- Blog
- 06.18.2018
Using Column Defaults with Matillion ETL for Snowflake
When you create a table in Snowflake Data Warehouse, you are in control of the schema. This means you can choose every column’s datatype: for example character, numeric or timestamp.
One of Snowflake’s features is the ability to supply a default value for columns. This is useful if you don’t know the value at runtime, and it’s also a great way to automatically add a column such as a last updated timestamp.
This article will show you how to take advantage of column defaulting with Matillion ETL for Snowflake, in the context of a dimensional model.
Data Extraction and Loading
You can find all Matillion’s data loading components in the Load/Unload panel when you are editing an Orchestration job.
Matillion’s Load Components all work in the same way:
- Extract data from the original source
- Stream across the network into Matillion
- Matillion creates a new “staging” table in Snowflake (note this is destructive: if the table exists already then it will be dropped and re-created)
- Matillion bulk-loads the data into Snowflake
Normally, you would load a relatively small number of recently-changed records into Snowflake in this way, and then merge them into a real target table for permanent storage.
For this reason, it’s common to have multiple Orchestration jobs:
- A “setup” job, which only needs to be run once to create the real target table
- A periodic “load” job, which runs perhaps daily, and fetches yesterday’s updates into the “staging” table
Setup Jobs
These will typically use components from the DDL palette, especially the Create/Replace Table.
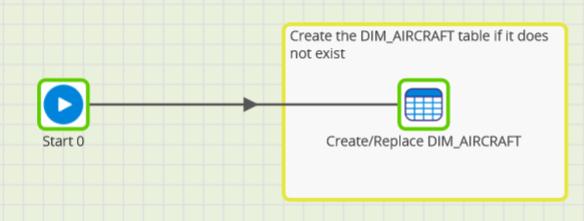
The setup job might be as simple as the one below, which just creates a single dimension table named DIM_AIRCRAFT.
Load Jobs
These can be more complex, perhaps involving sophisticated incremental loading techniques, from any supported data source. In this example, we’ll assume that the Load Job re-creates a Snowflake table named STG_AIRCRAFT_METADATA every time it’s run.
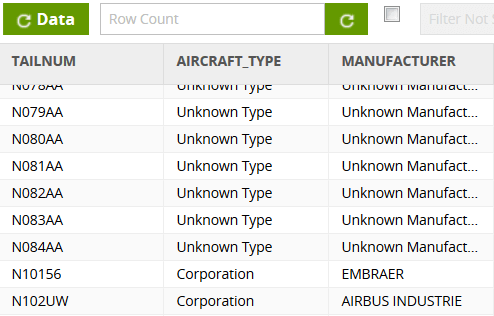
The staging table has an STG_ prefix for easy identification and contains updates for the aircraft reference dimension of a civil aviation data warehouse.
Data Transformation
After loading the new data, the next step is to copy it into the permanent target location. From the STG_AIRCRAFT_METADATA table, the data must end up being merged into the DIM_AIRCRAFT table created earlier.
This is a task for a Matillion Transformation job.
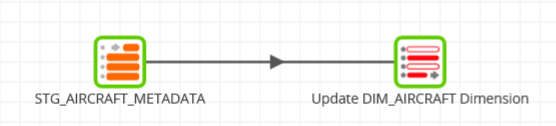
The above example uses a Table Input component to read from STG_AIRCRAFT_METADATA, and a Table Update component to merge the data into the target table DIM_AIRCRAFT.
This is an example of a ‘type 1 slowly changing dimension‘, in which updates simply overwrite existing values.
Automatic audit metadata
No transformation is necessary at all to do this! Instead, you can rely on Snowflake’s column defaults. This is a great way to automatically set a metadata column such as the last updated timestamp.
In the Setup Job, be sure to add a Default Value for the last updated column. This will automatically be applied at runtime.
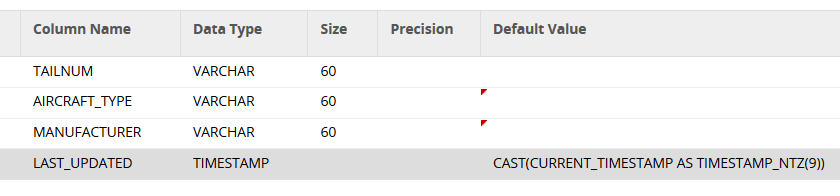
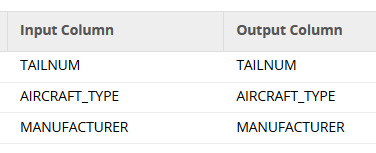
Then, in the column mapping of the Matillion Table Update component, be sure to not include the timestamp column.
After running the transformation, you should find the default has been applied to every LAST_UPDATED value.
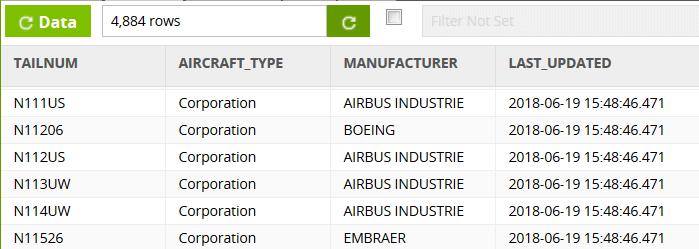
One thing to notice about the timestamps is that, for one set of input data, all the timestamps will be identical down to the millisecond. That’s because of Matillion’s pushdown ELT mechanism: all rows are handled at exactly the same time.
Applying column defaults
Columns which may have a value at runtime require slightly more attention. Snowflake’s column defaults do not apply if you explicitly map a column and it contains null values.
Instead, it’s necessary to add a Calculator component to provide the default values. This can easily be done using a COALESCE statement like this:

The Calculator always adds new columns to the schema, so you will need to change the mapping in the Matillion Table Update component to use the transformed columns instead.
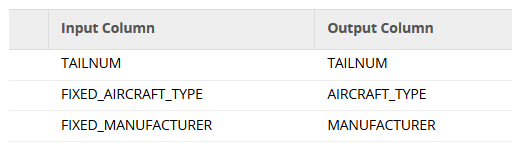
Now, after running the transformation, you will see default values appearing in all places where they were missing from the original source system.
Begin your data journey
Want to try out Matillion ETL for Snowflake? Arrange a free 1-hour demo now, or start a free 3-day test drive.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: