- Blog
- 01.04.2018
- Data Fundamentals
Using the Email Query component in Matillion ETL for Amazon Redshift
Matillion uses the Extract-Load-Transform (ELT) approach to delivering quick results for a wide range of data processing purposes: everything from customer behaviour analytics, financial analysis, and even reducing the cost of synthesising DNA.
The Email Query component in Matillion ETL for Amazon Redshift presents an easy-to-use graphical interface, enabling you to pull data from your email server directly into Amazon Redshift. Customers are using this to pull email data into Amazon Redshift, say from a Marketing account, to combine with other data to measure email effectiveness.
The connector is completely self-contained: no additional software installation is required. It’s within the scope of an ordinary Matillion license, so there is no additional cost for using the features.
Email Providers
Matillion supports the below email providers out of the box:
- AOL
- Gmail
- Outlook
- Yahoo
- Zoho
“Other IMAP” is also available in the Provider drop down menu to allow you to pull data from other IMAP based servers.
You must set up your email services to allow access to lower-security apps. Consult your provider for details on how to achieve this.
We are going to pull some data from a test Gmail account:
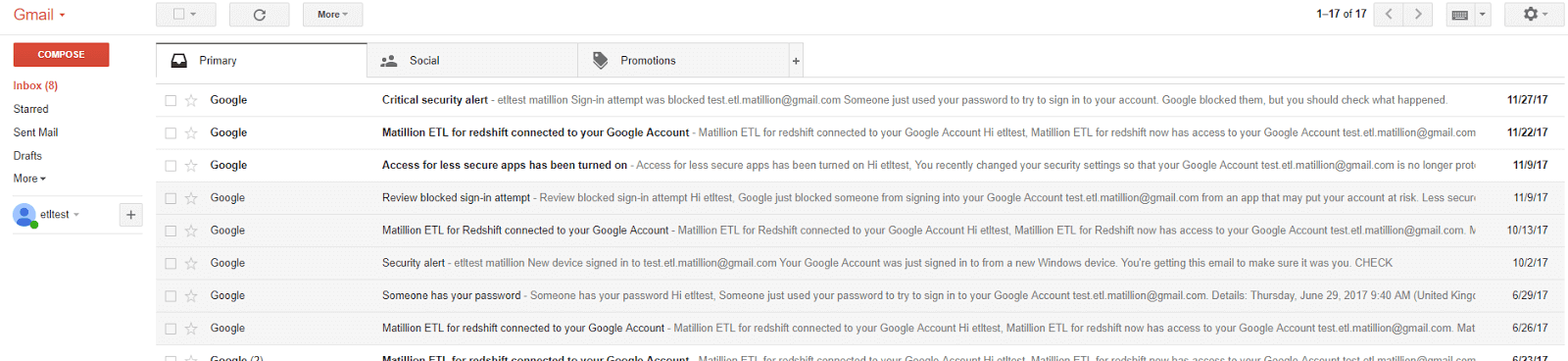
User Account
The first step in configuring the Email Query component is to provide the email address to pull the data from. This is populated in the User property:
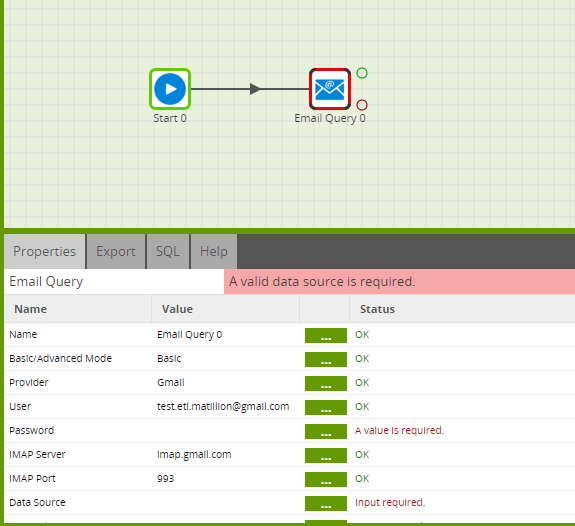
Account Password
The password is the password you would use to log into the email account via the web interface.
Leave the IMAP Server and IMAP Port as per the default, unless you are using the Other IMAP option. If you are using an other IMAP, you will need to configure to your email providers specification.
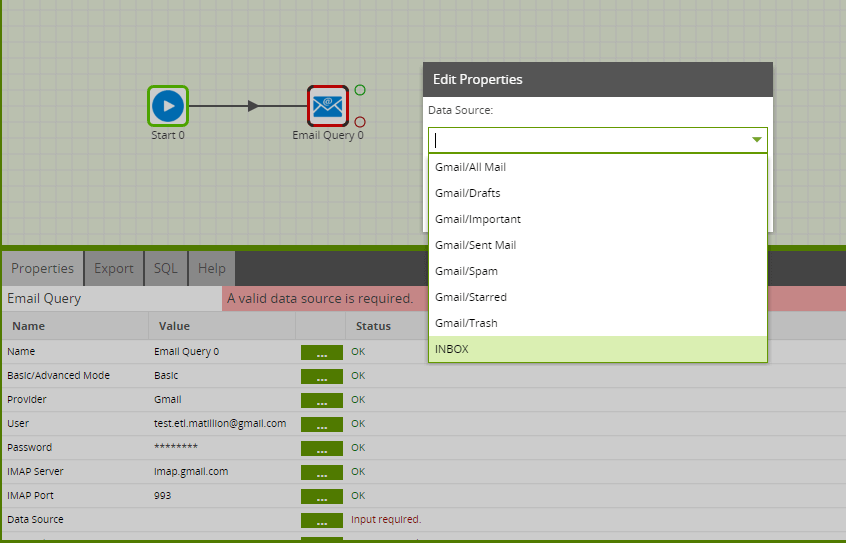
Data Source
Next, choose the data you want to load into Amazon Redshift from the Data Source drop down. This is a list of folders in your email account:
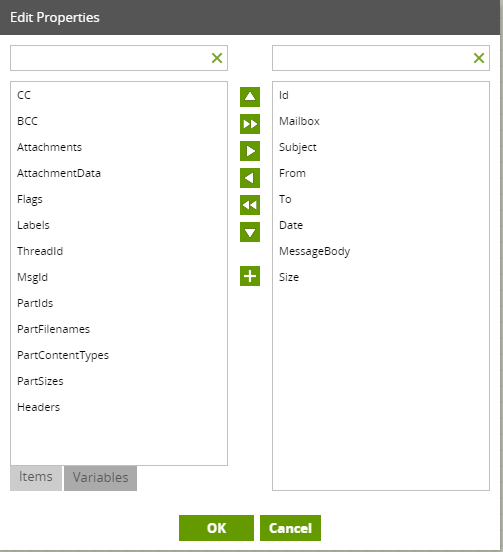
After choosing the data source, the next step is to choose the required fields from the emails in the Data Selection. This will form the new table which you will create in Amazon Redshift.
Data Source Filter
You may wish to add a filter to the emails brought through into Amazon Redshift using the Data Source Filter. Customers often filter the emails on date.
Connection Options
These are some additional parameters which are supported by the driver. No Connection Options are mandatory with the Email driver as sensible defaults are usually given. However further details on the options are available here.
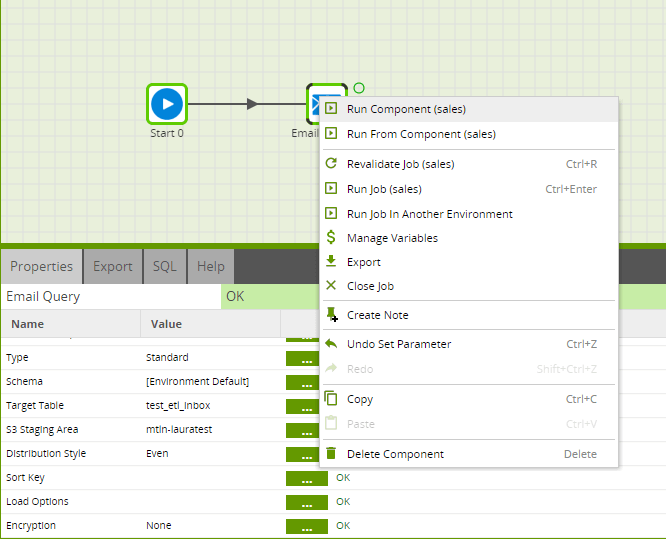
Running the Email Query component in Matillion ETL for Amazon Redshift
Before you can run the component, give the Target Table a name. This will be the name of a new table which you are creating so that you write the data into in Amazon Redshift. Also, you will need to specify a S3 Staging Area. This is a S3 bucket used to temporarily store the results of the query before it is loaded into Amazon Redshift.
This component also has a Limit property feature which you can use to force an upper limit on the number of records returned. We recommend using either a limit or a filter to reduce the number of rows returned and to improve the speed of your job.
You can run the Orchestration job, either manually or using the Scheduler, to query your data and bring it into Amazon Redshift.
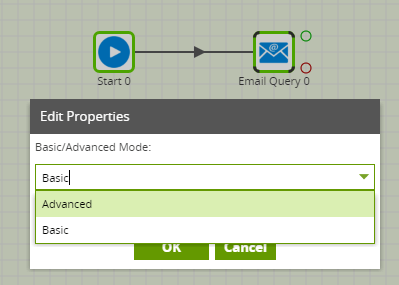
Advanced Mode
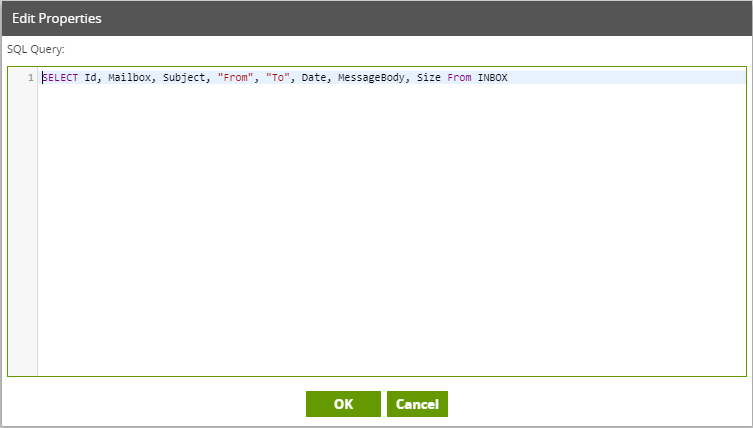
The Email Query component offers an “Advanced” mode instead of the default “Basic” mode. In Advanced mode, you can write a SQL-like query over all the available fields in the data model. This is automatically translated into the correct API calls to retrieve the data requested.
Transforming the Data
Once you have brought your required data into Amazon Redshift from your email service provider, you can use it in a Transformation job, perhaps to enhance existing data:

In this way, you can build out the rest of your downstream transformations and analysis, taking advantage of Amazon Redshift’s power and scalability.
Begin your data journey
Want to try the Email Query component in Matillion ETL for Amazon Redshift? Arrange a free demo, or start a free 14-day trial.
Featured Resources
Enabling DataOps With Data Productivity Language
Discover how Matillion leverages Git and the Data Productivity Language (DPL) to enable seamless implementation of DataOps ...
BlogCustom Connector for Public Statistics (Police API)
A demonstration of the practical steps for setting up components, manipulating and validating data, creating and scheduling ...
BlogMastering Git At Matillion. An In-Depth Guide To Merging
Merging in Git is the process of integrating changes from one branch into another. Merging is the backbone of collaboration in ...
Share: