- Blog
- 01.27.2022
Using the S3 Load Component and S3 Load Generator Tool in Matillion ETL for Snowflake to Load a CSV file
Matillion uses the Extract-Load-Transform (ELT) approach to delivering quick results for a wide range of data processing purposes: everything from customer behaviour analytics, financial analysis, and even reducing the cost of synthesising DNA.
The S3 Load component presents an easy-to-use graphical interface, enabling you to connect to a file stored on an S3 Bucket and pull data from that file into Snowflake. This is very popular with our customers who are loading data stored in files into Snowflake. They are then able to combine this data with data from additional external sources for further analysis.
The connector is completely self-contained: no additional software installation is required. It’s within the scope of an ordinary Matillion license, so there is no additional cost for using the features.
In this example we will look at loading CSV files, containing flight data, stored on an S3 Bucket. We have one year’s worth of flights data per file.
Video
Watch our tutorial video for a demonstration on how to set up and use the S3 Load component in Matillion ETL for Snowflake.

S3 Load Component
In order to run the S3 Load Component you first need to create the table in Snowflake. You will use this table to load the CSV file into when you run the job in Matillion. Next, you need to configure the S3 Load component. While this is not difficult, since Matillion prompts you for all the information, it can be time consuming. This is especially true when you are dealing with a data set that spans a lot of columns. That is because you would need to manually add all columns. To save time and reduce human error you can use the S3 Load Generator in Matillion ETL for Snowflake.
S3 Load Generator Tool
We recommend using the S3 Load Generator to quickly configure the necessary components (S3 Load Component and Create Table Component) to load the contents of the files into Snowflake. Simply select the S3 Load Generator from the ‘Tools’ folder and drag it onto the layout pane. The Load Generator will pop up.
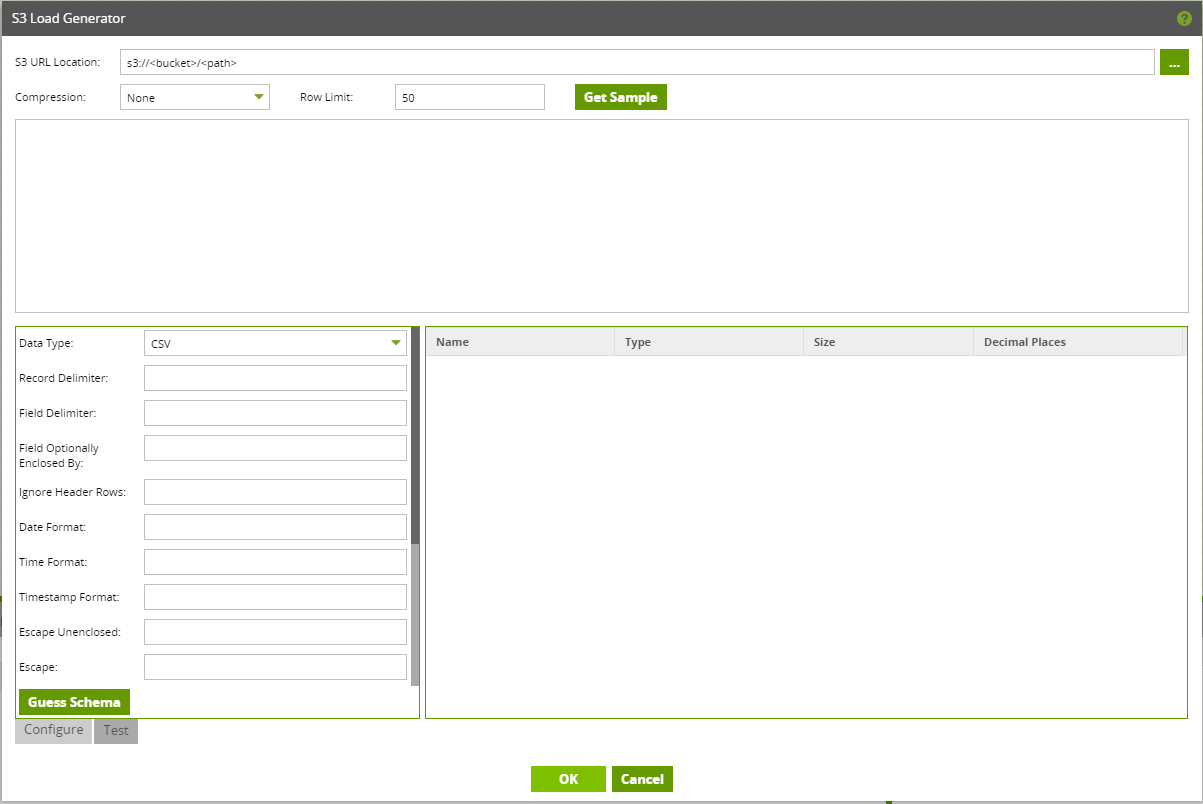
Select the three dots next to S3 URL Location to pick the file you want to load into Snowflake.
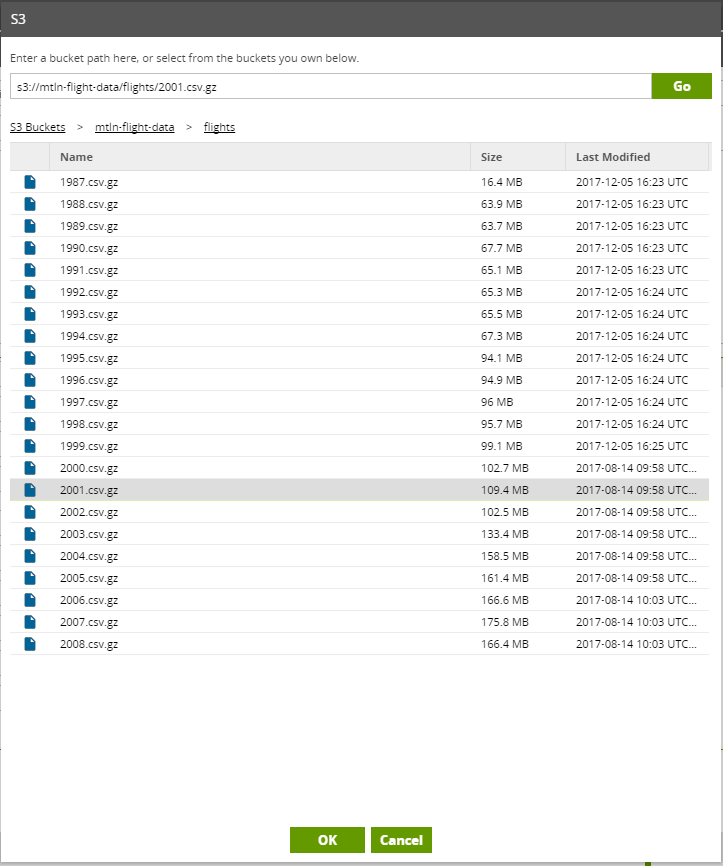
From the list of S3 Buckets, you need to select the correct bucket and sub-folder. Then you can select the file want to load:
Back in the Load Generator, change the compression options in the drop down and select the compression type for the file:
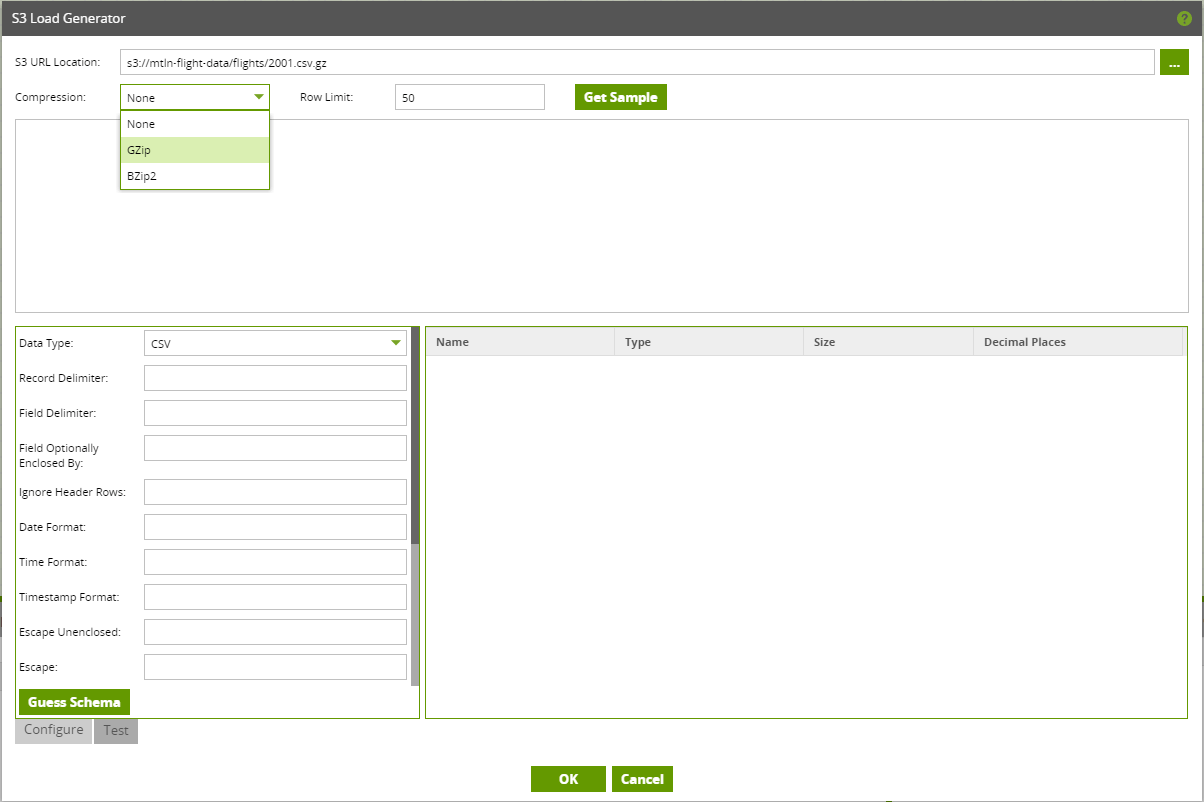
Matillion will automatically unzip Gzip and BZip2 files during the load.
Click the Get Sample button to prompt Matillion to connect into the file and sample the top 50 rows of data. Based on this sample, which is shown in the Load Generator, Matillion will guess the file type and also the metadata for the file.
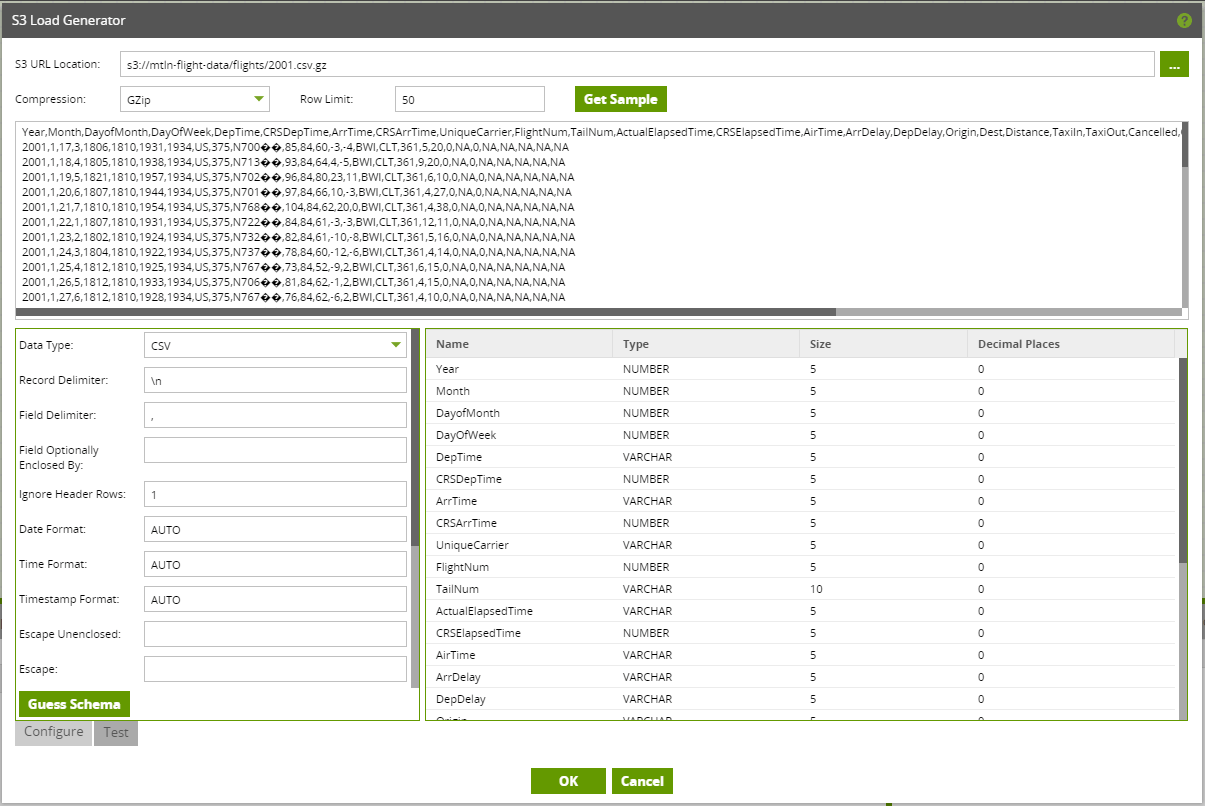
Here we can see Matillion has identified the file is a CSV file with a comma field delimiter and newline Record delimiter. Using the data sample Matillion is able to identify the top row as the header. Matillion then uses the this header plus the data sample to identify the metadata for the table that you are creating in Snowflake to load the data into.
If required, you can change any of these fields.
Click on the OK button and Matillion will generate the required components to load this data to Snowflake:
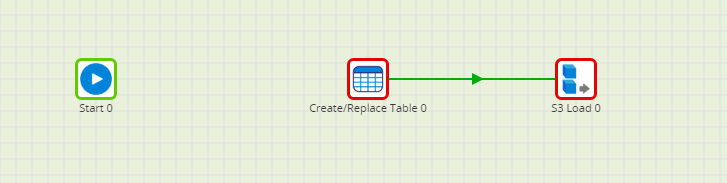
Running the S3 Load
Before you can run the components, you need to connect them to the Start component. This will mean the Create/Replace Table component will turn green. The S3 Load will remain red as it is relying on the table in the first component to exist. However, you can still run the job because the first component will create the table you need. You can run the Orchestration job, either manually or using the Scheduler, to query your data and bring it into Snowflake.
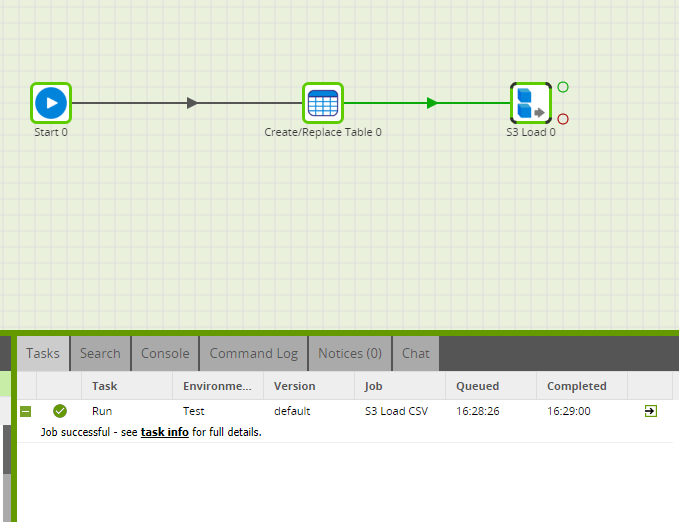
Advanced Options
Object Prefix
The S3 Load component supports Object Prefixes. So rather than creating one component per file to load into Snowflake, you can change the S3 Object prefix to be the S3 bucket, subfolder and start of the file name as below:
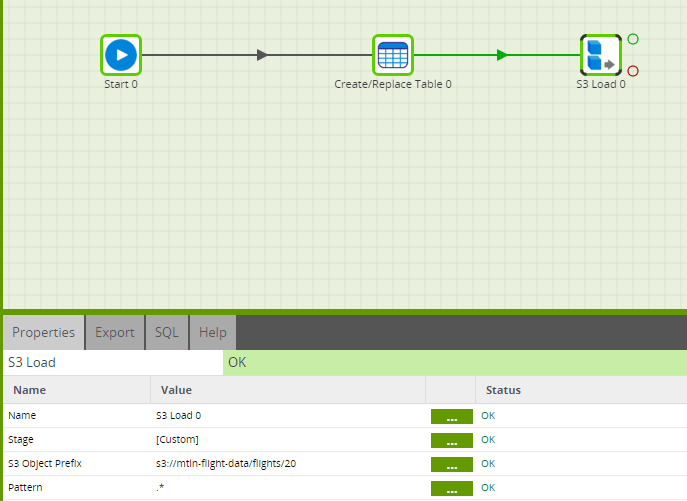
When this runs it will then loop through all of the 20xx files and load them all into the same table in Snowflake.
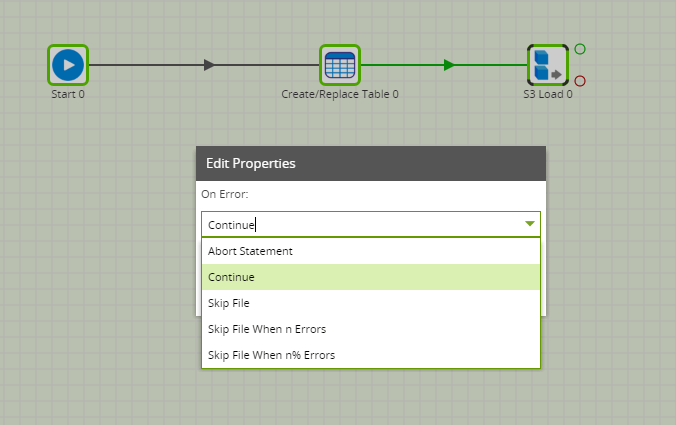
On Error
Another option frequently used is the ‘On Error’. You can use this option to change how the component handles rows in the file which cause the load to error. An error can occur if the rows have columns with incorrect metadata e.g. a string where a date is expected or numbers are too long. You may also get an error when the data is not in the format expected. When you change the ‘On Error’ setting there are several scenarios. First, the whole component can cause an error meaning you aren’t able to load any files into Snowflake. Second, specific files can be loaded. Finally, a certain number or percentage of errors can be accepted.
Purge S3 Files
Finally, after the files are in brought into Snowflake, you have the option to delete the files. You can do this by toggling the Purge S3 Files property.
Transforming the Data
Once the required data has been brought in from the S3 Bucket into Snowflake, it can then be used in a Transformation job, perhaps to combine with existing data:
In this way, you can build out the rest of your downstream transformations and analysis, taking advantage of Snowflake’s power and scalability.
Useful Links
S3 Load Component in Matillion ETL for Snowflake
Integration information
Video
The post Using the S3 Load Component and S3 Load Generator Tool in Matillion ETL for Snowflake to Load a CSV file appeared first on Matillion.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: