- Blog
- 07.19.2022
- Data Fundamentals, Dev Dialogues
Data Fabric Integration Using the Matillion ETL Rest API
As part of the continual quest to obtain quick and sustainable value from data, Matillion provides data integration services to the data fabric.
Matillion ETL does – of course – have a visual code-optional interface. But in addition, a lot of functionality is exposed via a sophisticated REST API. Harnessing APIs to automate operations is a great step toward more reliability and less friction. Job management, performance tuning, and data lineage are typical DataOps examples.
This article is intended to help data fabric technology architects and developers take advantage of the Matillion ETL REST API.

Prerequisites
The prerequisites for integrating Matillion ETL API calls into your data fabric are:
- Access to Matillion ETL.
- A Matillion ETL user with API privilege.
- The ability to access a REST API from within your data fabric.
What is the Data Fabric?
Modern data management has come a very long way from the legacy approach of a single, relational database hosted on-premises.
The advent of data-oriented cloud services has democratized access to a huge range of data processing technologies on an enterprise scale. For example, cloud data platforms specialize in hosting data warehouses and lakehouses. Matillion's focus area is making data loading, transformation, and integration scalable and efficient.
All of these cloud services interoperate within a unified security and governance framework. They exchange information using electronic communication methods, such as REST APIs.
This broad set of interconnected data layers and processes can be fully cloud-native, or it can be hybrid. It is known as the data fabric.
How to access a REST API
REST APIs are designed for automating communication between machines. Just like a typical website contains many pages, a typical REST API contains many "endpoints,” each with its own specific address and a specific purpose.
When accessing a REST API, you first need to know which endpoint to use. An endpoint is the normal web address of your Matillion server, with a special path added to the end. Use the Matillion API v1 map documentation to find the right path to use. For testing purposes the "group" API endpoint is a good choice:
http(s)://<instance address>/rest/v1/group
Accessing a REST API means sending data across the network. You probably already have access to Matillion ETL from your own workstation. But, as the diagram below shows, that does not mean other parts of your data fabric can also access Matillion ETL.
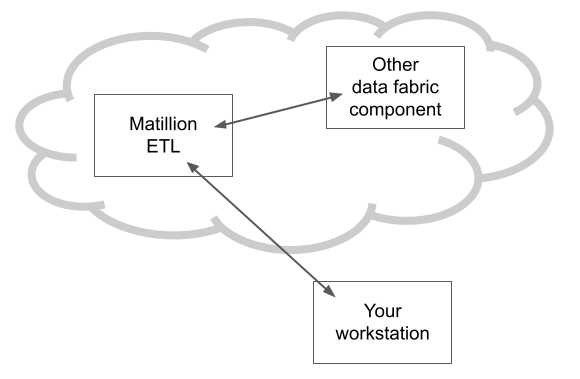
The arrows show the locations of the firewalls that must be open.
Next, you need a way to send an electronic message to the API.
To send a REST API message from your workstation, Postman is a good choice. However, it is much more common to use curl or Python for machine-to-machine communication.
With curl, the command looks like this:
curl -k https://matillion-prod.mycompany.com/rest/v1/group
With Python there is slightly more coding:
import requests
resp = requests.get('https://matillion-prod.mycompany.com/rest/v1/group', verify=False)
Whenever you use Matillion ETL, you have to log in first. The REST API is no different: it also requires authentication. So if the above commands failed with an HTTP 401 error, then you're in good shape :-)
If you have username/password authentication, you can use the same credentials to authenticate into the REST API.
With curl, add a -u option for username / password authentication:
curl -u YourUsername:YourPassword ...
Python requires more coding again:
sess = requests.Session()
sess.auth = ("YourUsername", "YourPassword")
resp = sess.get( ... )
If your Matillion ETL instance uses Open ID login, you have the option to use a bearer token for API calls instead.
With curl, add a -H option for bearer token authentication:
curl -H "Authorization: Bearer YourToken" ...
With Python, add a headers dictionary to the request:
resp = requests.get(..., headers={"Authorization": "Bearer YourToken"})
Rather than re-using a real person's login, it is best practice to set up an automation user for API interactions.
Create a Matillion ETL user to act as a service account for API automation.
Among its many endpoints, the Matillion ETL API includes job management, performance tuning, and data lineage.
Matillion ETL job management
REST API calls are designed to be very short-lived, whereas a large Matillion job can run for a long time. To deal with this, there are multiple endpoints in the job management API.
Launching an Orchestration Job is asynchronous. The API call returns immediately even though the job has only just started running.
Job launch endpoints are long because there is a lot of information to convey!
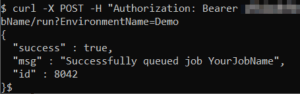
curl -X POST ... https://matillion-prod.mycompany.com/rest/v1/group/name/YourGroup/project/name/YourProject/version/name/YourVersion/job/name/YourJobName/run?EnvironmentName=YourEnvironmentName
In response, you should receive a message that includes an ID.
That ID also appears in the Matillion ETL user interface under Project >Task History:
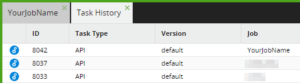
Having launched the job, the same ID can be used to monitor it. The job monitoring endpoint ends with the ID.
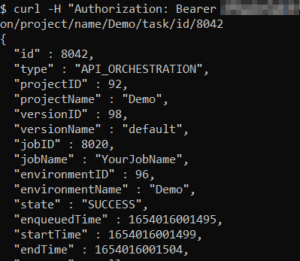
In the screenshot above, the job had already finished successfully, so the start and end times both have values.
You can use the REST API to launch and monitor jobs from any component in your data fabric – including from another Matillion ETL instance.
Performance analysis and tuning
The API response from querying a job contains a lot of information, including all of the timings of the sub-tasks.
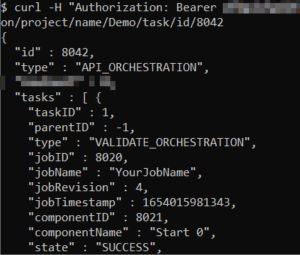
For a long-running job that could benefit from performance tuning, this level of detail is a great help. But as you have seen, the endpoints can be long and unwieldy. Furthermore, when there are many sub-tasks, they must all be parsed and analyzed.
Together, these factors make calling this type of endpoint an ideal candidate for implementation as a Shared Job. You can download a Task History Profiler from the Matillion Exchange that takes exactly this approach.
Consider encapsulating sophisticated API calls inside a Shared Job wrapper
Data lineage
Matillion's metadata API includes an endpoint that can help establish data lineage.
The lineage endpoint is intended to be used with high watermark loading, so it requires a time range. The start and end must be supplied as millisecond epoch timestamps. For example, midnight 15 April 2020 UTC is 1586908800000. Machines find these 13-digit integers easy to read.
Parameterized API endpoints require the information to be added at the end of the path, after a ? character, like this:
.../lineage/?startTimestamp=1651363200000&endTimestamp=1654128000000'
Once again, a lot of information is returned, including all the SQL executed within the time range.
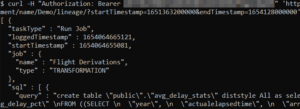
Lineage data like this works well when supplied to a data cataloging and governance partner as another specialized part of the overall data fabric.

Ian Funnell
Data Alchemist
Ian Funnell, Data Alchemist at Matillion, curates The Data Geek weekly newsletter and manages the Matillion Exchange.
Featured Resources
Enabling DataOps With Data Productivity Language
Discover how Matillion leverages Git and the Data Productivity Language (DPL) to enable seamless implementation of DataOps ...
BlogCustom Connector for Public Statistics (Police API)
A demonstration of the practical steps for setting up components, manipulating and validating data, creating and scheduling ...
BlogMastering Git At Matillion. An In-Depth Guide To Merging
Merging in Git is the process of integrating changes from one branch into another. Merging is the backbone of collaboration in ...
Share: