- Blog
- 04.01.2024
- Technically Speaking, Bloody Brilliant AI
Food, Shelter, SQL. Maslow's Hierarchy of Needs for Data Engineers
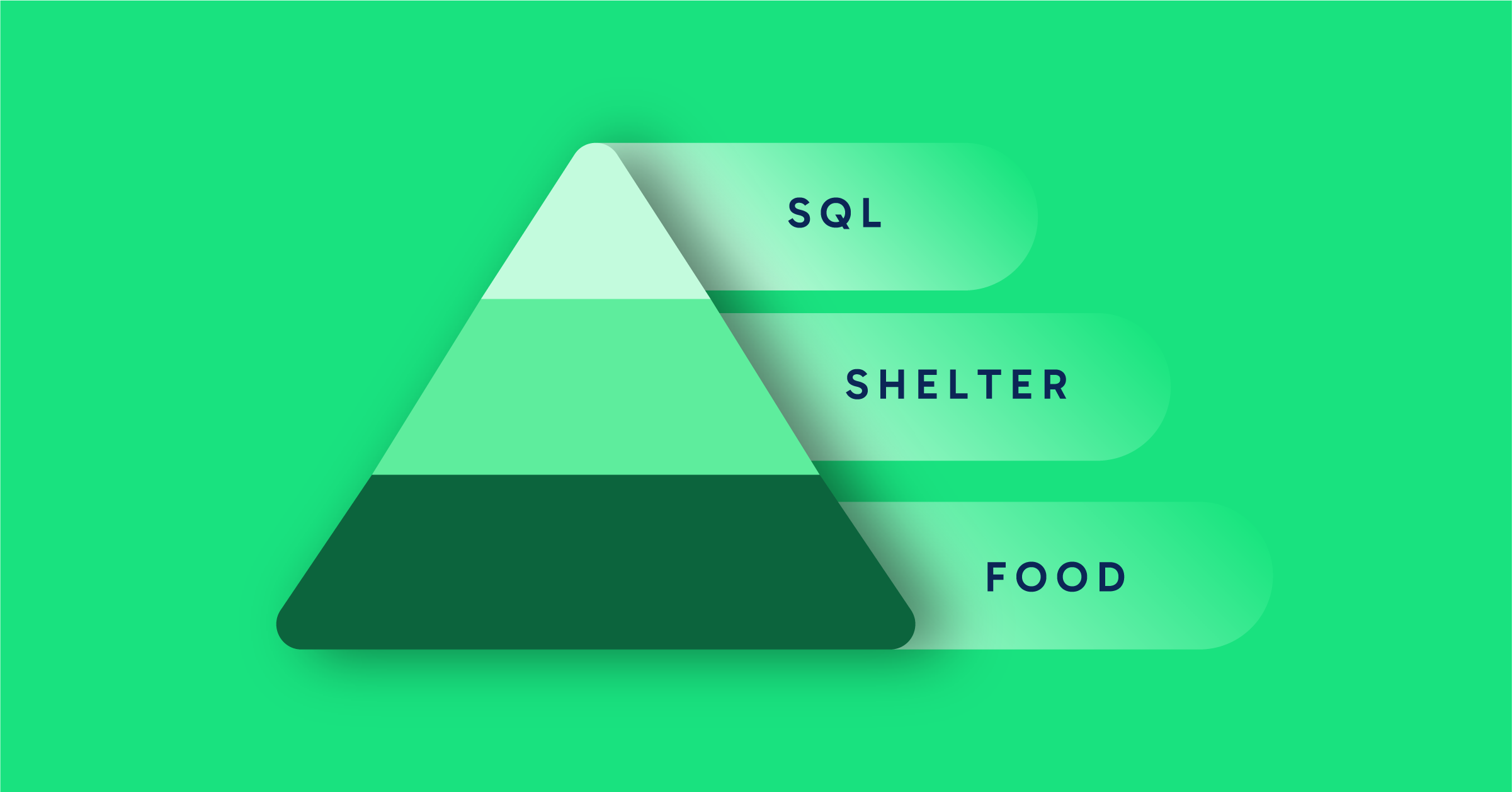
Maslow's Hierarchy of Needs is a psychological theory that suggests that human needs and motivations are arranged in a hierarchy of five levels. People progress through the levels sequentially, with higher needs emerging only after lower ones are satisfied.
At the base are essential physiological requirements, such as food, water, and shelter. Individuals then seek safety and security, followed by the need for love and belongingness, which includes social relationships and connections.
This article is focused on the two highest levels. First esteem - which involves the desire for recognition, respect, and self-worth. Then, at the pinnacle of the hierarchy, self-actualization - in which individuals reach their fullest potential, personal growth, creativity, and fulfillment.
Esteem and self-actualization in the workplace - duplicate tasks and pointless meetings
People spend perhaps one-third of their waking life - or 90,000 hours - at work. According to Gallup, most workers enjoy what they do. But half of this is "busy work" with little or no actual value, and employees report only 33% of time spent doing the skilled work they were hired to do.
How are data engineers feeling about all this? I turned to a Reddit survey and a Large Language Model (LLM) to find out what we are all really thinking.
Why do you like working as a data engineer?
Reddit is the digital showroom of our age. This cacophony of human thought dances with discourse, wit, and curiosity. Well, that plus a lot of unfiltered opinions coming straight from those at the sharp end of data engineering.
This is the thread I chose to analyze. It contains about 160 comments, split into 90 individual threads. You can see part of it in the zoomed-out screenshot below.
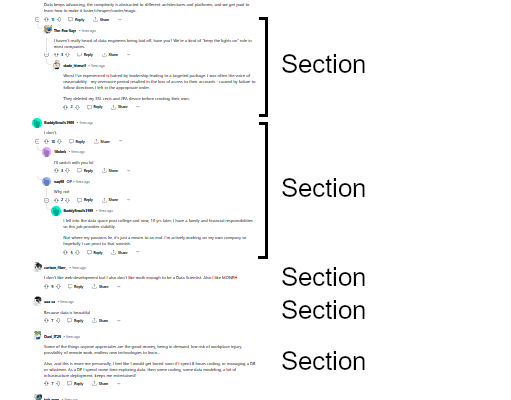
Reddit post - Why do you like working as a data engineer?
Analyzing the text is a language task suitable for any foundation LLM, such as gpt-4.
To prepare the data, I wanted to do several things:
- As with any employee survey data - anonymize it
- Make sure the LLM is only basing its assessment on the comments, not the metadata, the punctuation, or any boilerplate text
- Group all the comments on one topic into individual "sections" - like I have labeled in the screenshot above
This turned out to be quite an interesting data transformation challenge!
Pre-LLM data transformation
I got hold of the data in the simplest possible way: by selecting the contents in my web browser and then copying and pasting it into a text document. You can download the resulting file from here to take a look at the raw data.
It's not really a CSV file, of course. But it's pretty close, being just lines of text that need to go into one column. It can be thought of as a CSV file with no record delimiter, and that's the easiest way to treat it when loading into a database.
The lines follow a regular pattern that splits the file into individual sections of related comments. Every comment begins with an indication of its level - where "level 1" means a top-level reply to the original question, and "level 2" is a reply to one of those, etc.
In the table below, I have highlighted one post.
Original text | Regular expression |
| User avatar | |
| level 2 | level [0-9]+ |
| username | |
| Op · | |
| 5 mo. ago | |
| Blank line | |
| One or more comments interspersed with blank lines | |
| 1 | ^[0-9]*$ (optional point score) |
| User avatar | |
| level 3 | level [0-9]+ |
Regular expressions in a Reddit thread
As you can see, it's easy enough to locate the "level n" lines using a regular expression.
The 5th line and onwards after a "level n" line contain the comments. These may span multiple lines, and they end two lines before the next "level n" line. Normally, a text processing utility like awk is my go-to for this kind of simple finite state machine task. But looking forward is tricky in a streaming model, whereas in SQL, it's simple using a LEAD window function.
I found that the point score occasionally broke the above rule, so it was easier just to remove them all using a regular expression, looking for a line containing only digits.
Section identifiers were easy to pick out using a densification technique with LAST_VALUE - another SQL window function.
Lastly, to aggregate all the comments by section, I used a LISTAGG SQL function within a GROUP BY.
Prompting for esteem and prestige
The first thing any LLM needs is the basic context concerning what it's expected to do. In this case, it's a bit of amateur psychology, so:
You are a psychologist reviewing comments made by people about their job.
Now, the prompts to interpret all those raw opinions. I wanted a one-word answer to classify the overall sentiment as either:
- Prestige (high status, reputation and recognition)
- Money (being paid well financially)
- Satisfaction (the person likes their job)
I also wanted numeric assessments of how people are doing with respect to the two highest levels of Maslow's Hierarchy.
Output | Prompt |
| motivation | Classify the motivation behind the comment into one of the following categories: Prestige, Money, Satisfaction - Prestige classification is when the comment is about high status, reputation and recognition - Money classification is when the comment is about being paid well financially - Satisfaction classification is when the comment indicates the person likes the job Remember to respond with one word only. |
| esteem_score | Give a score between 0 and 10 on the level of self-worth, accomplishment, and respect you feel in the statement |
| actualization_score | Give a score between 0 and 10 depending on how much the statement indicates self-fulfillment, personal growth, and achievement |
Prompt Engineering for Maslow's Hierarchy
LLMs excel at automating this kind of analysis once the plumbing is in place to repeatedly pose the questions to the input data, row by row. There's also usually an interpretation challenge of extracting just the values of interest from the output.
Data Engineering in Maslow's Hierarchy
So what were the results?
At level four, esteem averaged a respectable 6.5 out of 10. It seems that data engineering does mostly meets our psychological needs involving feeling valued, respected, and esteemed by oneself and others.
Are data engineers finding personal growth, creativity, self-discovery, and the pursuit of meaning and purpose in life through their work? A satisfactory average of 6.2 would seem to indicate so!
Most interesting of all was the motivation classification. After skimming through the first dozen or so comments, I thought I had a pretty clear idea of what was going to come out top: 💰💰💰. It's true that data engineering is a difficult job and is well-paid, but it was great to see that job satisfaction far outweighed the other factors.
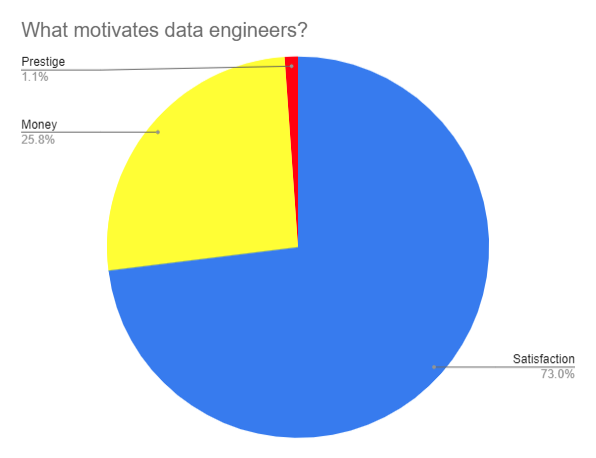
What motivates Data Engineers?
Prestige hardly registers at all. In fact, if you look at the data, "prestige" classifications are always the most debatable, being based on the shortest commentary.
So, I guess this experiment proves what you probably already knew. Data engineering is a fascinating job that is at the core of most organizations' basic functions and ongoing processes. But nobody notices 😉
Try it yourself
You can download and try out the data pipelines that underpin this analysis from the Matillion Exchange.
The Matillion platform is designed to augment data engineering best practices and help practitioners be more productive. Sign up at the Matillion Hub to start a free trial.

Ian Funnell
Data Alchemist
Ian Funnell, Data Alchemist at Matillion, curates The Data Geek weekly newsletter and manages the Matillion Exchange.
Featured Resources
Best Practices For Connecting Matillion ETL To Azure Blob Storage
Matillion makes data work more productive by empowering the entire ...
BlogHow to Choose Your GenAI Prompting Strategy: Zero Shot vs. Few Shot Prompts
Large language models (LLMs) produce output in response to a natural language input known as a prompt. The prompt contains ...
BlogEnabling DataOps With Data Productivity Language
Discover how Matillion leverages Git and the Data Productivity Language (DPL) to enable seamless implementation of DataOps ...
Share: