- Blog
- 12.12.2022
Increase Data Productivity with Databricks and Matillion
 Matillion’s mission is to help our customers be more productive with their data. We are launching exciting new features to make this a reality for organizations utilizing Databricks to optimize the value of their data – for advanced analytics, AI/ML, and more. These new features include enabling Unity Catalog, Delta Live Table, and Notebook Orchestration directly from the Matillion interface. “Data teams are looking for ways to remove friction and drive value. Matillion product roadmap is all about delivering new innovation and data productivity for Databricks users, by expanding their ability to garner more results from their data, faster and with fewer resources,” said Ciaran Dynes, Chief Product Officer for Matillion.
Matillion’s mission is to help our customers be more productive with their data. We are launching exciting new features to make this a reality for organizations utilizing Databricks to optimize the value of their data – for advanced analytics, AI/ML, and more. These new features include enabling Unity Catalog, Delta Live Table, and Notebook Orchestration directly from the Matillion interface. “Data teams are looking for ways to remove friction and drive value. Matillion product roadmap is all about delivering new innovation and data productivity for Databricks users, by expanding their ability to garner more results from their data, faster and with fewer resources,” said Ciaran Dynes, Chief Product Officer for Matillion.
Matillion, which is available from Databricks Partner Connect, provides enterprise-level data integration capabilities with a visual, code-optional approach to ETL development. Matillion’s interface makes analytics in Delta Lake more accessible, making data and analytics teams more productive with their data. Matillion also ensures data sovereignty, since your data never leaves your network, and enhances your ability to comply with privacy regulations as it brings data ingestion and transformation jobs within your VPC on AWS or VM on Azure.
Matillion's ETL platform is purpose-built for the Delta Lake on Databricks Lakehouse, making it easy to load, transform and prepare data for analytics data science and machine learning. With Matillion’s custom integrations with key Databricks features, Databricks users can quickly and easily build data pipelines at scale to get data business-ready for analytics and data science workstreams.
Unity Catalog
Databricks’ Unity Catalog is a new tool that unifies role-based access control (‘RBAC’) and lineage across all Databricks workspaces. Unity Catalog provides centralized metadata and user management, centralized RBAC based on ANSI SQL grants, centralized data access auditing, as well as query performance through managed and external tables, built-in search, and automated lineage. As a central place to manage access permissions and data sharing, Unity Catalog also makes it easier to manage data access and improves the functionality of the Databricks Delta Sharing standard for securely sharing live data from your Lakehouse to any computing platform.
Matillion’s support of Unity Catalog gives organizations using Databricks the ability to utilize the 3 layer namespace within the Catalog to store and manage their data within their Lakehouse. Permissions on tables and schemes granted at this Unity level will flow through to Matillion ensuring your team gets the right access for them.
Delta Live Tables
Delta Live Tables is a solution that allows users to materialize views of their Lakehouse in Delta Lake on Databricks, making it easier and faster to query data. Delta Live Tables are defined by a SQL query and created and kept up-to-date by a pipeline. With Delta Live Tables, users can now easily query data in their Lakehouse without worrying about the underlying data structure. Additionally, the solution provides built-in data quality checks to help ensure that data is accurate and consistent. Delta Live Tables enables users to easily and reliably build data pipelines while also providing features for managing dependencies, daily partition computation, checkpoints and retries, quality checks, governance, data discovery, and backfill handling.
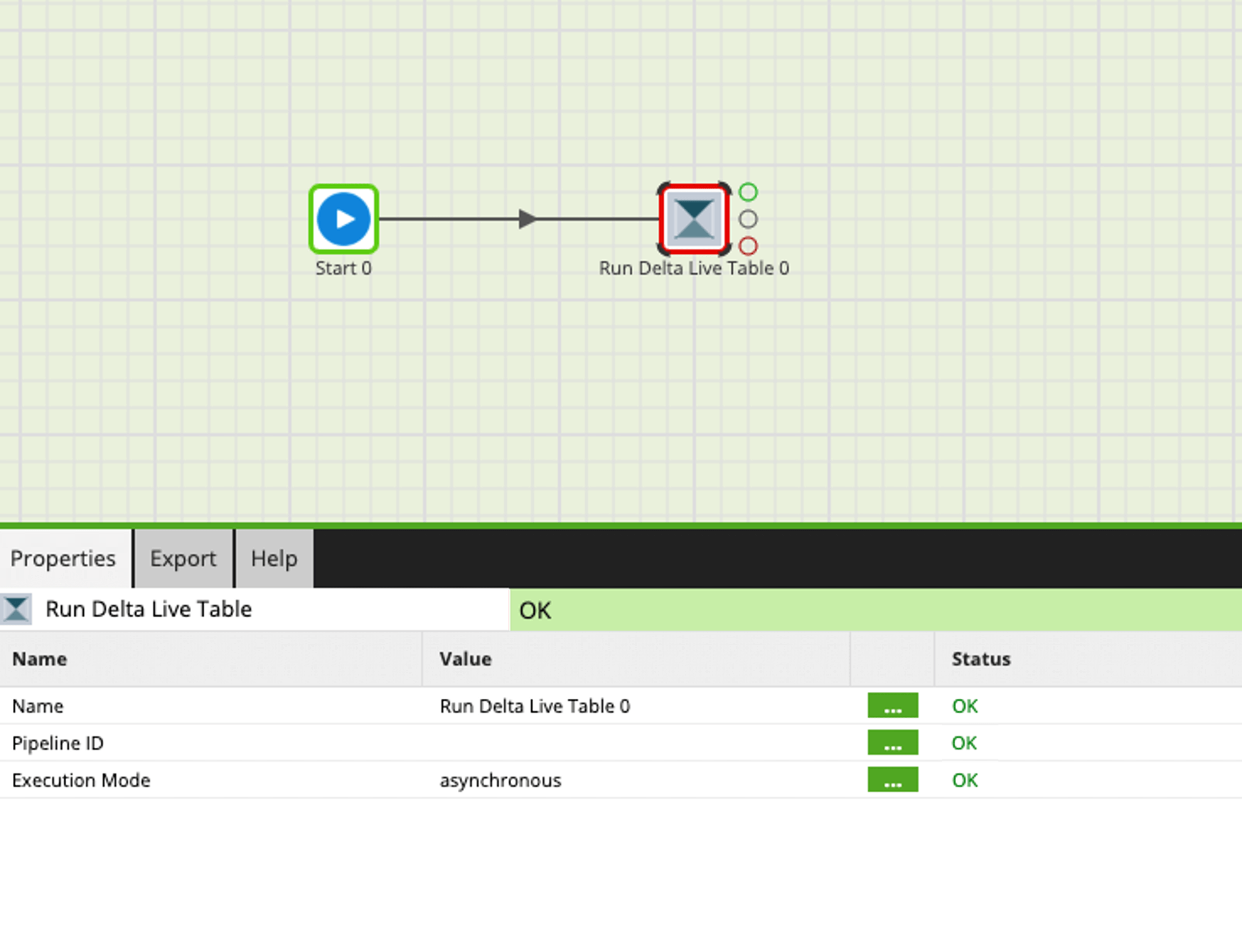
Support for Delta Live Tables goes hand in hand with Matillion’s goal of making Databricks more accessible to more data users, enabling them to be more productive with their data. Users do not have to understand the underlying structure of the data in the Lakehouse and can use Matillion’s visual, no-code / low-code interface to query the data and develop and run their data pipelines by bringing in an existing Delta Live Table pipeline to orchestrate within their Matillion job.
Notebook Orchestration
Matillion is also releasing a new feature that allows users to run Databricks notebooks from within Matillion. This new addition is valuable for users who are looking to complete their data transformation process in a single user interface without having to return to the Databricks environment. The ability to run Databricks notebooks from within Matillion jobs connects the dots between the extract, load, and transform operations already carried out within Matillion. This new feature will provide tight coordination between data transformation and data analysis, thus reducing friction for customers by providing them with a one-stop-shop user experience for all their data activities.
Matillion’s support for Databricks notebooks gives valuable time back to data science and ML teams, enabling them to focus on where they provide the most value. These teams can now build a notebook, let their data management team know what data sources are needed and the extent of data prep required, and hand that works off while they go and build the next notebook. The end result is more projects created and, ultimately, more success for the data team.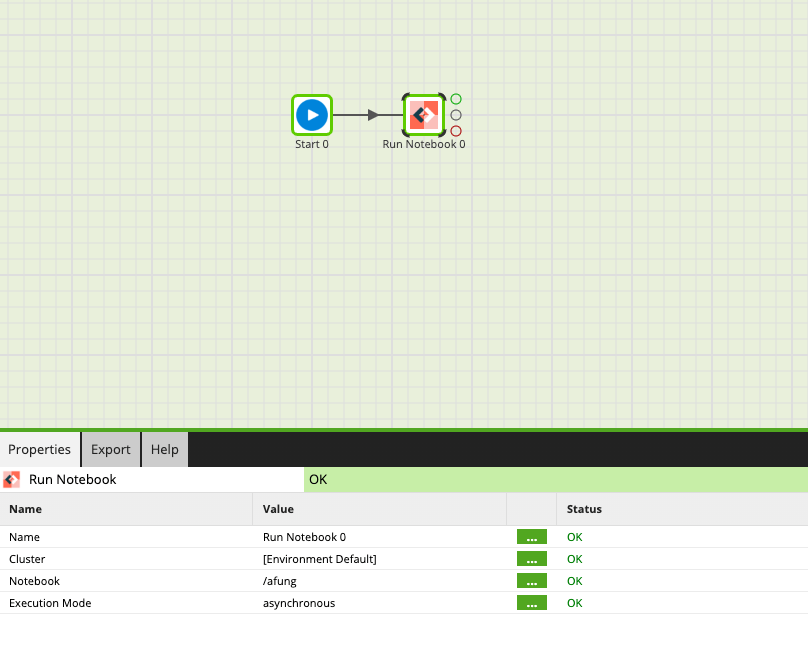
Conclusion
Databricks is well known and loved by technical data practitioners, who often rely on complex coding to analyze the underlying data. However, this complexity might also make Databricks less accessible to analysts without a coding background. Matillion’s low-code / no-code interface, along with support for many Databricks-specific functions directly from Matillion’s interface provides simplicity and automation, enabling technical practitioners with a coding background to do more with data, faster. At the same time, these capabilities also enable Matillion to make Databricks more approachable and usable by more people – those without a coding background – on the data team. With Matillion’s recent support for Unity Catalog, Delta Live Tables, and Notebook Orchestration for Databricks, Matillion expands the potential scope of Databricks usage, ultimately making the entire organization more productive with data.
Andreu Pintado
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: