- Blog
- 06.15.2018
- Data Fundamentals
DynamoDB Load Component In Matillion ETL For Amazon Redshift
Matillion uses the Extract-Load-Transform (ELT) approach to delivering quick results for a wide range of data processing purposes: everything from customer behavior analytics, financial analysis, and even reducing the cost of synthesizing DNA.
The Amazon DynamoDB Load component in Matillion ETL for Amazon Redshift presents an easy-to-use graphical interface, enabling you to connect to your Amazon DynamoDB and pull tables from there into Amazon Redshift. Many of our customers are using this service to bring Amazon DynamoDB data into Amazon Redshift to combine with other data and perform analytics on it.
The connector is completely self-contained: no additional software installation is required. It’s within the scope of an ordinary Matillion license, so there is no additional cost for using the features.
Video
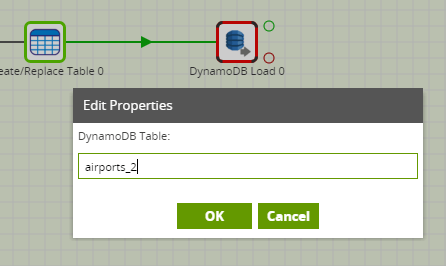
Target Table Name
In order to load data into Amazon Redshift from Amazon DynamoDB, a formatted table must already exist on the Amazon Redshift database, to load the data into. Clicking on the 3 dots next to the Target Table Name property will bring a pop-up box where you can select this existing Amazon Redshift table.
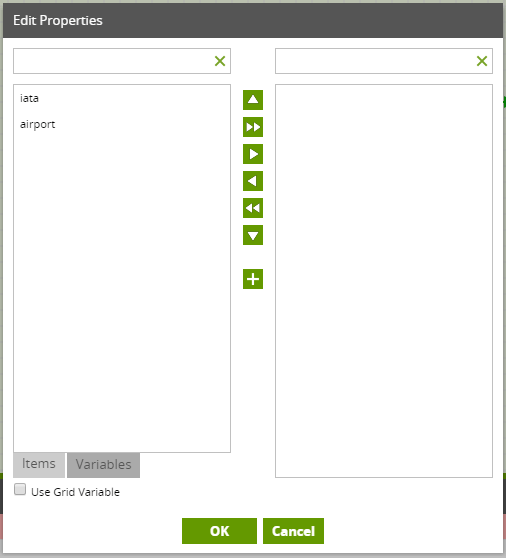
Load Columns
Use the Load Columns property to select a subset of the columns to load if required.
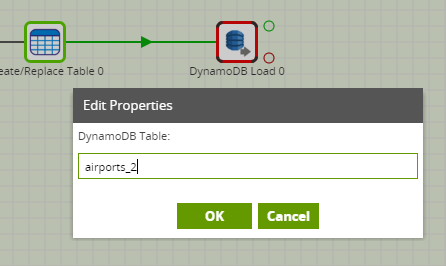
DynamoDB Table
A DynamoDB table is the exact name of the table in the DynamoDB database. which Matillion will connect into and copy into Amazon Redshift.
Read Ratio
Change the Read Ratio property to change the percentage of the Amazon DynamoDB’s provisioned throughput to use for the data load. A lower Read Ration will help to minimize any throttling issues on the database. To use the entire provisioned throughput set this to 100 and this will result in the fastest possible load. Please note this will mean no other process can use this table during the data load.
Region
Change the Region drop-down if you Matillion instance is in a separate region from your Amazon DynamoDB. Select the region of the DynamoDB. If Matillion is in the same instance “None” will work.
Running the Couchbase Query
Before you can run the component, you will need to edit the Matillion IAM rule. This will ensure Matillion has access to DynamoDB to read the data. The AmazonDynamoDBReadOnlyAccess policy is required. Matillion will then use this to copy the data directly from AmazonDynamoDB to Amazon Redshift. Unlike other components this one does not stage data via an S3 bucket:

There are two options for running your Orchestration job. Use the Scheduler or manually trigger the job to query your data and bring it into Amazon Redshift.
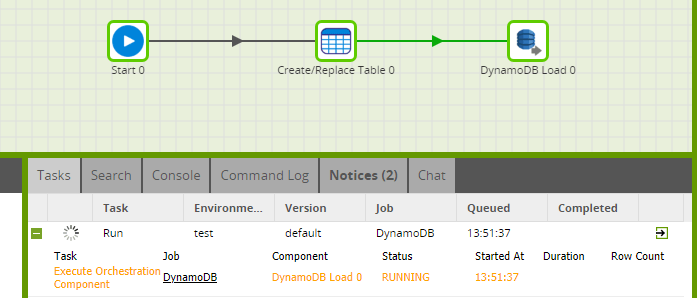
Transforming the Data
Once you have brought the required data from Amazon DynamoDB into Amazon Redshift, you can use it in a Transformation job:
In this way, you can build out the rest of your downstream transformations and analysis, taking advantage of Amazon Redshift’s power and scalability.
Useful Links
Amazon Dynam0DB Load – Component documentation
Integration Information
Begin your data journey
Want to try the Amazon DynamoDB Load component in Matillion ETL for Amazon Redshift? Arrange a free demo, or start a free 14-day trial.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: