- Blog
- 03.27.2024
- Data Fundamentals, Data Productivity Cloud 101
Schema Drift For Excel Files with Matillion's Data Productivity Cloud

One of the key challenges that Data teams face today is the ever-changing source data. This article is the first in a three-part series on the topic of Schema drift. Schema drift is where you have defined your data source and have data pipelines built out, and the source changes. Either new columns are added, an existing column is renamed, or the data type changes. Many times, these changes can break the pipeline and send the data engineering team into a scramble to find the problem.
This is a 3-part series:
- Schema drift for Excel Files
- Schema drift for Relational tables (coming soon)
- Schema drift for S3 Files (coming soon)
Part one: Schema drift for Excel files
One common data source is files, specifically Excel files. This pattern will show how to design a pipeline specifically for Excel files that may change over time. This pipeline shows the pattern for capturing those file changes, also called schema drift.
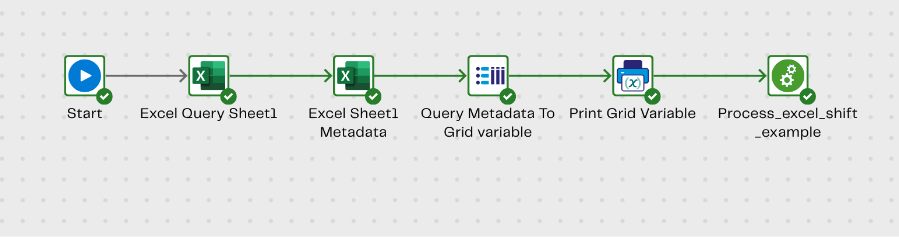
Step 1: Excel Query Component - Initial Query
The Excel query component has an advanced query mode that enables an SQL query similar to tables. In this example, you can create an SQL query to return all of the columns within a sheet.
SQL Query: Select * from [Sheet1]
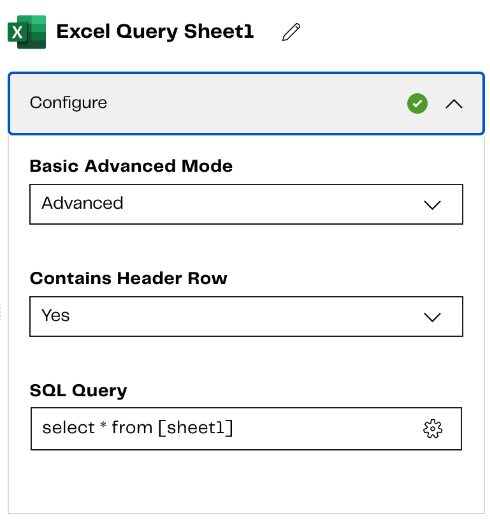
Step 2: Excel Query Component - 2nd query accesses the sheet metadata.
This query accesses the metadata available for the Excel sheet. This component has some system tables that contain this metadata. Query the sys_tablecolumns table to get the sheet metadata and write the metadata to a table in Snowflake.
https://cdn.cdata.com/help/DWE/xls/pg_allsystables.htm
Step 3: Create a grid variable to store the Excel sheet metadata.
Grid_excel_metadata
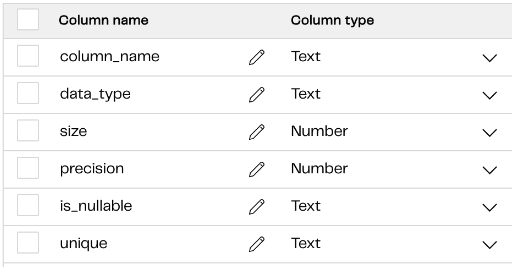
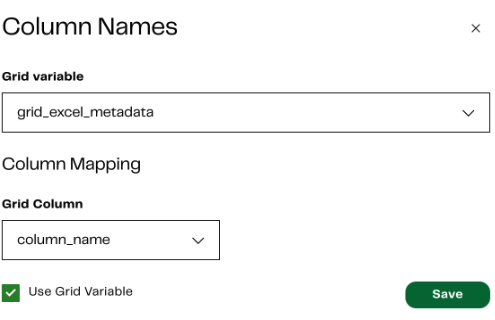
Step 4: Now that the metadata has been stored in a snowflake table, use a ‘Query result to Grid’ component to select the metadata columns from the snowflake metadata table and store them in the grid variable.
Grid Variable Mapping
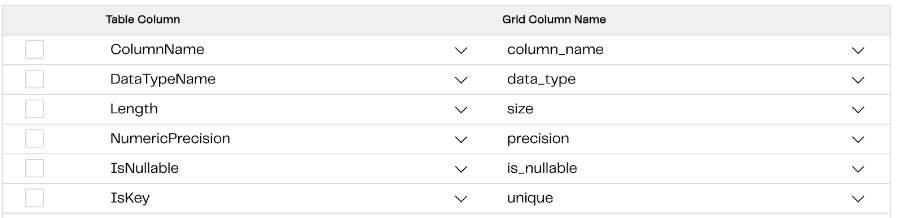
Step 5: This grid variable can be passed into the transformation job to define the raw table and write it out to a target table. When defining the input table, use the grid variable to define the table layout dynamically.
Use the grid variable to define the columns in the input table.
Any further transformations downstream can also be created dynamically by querying the snowflake metadata table “INFORMATION_SCHEMA”.columns table.
Note: The ‘Query result to Grid’ component is only available in Orchestration pipelines. The grid variables and query of metadata have to occur in the orchestration and then be passed into transformations.
In summary, creating a dynamic Excel query will capture any changes to the file. This pattern will capture those changes, pass them along to the transformation, and capture them into the target table. By accessing the metadata, it is possible to create pipelines that are insulated from file changes. The downstream processing could compare the metadata of the incoming source file and the defined target table and have logic to determine if changes should be made or not.
Stay tuned for parts two and three coming soon. In the meantime, check out our resources page!
Angie Hastings
Senior Sales Engineer
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: