- Blog
- 04.27.2022
- Data Fundamentals, Dev Dialogues
Connecting Matillion ETL to a Databricks Workspace: A Guide
In Matillion ETL, the metadata for connecting to Delta Lake on Databricks is held in an artifact known as an Environment. Matillion ETL Environments can also hold additional information that is used during data extraction and loading.
Prerequisites for connecting to a Databricks workspace
The prerequisites for connecting Matillion ETL to a Databricks workspace are:
- Access to Matillion ETL for Delta Lake on Databricks
- Permission to create and edit Environments in Matillion ETL
- Your Matillion ETL instance has network access to your Databricks workspace
- Databricks workspace credentials:
- The deployment name of the workspace
- Databricks username and password
Your chosen Databricks user must have at least the following privileges:
- Access to an all-purpose cluster
- Write access to a database
Databricks workspace deployment names and identifiers
Every Databricks workspace is given a unique deployment name. It is used as part of the subdomain in the URL whenever you log into your workspace with a web browser.
For example in the below screenshot, the deployment name is dbc-gzceckpg-1yxe

In general, deployment names follow the pattern dbc-xxxxxxxx-xxxx
Rather than a randomized dbc-xxxxxxxx-xxxx name, you may have a customized deployment name instead. Customized deployment names are used in the URL in exactly the same way. For example, in the next screenshot the deployment name is abcsales.
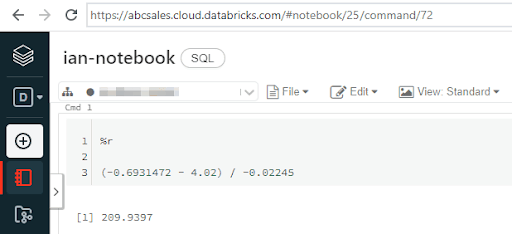
The easiest thing to do is copy the URL from the address bar of your browser. The deployment name, which you will need in the next section, is the text between https:// and .cloud.databricks.com.
How to connect a Matillion ETL Environment to a Databricks workspace
To create or edit a Matillion ETL Environment, start from the main Project menu, or from the context menu in the Environments panel.
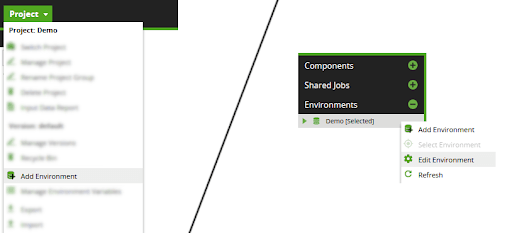
This action will pop up a Create or an Edit Environment window containing three dialogs.
In the first dialog, choose a name for the Environment, and optionally set any AWS, Azure, or Google Cloud Platform (GCP) credentials that you intend to use.
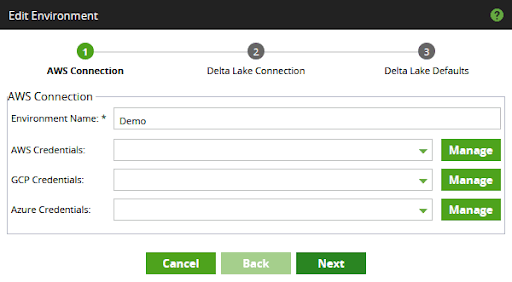
In the second dialog, set the "Workspace ID" to the deployment name of the workspace you intend to use. The previous section contains instructions for how to find your deployment name.
Set your Databricks username and password, using the Matillion password manager. There are two choices at this point:
- The username "token" and a Personal Access Token generated from the Databricks console
- A username and password
The screenshot below shows how to use a Personal Access Token:
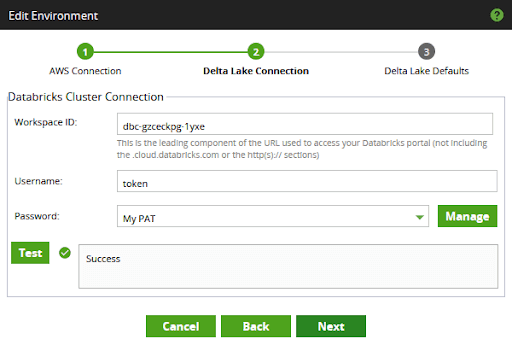
Press the Test button and make sure you see a success message before moving on from this part of the Environment setup.
Press Next to enter the third dialog. While you are completing the details, make certain that the dropdown lists for the Cluster and Database show values that you can select.
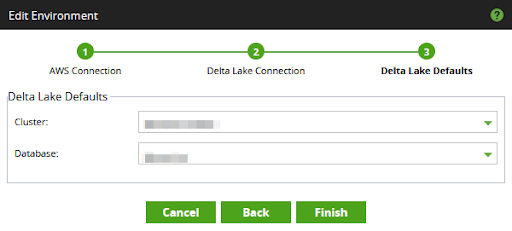
Note that Matillion ETL uses all-purpose clusters for compute during data transformation, not job clusters.
It is possible to finish this dialog without selecting valid values. But if that happens you will almost certainly encounter errors when trying to load or transform data later.
Connectivity metamodel for Matillion ETL and Databricks
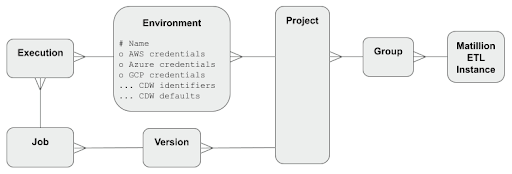
Matillion ETL stores Databricks connection details inside an Environment object. The Environment contains the workspace's deployment name, plus the user credentials in the form of a username and a managed password.
Environments can optionally also hold additional cloud provider information, in the form of AWS, Azure and GCP credentials. This information is used by various orchestration components such as the Data Transfer.
Matillion ETL Environments exist within a Project and a Group. Orchestration and Transformation jobs are versioned within Matillion ETL projects. Jobs always execute within the context of exactly one Environment.
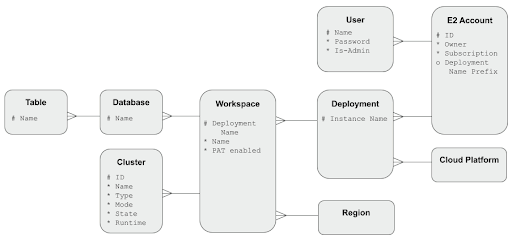
On the Databricks platform, the core administrative entity is the Account. Within an Account, a Databricks deployment (also known as an "instance", and occasionally a "machine") is a specific cloud platform provider context, with a clear trust boundary - for example "Production workloads on AWS".
Since the Databricks E2 platform release, it has been possible to create multiple workspaces within a deployment. Prior to that, they were equivalent.
In either case, all workspaces have a globally unique Deployment Name, that is used by Matillion to establish a connection.
Within every workspace, users can create:
- Databases, for storing data in tables (there is no distinction between a database and a schema)
- Clusters, to provide compute power for data transformation. You will need at least one all-purpose cluster for Matillion ETL to use.
After you’ve connected Matillion ETL and your Databricks workspace
You can start to build workflows in Matillion ETL.

Ian Funnell
Data Alchemist
Ian Funnell, Data Alchemist at Matillion, curates The Data Geek weekly newsletter and manages the Matillion Exchange.
Featured Resources
Data Productivity Cloud Now Offering Stronger Integrations For Databricks Users
Matillions Data Productivity Cloud on Databricks empowers data teams built around Databricks to be more productive and ...
BlogWhat Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
Share: