- Blog
- 07.30.2018
- Data Fundamentals, Dev Dialogues
Using the Jira Query component in Matillion ETL for BigQuery
Data Extraction
You can access this component from a Matillion Orchestration job. You can find Jira Query among the Load/Unload components when editing an Orchestration job. Data is extracted from your Jira online account, so before getting started you’ll need to know your URL. This is the same as the address you use to access your Jira account from a web browser:
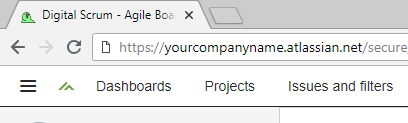
Data is extracted from your Jira online account, so before getting started you’ll need to know your URL. This is the same as the address you use to access your Jira account from a web browser:
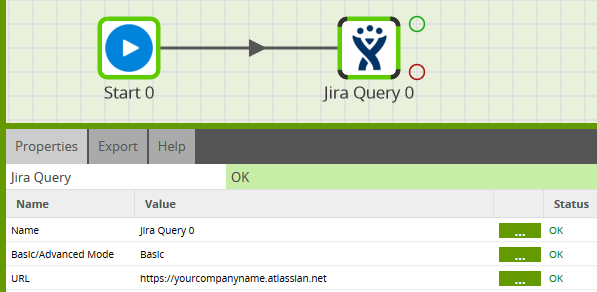
 Use the initial part in the component’s URL property, as shown below.
Use the initial part in the component’s URL property, as shown below.
 When configuring the component, it’s normally best to work from the top property downwards, since some of the prompts have a cascading effect on others lower down.
When configuring the component, it’s normally best to work from the top property downwards, since some of the prompts have a cascading effect on others lower down.
Authentication
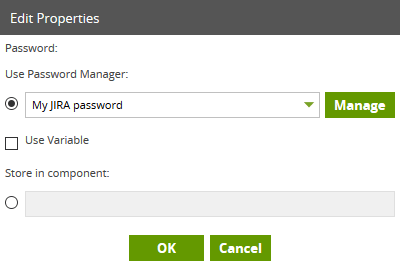
The Jira Query component requires authentication, in the form of a login username and password. You’ll find your Username in the Profile part of the online portal. Your password will be as created by the administrator unless you have changed it since then! Use these values in the Username and Password properties. For the password, you have the option of using Matillion’s built-in Password Manager.
For the password, you have the option of using Matillion’s built-in Password Manager.
Data Source
Atlassian makes a number of tables and views available to query through their API. These are listed in the Data Source dropdown property within Matillion ETL. Choose the one you want to query.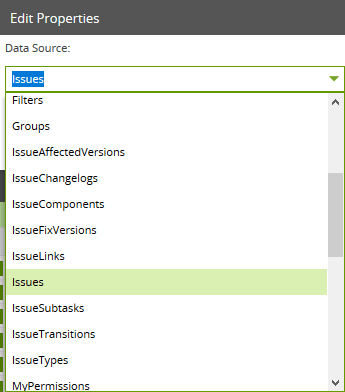 You can see a full list of available data sources in the Data Model.
You can see a full list of available data sources in the Data Model.
Data Selection
Once you have made your choice of Data Source, you can then open the Data Selection property, and choose which items you want to bring into BigQuery.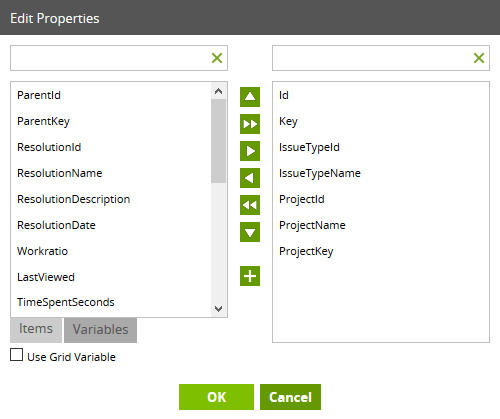 The items you choose in this dialog box will become columns in your BigQuery table at runtime.
The items you choose in this dialog box will become columns in your BigQuery table at runtime.
Data Source Filter
This is an optional field: you don’t have to specify a filter, and if you leave it blank the component will simply copy all the source records into BigQuery. Alternatively, you may choose to filter on a field, for example like this: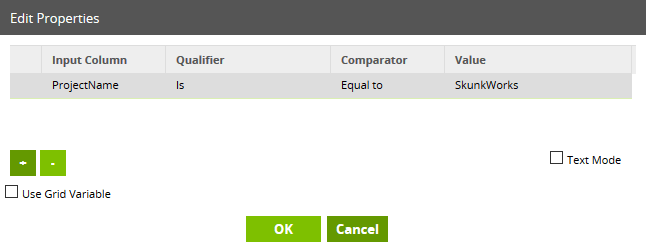 Another commonly-used filter is a date range, for example, a last-modified date, used with Incremental or High Water Mark data loading.
If you specify more than one filter, you may choose to combine them with an AND or with an OR condition.
Another commonly-used filter is a date range, for example, a last-modified date, used with Incremental or High Water Mark data loading.
If you specify more than one filter, you may choose to combine them with an AND or with an OR condition.
 Take advantage of the Limit clause during testing. Its default value of 100 is a useful row-stop. Once you are happy with the other settings, simply remove the Limit value and the component will load all records matching the filter criteria.
Take advantage of the Limit clause during testing. Its default value of 100 is a useful row-stop. Once you are happy with the other settings, simply remove the Limit value and the component will load all records matching the filter criteria.
Advanced Mode and Connection Options
The Jira Query component will normally meet all your requirements in its basic mode of operation, as described in the previous few sections. Behind the scenes, your dialog options are used to create a SQL-like query, which is sent to the Atlassian API for evaluation. Under some circumstances, for example under the guidance of Matillion support, you may choose to use- Advanced Mode - where you specify the SQL query directly
- Connection Options - which allow fine-tuning of low-level settings
- Load Options - to alter the default behavior of the data loading stage
Running the Jira Query component in Matillion ETL for BigQuery
There are two final, mandatory properties that you still need to set:- Target Table
- Cloud Storage Staging Area
Target Table
This is the name of the BigQuery table that Matillion will create on your behalf. If you leave the Project and Dataset at their default value of [Environment Default] then the table will be created in the Project and Dataset that you chose for your Environment.
Alternatively, you can choose a hardcoded value from the dropdown list, or even a Matillion variable.
The Target Table will be created every time the component runs. If it happened to exist already, then by default it will be dropped and re-created. This is because you can change the Data Source and Data Selection at any time, and Matillion must create a table with the correct columns.
Note that the Target Table is usually not the final destination of your data. It’s just used to temporarily store newly-loaded data, ready for integration into the final data model. For this reason, we recommend you use a naming standard, such as an STG_ prefix, to differentiate Target Tables in Load components. More on this subject in Transforming the Data.
If you leave the Project and Dataset at their default value of [Environment Default] then the table will be created in the Project and Dataset that you chose for your Environment.
Alternatively, you can choose a hardcoded value from the dropdown list, or even a Matillion variable.
The Target Table will be created every time the component runs. If it happened to exist already, then by default it will be dropped and re-created. This is because you can change the Data Source and Data Selection at any time, and Matillion must create a table with the correct columns.
Note that the Target Table is usually not the final destination of your data. It’s just used to temporarily store newly-loaded data, ready for integration into the final data model. For this reason, we recommend you use a naming standard, such as an STG_ prefix, to differentiate Target Tables in Load components. More on this subject in Transforming the Data.
Cloud Storage Staging Area
This option is used during the mechanics of data loading. Files will only exist in this location for a short period of time. It’s best to:- Choose a Cloud Storage bucket which is normally empty
- Parameterize the value, so you can easily use it in many places
 Ensure that you have supplied a default value for the Environment you’re intending to use. In the above example, there’s a default of gs://yourbucket/ for the Dev environment.
To use the variable in your Jira Query component, replace any hardcoded value with the variable name, wrapped inside ${}, for example, ${cs_staging}
Ensure that you have supplied a default value for the Environment you’re intending to use. In the above example, there’s a default of gs://yourbucket/ for the Dev environment.
To use the variable in your Jira Query component, replace any hardcoded value with the variable name, wrapped inside ${}, for example, ${cs_staging}
 Watch in the panel at bottom right to check the progress of the task.
Watch in the panel at bottom right to check the progress of the task.
 It should show a green tick once it has finished.
It should show a green tick once it has finished.
Transforming the Data
Having run the Jira Query component, you should then be able to find the newly-created table in your BigQuery console. You’re ready to start work on a new Transformation Job, which reads stg_issues as a Table Input and transforms the data ready to merge into its final destination.
You’re ready to start work on a new Transformation Job, which reads stg_issues as a Table Input and transforms the data ready to merge into its final destination.
Useful Links

Ian Funnell
Data Alchemist
Ian Funnell, Data Alchemist at Matillion, curates The Data Geek weekly newsletter and manages the Matillion Exchange.
Featured Resources
Blog
Enabling DataOps With Data Productivity Language
Discover how Matillion leverages Git and the Data Productivity Language (DPL) to enable seamless implementation of DataOps ...
BlogCustom Connector for Public Statistics (Police API)
A demonstration of the practical steps for setting up components, manipulating and validating data, creating and scheduling ...
BlogMastering Git At Matillion. An In-Depth Guide To Merging
Merging in Git is the process of integrating changes from one branch into another. Merging is the backbone of collaboration in ...
Share: