- Blog
- 06.22.2022
Data Modeling Techniques: Conceptual vs. Logical vs. Physical
Many of the articles in the Matillion Developer Relations channel contain logical data model diagrams. They are used both for reference and to help explain concepts.
Logical data models are one type of model along a spectrum that includes several modeling techniques.
This is a quick introduction to the different types of data models. It also describes the notation used in these articles, and how best to read them.
Conceptual data modeling
Conceptual models – sometimes known as Domain models – are the most abstract data models, and at the highest level.
In fact, conceptual models tend to not be pure data models. They usually contain a mixture of information, including:
- An overview of the core concepts in the subject area, with names and perhaps basic definitions
- The operational processes and events that are supported
- For object oriented designs, the methods that can be invoked
Logical data modeling
Logical data models – sometimes also known as Metamodels – contain more detail, and are exclusively data focused. In logical data modeling, concepts are refined into more concrete definitions known as Entities. They describe the things that processes and events can interact with, but nothing about processes and events themselves.
The most essential extra level of detail in a logical data model is the inclusion of information about relationships between Entities.
To aid understanding, a logical data model may also include some guidance about the most important attributes of the Entities.
The main goal of a logical data model is information exchange within a particular context. To avoid trying to boil the ocean, logical data models tend to focus on one area at a time, often omitting information that is important but not fully relevant to this subject area.
Physical data modeling
Physical data models contain enough detail to implement the Entities into a real database as Data Definition Language (DDL). In practice that means at least specifying exact names and datatypes. Almost all physical data models also define primary and foreign keys. Some also hold database-specific performance tuning features like clustering, partitioning, indexing, and constraints.
A good logical data model can be an excellent step towards creating a physical data model. One of the key aims of a low-code/no-code platform is to provide efficient ways to convert logical models into physical models. The operator supplies the logic: The platform converts it into something that can be implemented.
Logical data model notation
A logical data model describes the main entities that are core to a particular area. The information about each one can include:
- A name, to avoid ambiguity
- What attributes you can expect to find
- What makes instances of the Entity unique
- How the Entities relate to each other
Entity naming
Entities are shown as a box with a name.

The above model just indicates that “Organization” is an important concept.
Entity attributes
Often it is useful to highlight some of the main properties that you can expect to find with every instance of an Entity.
In logical data modeling, properties are known as Attributes. The notation is like this:
| # | The unique identifier, known as the Primary Key |
| * | This Attribute is always present |
| o | This Attribute might be present. It is optional, perhaps depending on the value of another Attribute |
In the example below, three Attributes are shown.

Interpreting this:
- “Account” is an important concept
- Every Account can be uniquely identified by its ID. If you have an Account ID, there can only ever be one instance of an Account with that ID. Counting the distinct Account IDs will be a great way to reliably count how many Accounts there are
- Owner is marked as a mandatory Attribute. You can depend on the fact that every account has exactly one Owner
- Prefix is marked as an optional Attribute. Accounts may or may not have a prefix, depending on other factors
Entity relationships
Much of the value in logical data models comes from explaining how Entities relate to each other.
The most common relationship is a one-to-many, which is drawn like this:
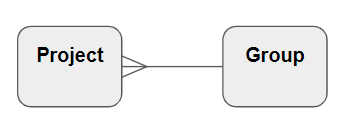
Interpreting the above:
- Every “Group” can contain multiple “Projects” – specifically, zero or more, so there might be none at all
- Every “Project” that does exist must be in the context of exactly one “Group”
There are some things you can infer from a relationship that are usually not shown explicitly. A “Project” always exists within a “Group” so:
- There must be a way to unambiguously identify a “Group”. In other words, “Group” has a unique identifier Attribute. The diagram does not show it, but the primary key must exist
- The “Product” entity must have a Group identifier Attribute. This is known as a Foreign Key
Many-to-many relationships
Many-to-many relationships are very common, and tend to be modeled in a specific way.
In the logical model below, Students can take many Classes, and Classes contain many Students. So you could draw a many-to-many relationship like this.

But drawing the relationship that way is not helpful. Instead, it is better to add an intermediate Entity that records one particular Student taking one particular Class.

That is quite a detailed level of information for a logical model, so it is only used when it is conceptually important.
Data oriented thinking
All the data modeling techniques presented here can be implemented using any cloud data warehouse or lakehouse. The models include information about what entities to expect, how to identify them, and how they relate to each other.
As part of a good data culture, logical data models represent data as both relational and structured. The foundation of all analytics is a clearly defined data model that is being reliably populated with integrated data. This is how data becomes valuable.
In contrast, semi-structured formats allow endless wiggle room for changes – known as schema drift. Committing to the exchange of schemaless semi-structured data is equivalent to not committing to a data model.
With a data-oriented mindset, data models are high level artifacts. Many application features manifest as a consequence of the data model.
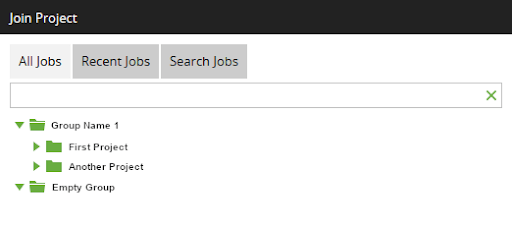
Going back to the earlier example: “Groups” contain “Projects”:
This logical data model is actually part of Matillion ETL, and it determines how the user interface looks. The screenshot below is from the Switch Project dialog, which permits the operator to select a Project from within a Group.
Another manifestation of the same logical data model is in the Matillion ETL v1 REST API. There is a Group level endpoint, at:
http://<InstanceAddress>/rest/v1/group/name/<groupName>/export
There is also a Project level endpoint. But to use it you have to specify a Group name as part of the URL.
http://<InstanceAddress>/rest/v1/group/name/<groupName>/project/name/<projectName>/export
 User Interface layout and API structure are both consequences of the underlying logical data model
User Interface layout and API structure are both consequences of the underlying logical data model
Next Steps
Look out for logical data models in the Matillion Developer Relations online articles.
Get an overview of Database Schema: Types, Examples, and Benefits.
Read more about the switch from process-oriented thinking to data-oriented thinking, and its role in avoiding data swamps.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: