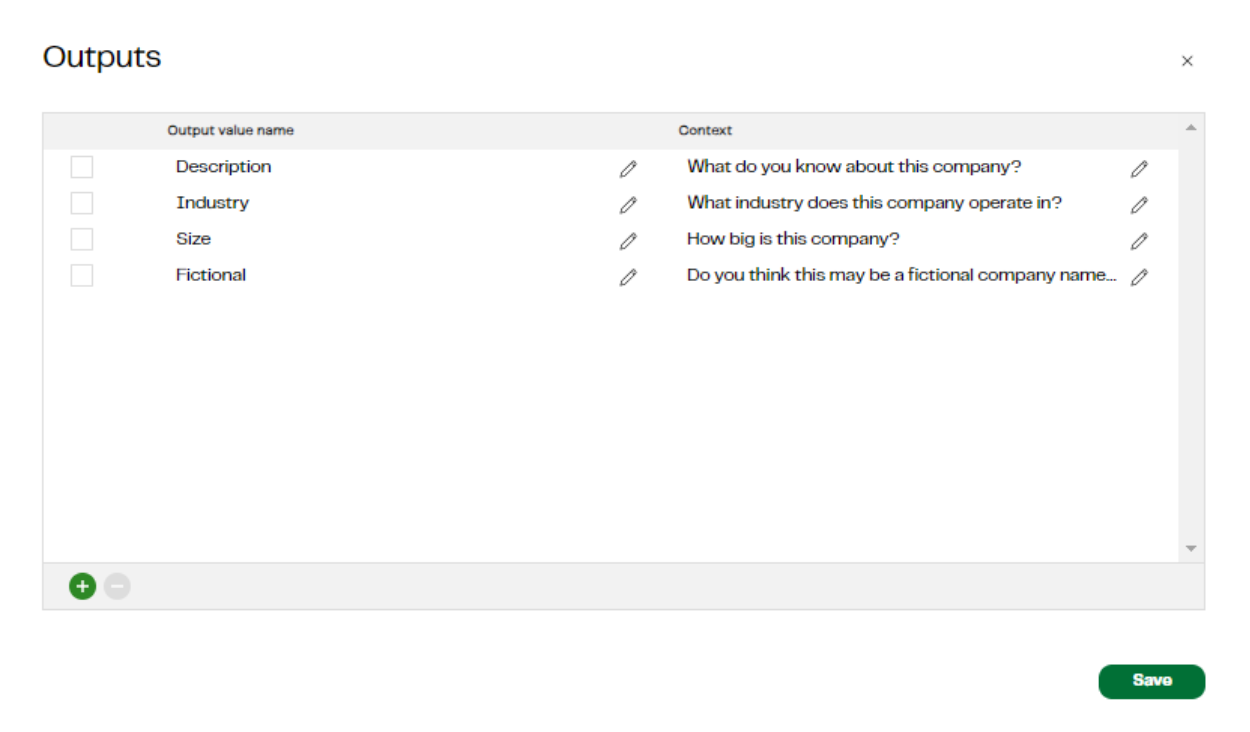
- Description: What do you know about this company?
- Industry: What industry does this company operate in?
- Size: How big is this company?
- Fictional: Do you think this may be a fictional company name ?
In the background our prompt component translates these details into the following prompt that it passes to GPT4:
context prompt: You are a sales development rep. You are trying to flesh out some details based on what you know about the companies listed for a list of prospects. Take your best guess to answer these questions based on what you know. Do not repeat the question in the answers.
data object: {"Company Name":"Ford"}
output format: {"Description":"What do you know about this company?","Industry":"What industry does this company operate in?","Size":"How big is this company?","Fictional":"Do you think this may be a fictional company name ?"}
To which it responded with:
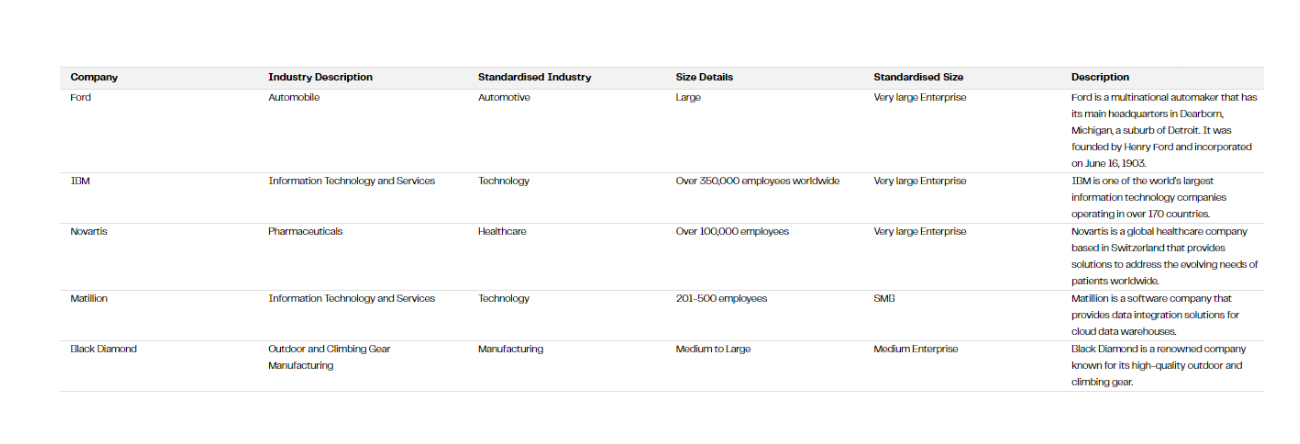
{"Description": "Ford is a multinational automaker that has its main headquarters in Dearborn, Michigan, a suburb of Detroit. It was founded by Henry Ford and incorporated on June 16, 1903.", "Industry": "Automobile", "Size": "Large", "Fictional": "No"}
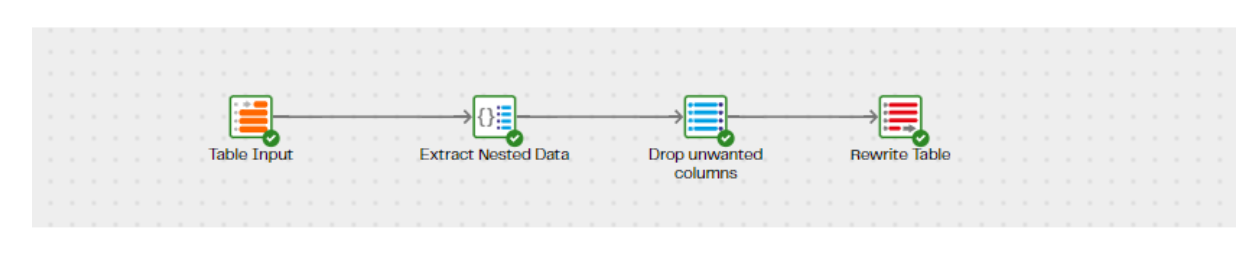
A similar process happens for each line in the table. Within the Data Productivity Cloud, we can use an extract nested data component to unpack the JSON format received into a more traditional table structure.
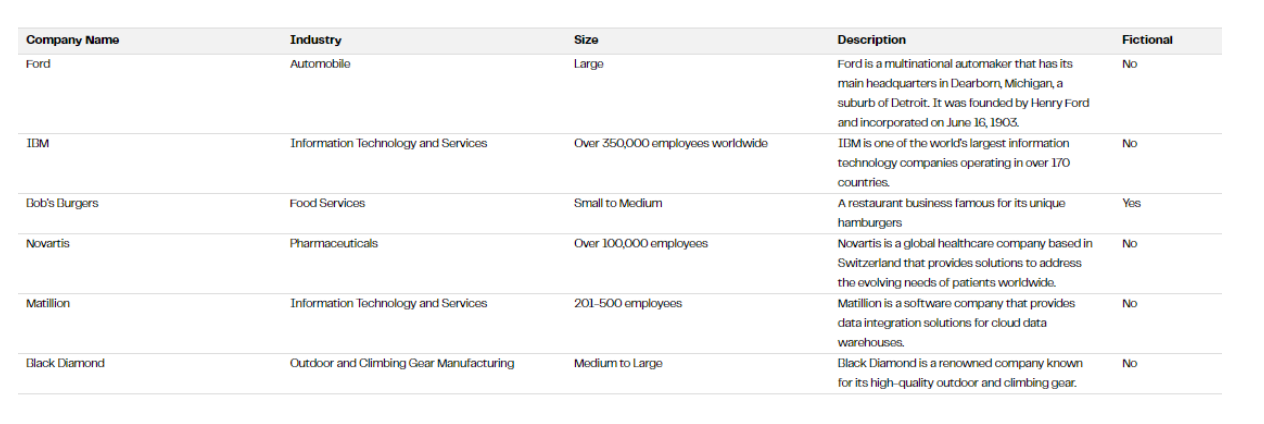
Looking at the first few rows of output we get from this, we see GPT4 has done a fairly sensible job to describe each company, bearing in mind its limitations of only being trained on web data up to 2021.
Looking down the table, it’s also done a good job of picking out the made-up names that we sprinkled into the list.
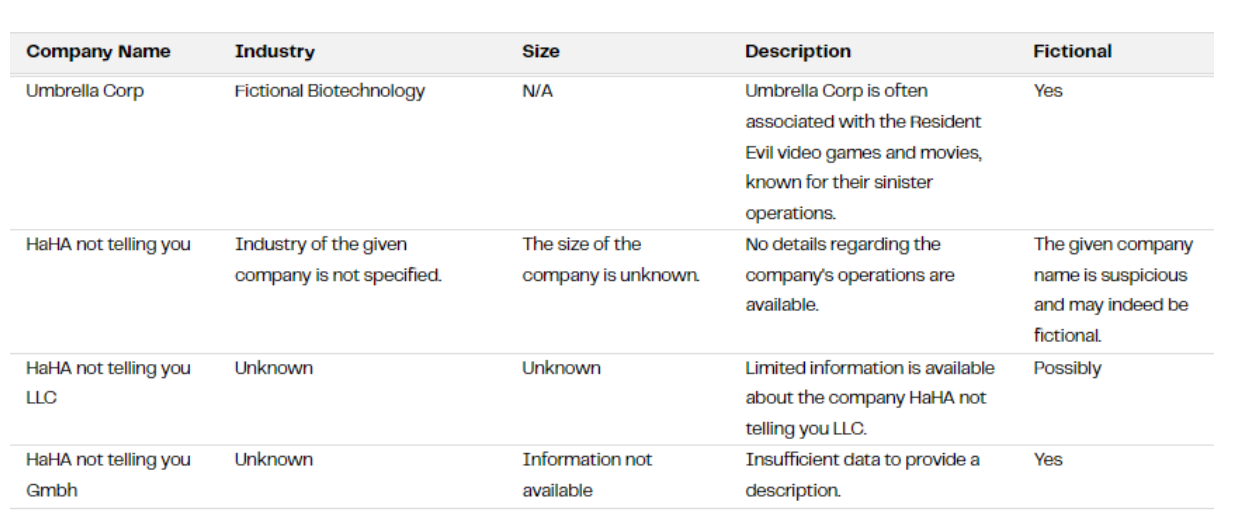
However, the responses we have here in all categories are still effectively free text — there is too much variation in them to use for any business intelligence purpose.
So we are going to add a second step, where we pass the answers from the first LLM query into a second prompt to ask for the size and industry to be standardised and to turn the question on if the model thinks it is a real company name into a simple yes or no question.
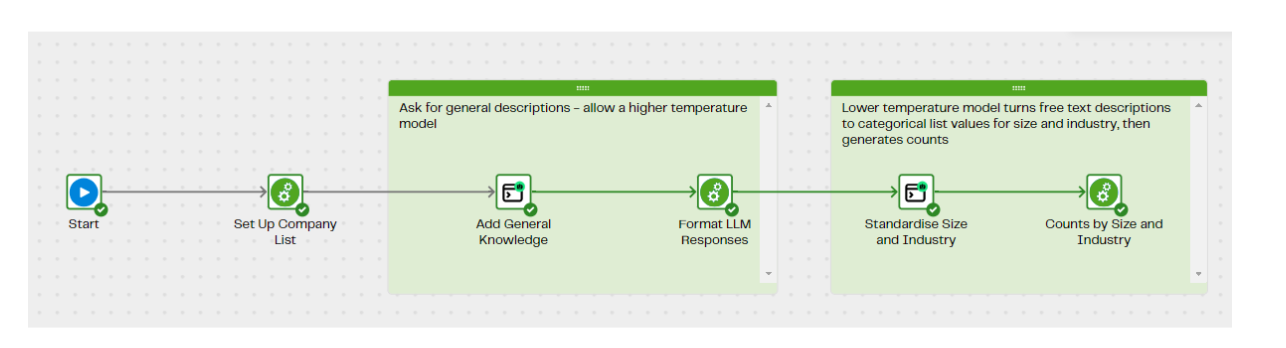
For the process of standardisation, we use a lower temperature setting compared to the first prompt. Temperature controls how creative can be and/or the level at which it can make assumptions and inferences. This process of allowing a higher setting on the first pass to prevent too literal a handling of the question and then a second pass to standardise the output allows us to get the best of both worlds.

We have the same User Context as before and are providing the outputs of the previous prompt (Industry, Size, Fictional) as inputs into this one.
The other specific questions we ask are:
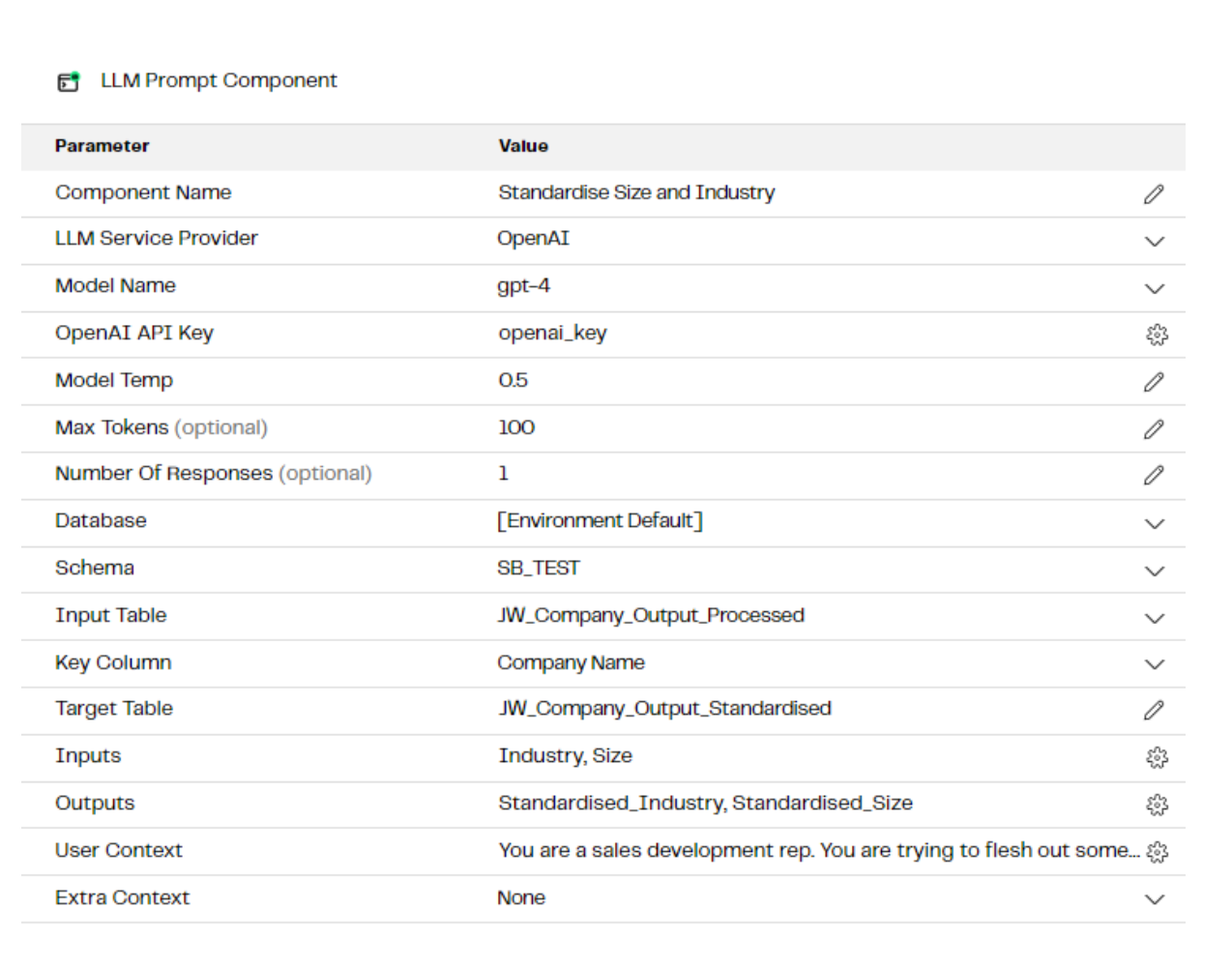
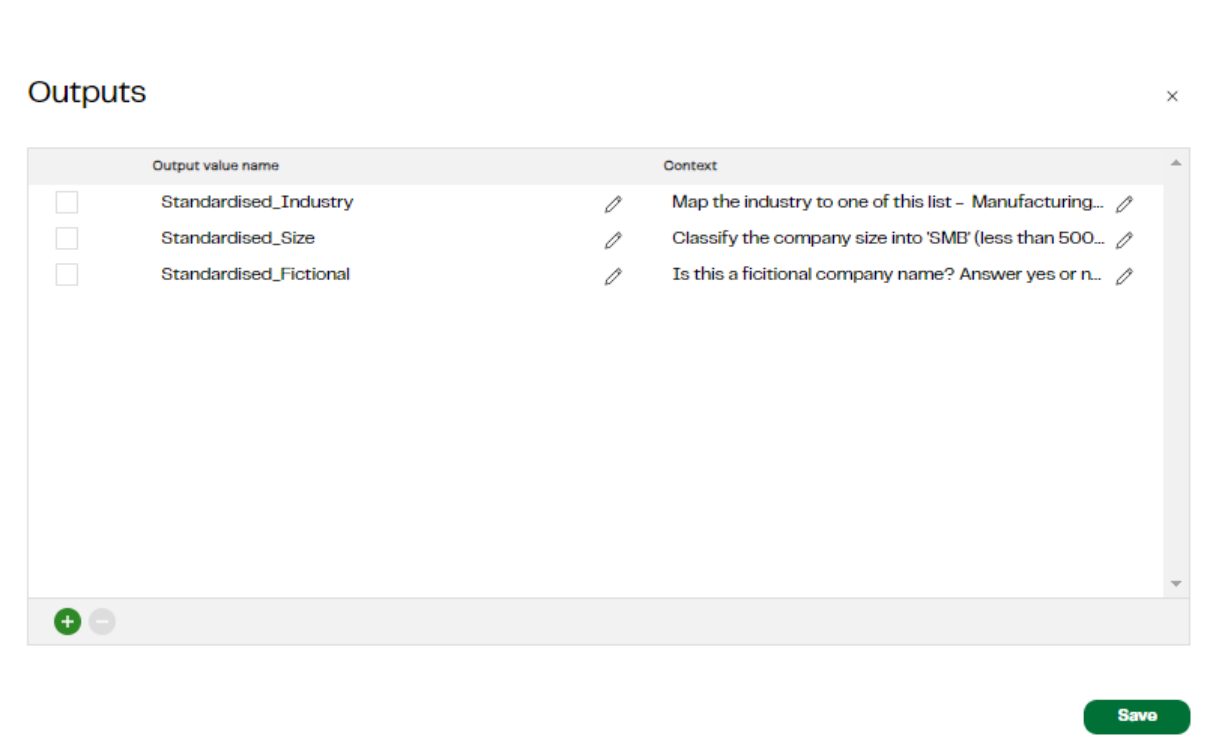
- Standardised Industry: Map the industry to one of this list - Manufacturing, Energy, Entertainment, Technology, Food, Retail, Automotive, Healthcare, Financial Services, Other. Give only one of those values as your answer.
- Standardised Size: Classify the company size into 'SMB' (less than 500 employees), 'Small Enterprise' (500 - 1000), 'Medium Enterprise' (1000-4999), 'Large Enterprise' (5000-25000),'Very large Enterprise' (25000+). Answer with the bucket name only
- Standardised Fictional: Is this a fictional company name? Answer yes or no only
So the prompt this generates and sends to the OpenAI API looks like this:
context prompt: You are a sales development rep. You are trying to flesh out some details based on what you know about the companies listed for a list of prospects. Take your best guess to answer these questions based on the input given. Do not repeat the question in the answers.
data object: {"Industry":"Automobile","Size":"Large","Fictional":"No"}
output format: {"Standardised_Industry":"Map the industry to one of this list - Manufacturing, Energy, Entertainment, Technology, Food, Retail, Automotive, Healthcare, Financial Services, Other. Give only one of those values as your answer.","Standardised_Size":"Classify the company size into 'SMB' (less than 500 employees), 'Small Enterprise' (500 - 1000), 'Medium Enterprise' (1000-4999), 'Large Enterprise' (5000-25000),'Very large Enterprise' (25000+). Answer with the bucket name only","Standardised_Fictional":"Is this a fictional company name? Answer yes or no only"}
As we found before with the job titles in the first blog, this approach of asking for a judgement call to map a descriptive value in the inputs to one from a list defined in the question is very handy when processing data for Business Intelligence purposes. We are turning free text data into structured, categorical values.
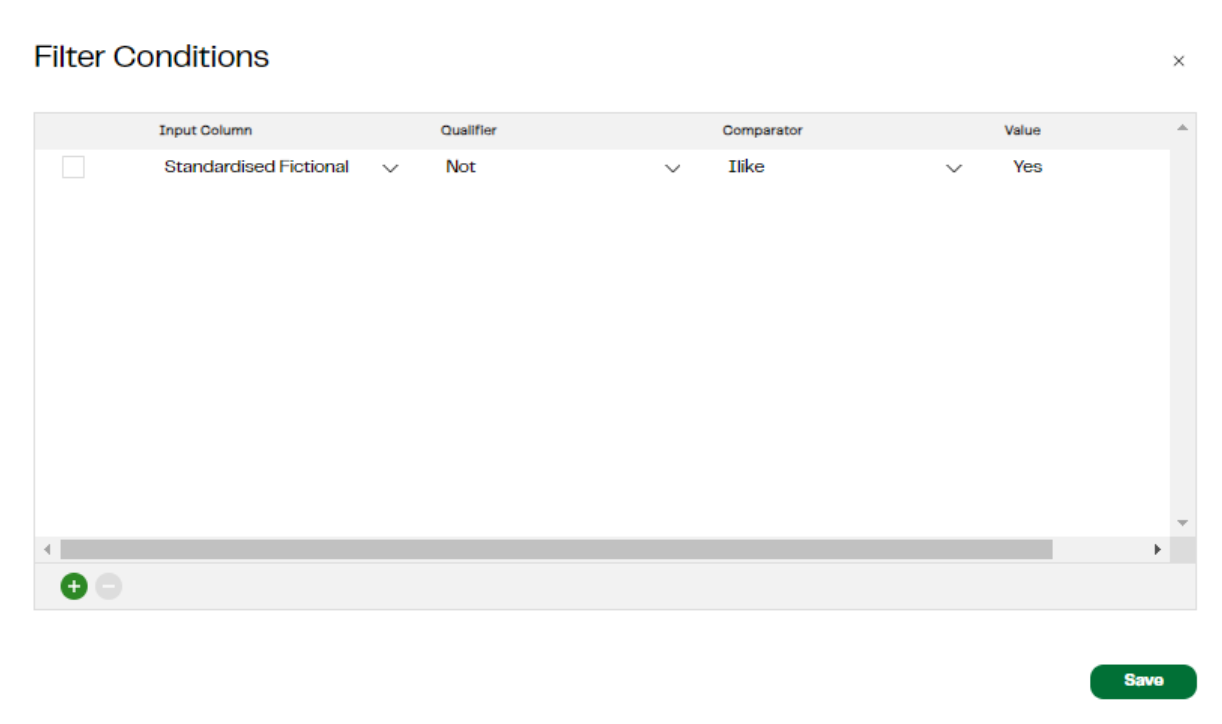
With the answer to ‘is this a fictional company name?’ Now in a ‘yes / no’ format, we can do a simple filter to ignore those companies that seem to be made up names. The answers we got from the LLM vary in case format: ‘No’, ‘No’, ‘yes’, ‘no’. It is however simple enough for us to build a case insensitive filter to remove those flagged as fictional.
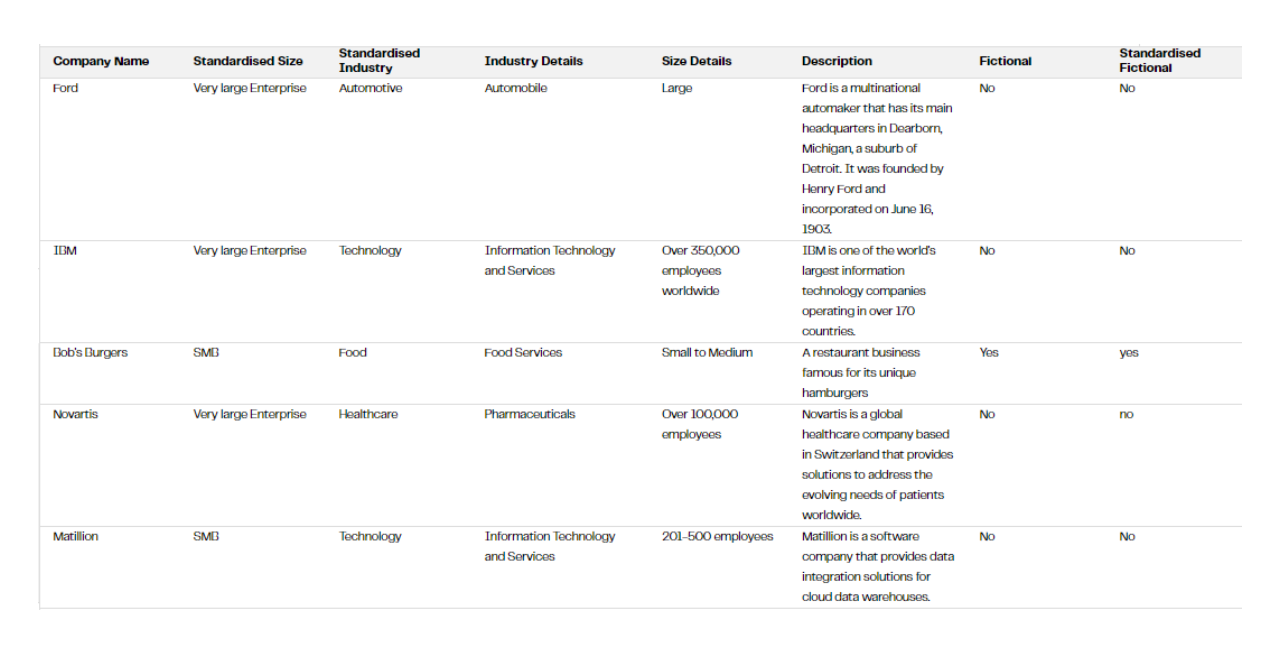
Applying the filter we now see just those companies that we believe are real names in the list, with categorical values for size and industry
Which is now suitable for us to aggregate — building at a count of company names grouped by these standardised industry labels and standardised sizes.
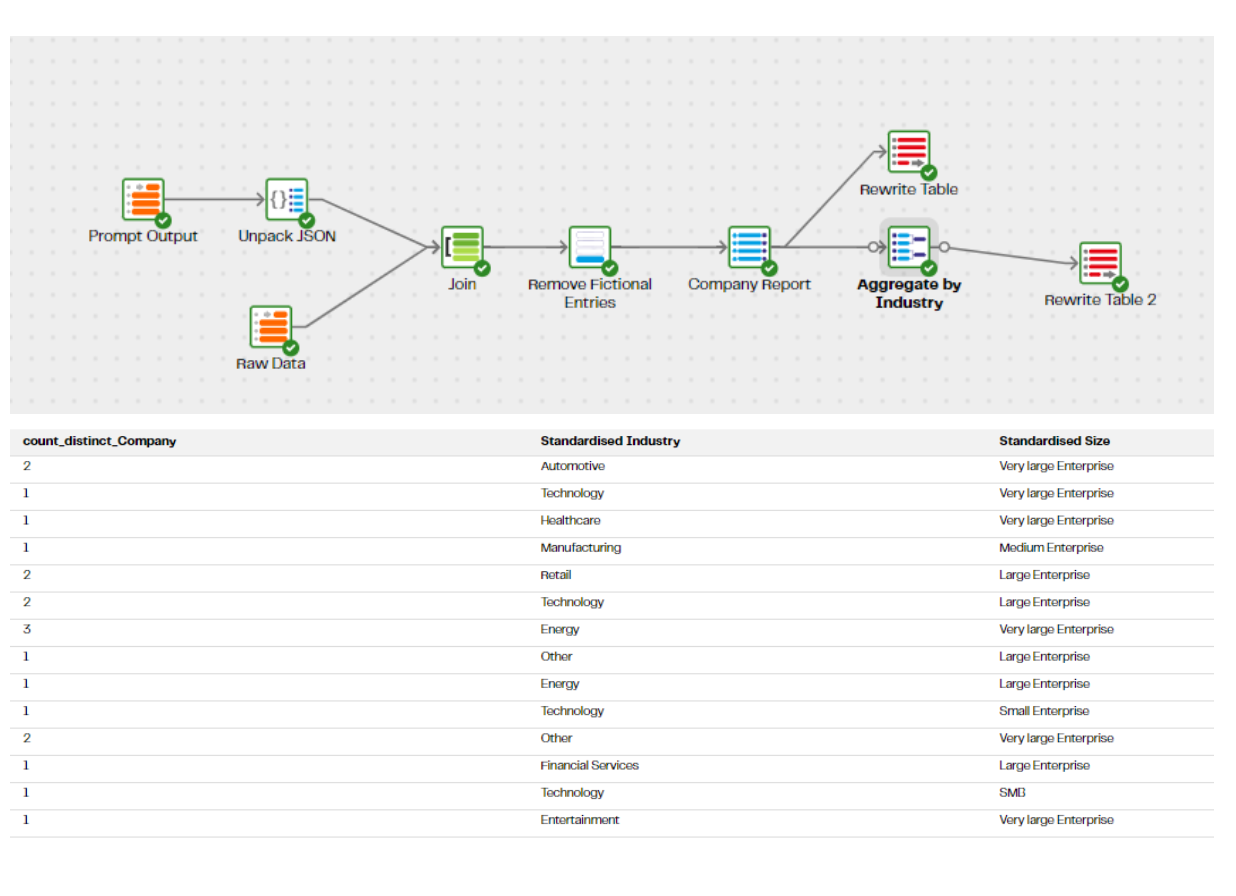
Our data is now ready to chart — this was produced in google sheets, but with the data in this format in Snowflake, it’s easily accessible to any number of visualisation tools.
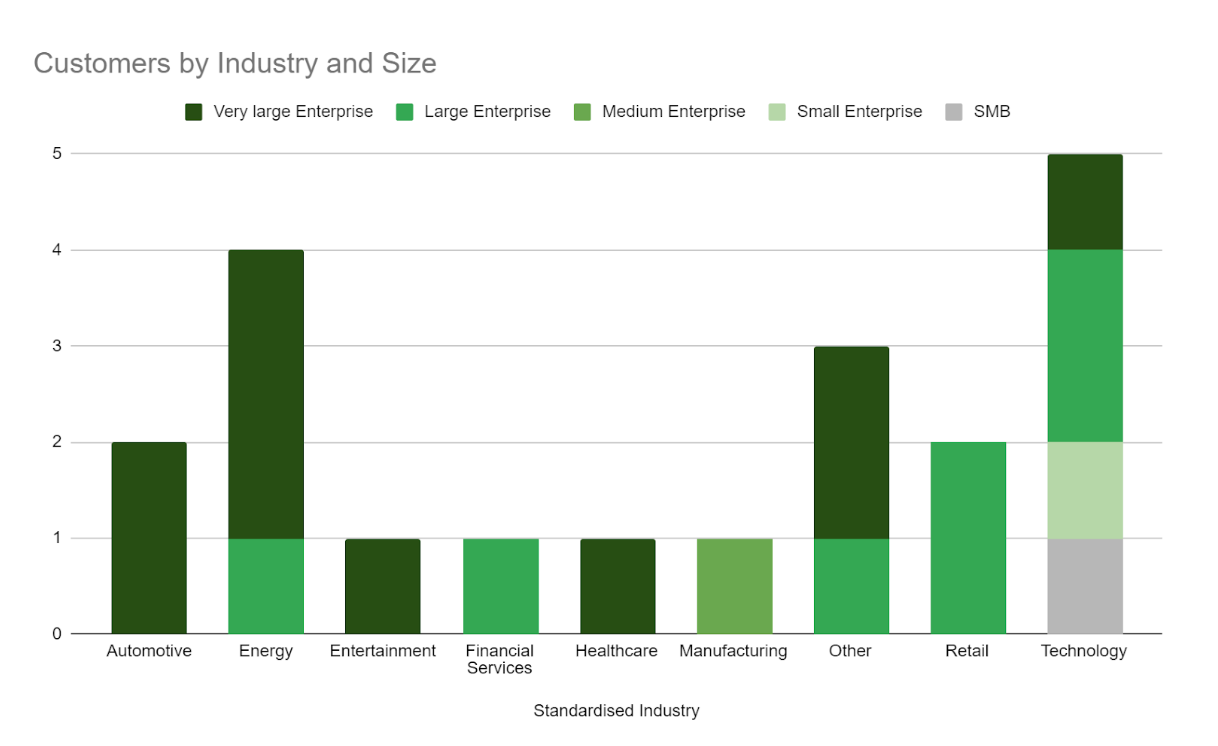
Based on this chart, we can see that our list of companies is primarily large or very large enterprises and that the energy and technology sectors predominate. If this was a real list from an event presumably, this would imply that next time we should bring plenty of content on use cases from our largest customers and targeting those sectors in particular with our messaging.
Data Enrichment and Classification: Harnessing the Power of Natural Language Configuration
What we have been able to do is the equivalent of having someone go through a list of company names, Google search each one, type a simple summary into the system along with making common sense judgement calls on the size, industry and if they think it's a genuine entry. This gives us a data enrichment and classification tool integrated into the heart of our data pipelines, a tool we can configure in natural language to ask a wide range of questions. It should prove a very flexible and powerful addition to the data engineer’s toolbox.
Want to see this action?
Join thousands of your peers from across the globe to become Enterprise Ready, Stack Ready, and AI Ready. Register for free today to secure your spot in the data-driven future and stay tuned for announcements about our stellar lineup of leaders, influencers, and data experts.

Julian Wiffen
Director of Data Science
Julian Wiffen, Director of Data Science for the Product team at Matillion, leads a dynamic team focused on leveraging machine learning to improve products and workflows. Collaborating with the CTO's office, they explore the potential of the latest breakthroughs in generative AI to transform data engineering and how Matillion can play a pivotal role in supporting the needs of those working with these cutting-edge AI models.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: