- Blog
- 10.15.2018
How to use Matillion ETL Grid Variables to Incrementally Load Insurance Claim Data
This blog describes how to build a single, generic method for data transformation (the T of ELT). You would use it to apply the newly-loaded changed data into its permanent home in a replicated table in the data warehouse.
One of the first things you’ll want to do with Matillion is copy data out from source systems into the target data warehouse. Every source system usually contains multiple tables, each one having a different set of columns.
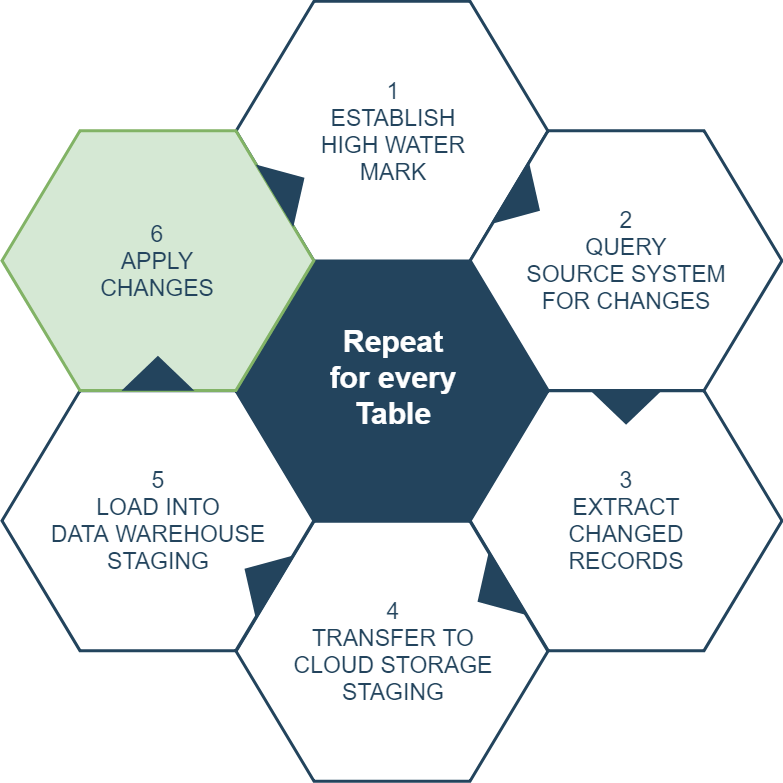
Every source system has its own mechanism for data extraction and load (the E and L of ELT). It might be JDBC, or API-based, or maybe it’s a SaaS system with a specific Matillion connector. You would use this mechanism periodically to bring changed data into the data warehouse staging area, by asking for data updated after the current high water mark. This is shown as steps 1-5 in the below diagram.
The Insurance source system
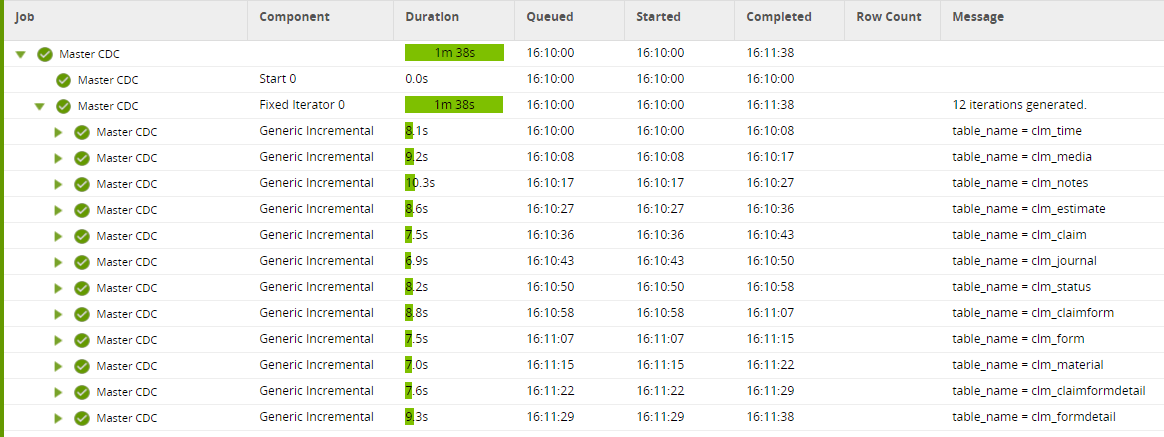
We’ll use an insurance claims management system as the example.
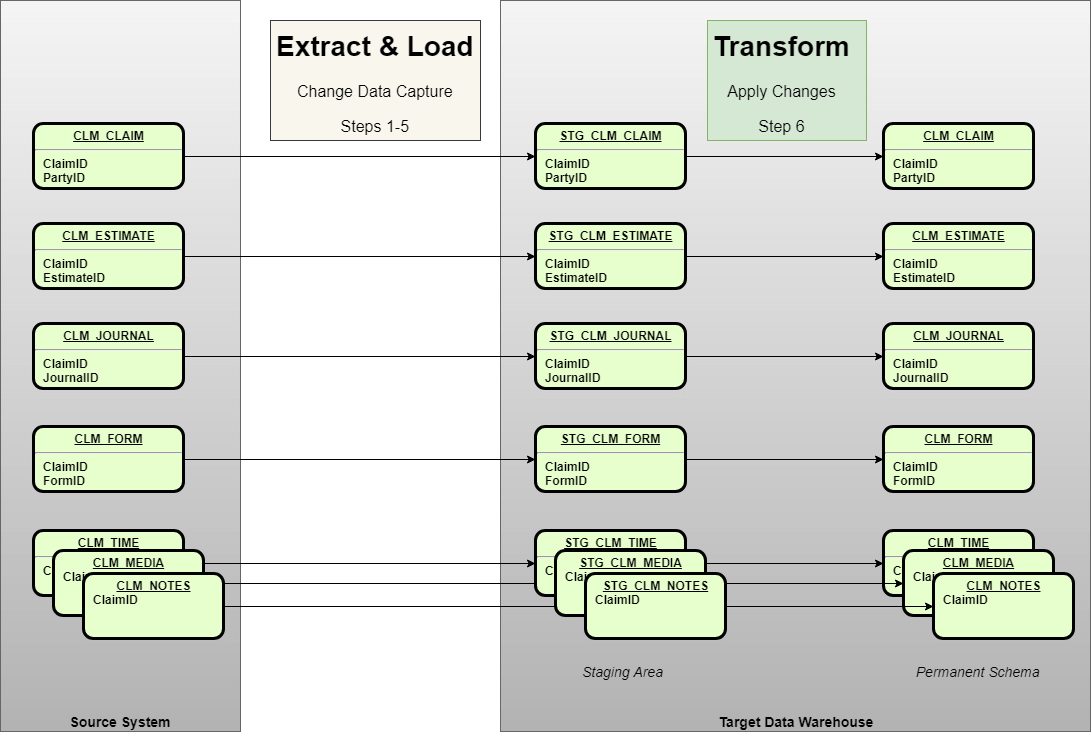
The data model is fairly simple, with 12 related tables. The diagram below shows 7 of them as the data flows from source system to target data warehouse.
- Steps 1-5 perform the Change Data Capture Extract and Load.
- Step 6 performs the Transform step which merges the changed data into the permanent schema containing a replicated copy of every source table.
Change Data Capture
The main driver for Matillion’s generic incremental loading is a loop over the tables to replicate.
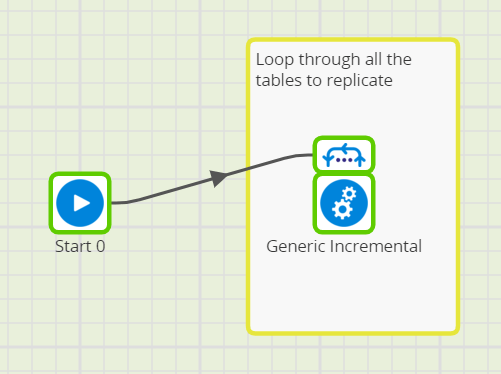
You could use a Fixed Iterator for this, as shown above. Alternatively, you could make it data-driven by using a Table Iterator to loop through a list of table names. The iterator passes the table name into a Job Variable owned by the Generic Incremental job.
The Generic Incremental job looks like this:
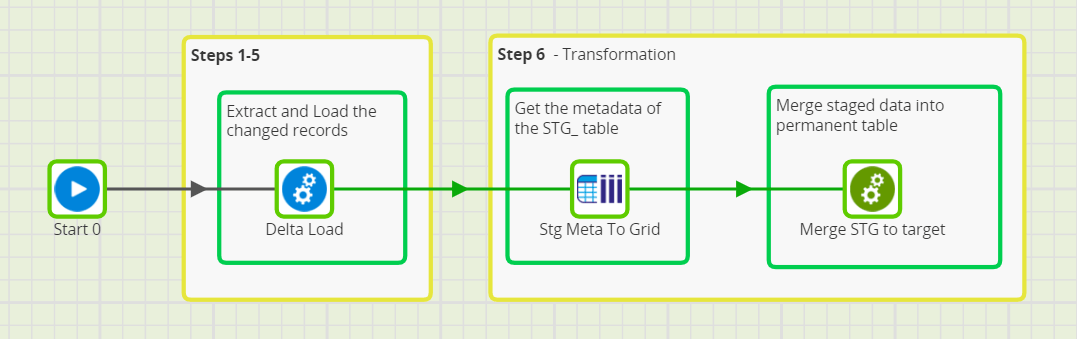
We won’t dive into the details of the Delta Load in this blog, because this transformation technique applies to any source system and any method of Extraction and Load. Instead, we’ll pick up the trail after steps 1-5 have been completed, and every STG_ table has been loaded with just the records that have been changed at the source.
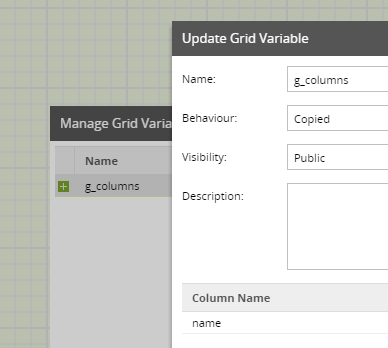
The first step in making the transformations dynamic is to capture the runtime column names. To store the list of names, the job declares a Grid Variable.
This grid variable is given a name: g_columns, and it contains one column called (confusingly!) name.
Matillion’s Table Metadata To Grid component is used to populate this grid variable with the column names of a table.
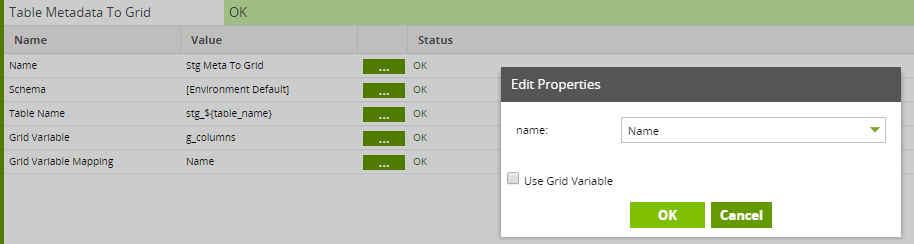
Now at runtime, the g_columns grid variable will have a name column containing a list of all the column names in whichever STG_ table it’s currently dealing with.
This grid variable is passed as a parameter into the generic Transformation job named Merge to Target.
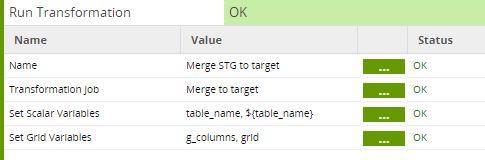
Generic Transformation
This is quite a simple Transformation Job, containing only a Table Input and a Table Update.
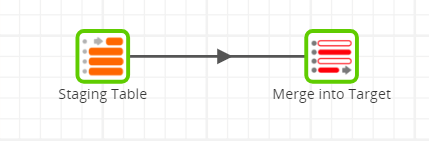
Its purpose is to apply the changed records in every source table to their respective target table in the Data Warehouse.
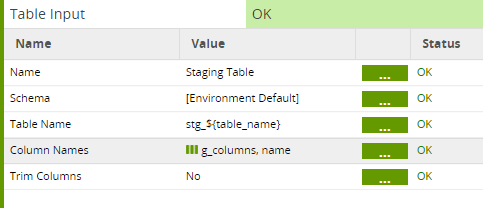
To make the Table Input component dynamic:
- It selects from a variable-driven Table Name
- The Column Names are not hardcoded, rather it uses the grid variable. This is another Grid Variable, declared at job level, identical to the one in the Generic Incremental job
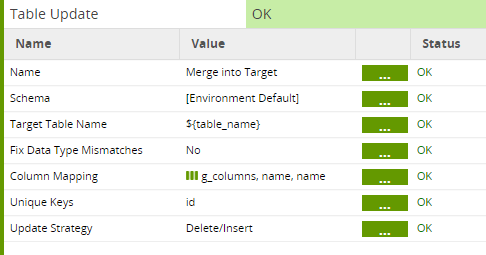
Similarly, to make the Table Update component dynamic:
- The Target Table Name is a variable
- The Column Mapping uses g_columns grid variable again, to map all the same-named columns together
In the Column Mapping editor, the name column is used both as the Input Column Name and the Output Column Name.
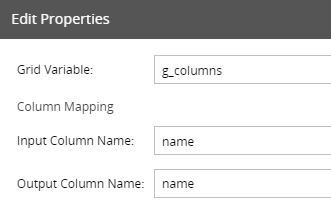
Note that the first time you create the Column Mapping you’ll need at least one valid column name as a default value in the grid variable, otherwise Matillion will reject the mapping. After configuring the component you can remove this default from the grid variable.
In this example, every table has a primary key column named “id” which is used as the Unique Keys property. Other options are possible, including making the Unique Keys another grid variable.
Advanced options
We’ve looked at the simple case where the source and target tables have an identical schema. Matillion’s Extract and Load components typically drop and recreate the staging tables every time they run, so as to match the source schema. This means you may need to manipulate grid variables at runtime, perhaps to remove a column that does not exist in the Data Warehouse target system.
Grid variable manipulation is done in Matillion’s Python Script component, running in Jython mode.
To acquire a grid variable you use context.getGridVariable:
gv = context.getGridVariable('g_columns')
If you wanted to remove a value named ‘tbc’ then you could do something like this:
try: gv.remove([u'tbc']) except: print "Could not remove column"
You do then need to update the real grid variable from the modified Python value:
context.updateGridVariable('g_columns', gv)
You could add value in a very similar way.
Summary
Shown you how to use Matillion’s parameter subsystem to manipulate and use column lists at runtime.
This blog article has explored how to take advantage of Matillion’s Grid Variable subsystem to create a generic data transformation job. You can schedule this job as part of a generic change data capture process, as shown in this insurance schema example.
One single parameterized transformation job is able to take care of incrementally loading 12 different tables.
Featured Resources
Custom Connector for Public Statistics (Police API)
A demonstration of the practical steps for setting up components, manipulating and validating data, creating and scheduling ...
BlogMastering Git At Matillion. An In-Depth Guide To Merging
Merging in Git is the process of integrating changes from one branch into another. Merging is the backbone of collaboration in ...
BlogWhat is an API?
What is an API? An API is an application programming interface that is a way for two or more computer programs or components ...
Share: