- Blog
- 03.30.2022
- Data Fundamentals, Dev Dialogues
Data Change Management – Iterate Rapidly and Track Lineage
This is the fourth article in a five-part series on data integration. The series covers the following foundational topics:
- Data-Oriented Programming needs Data Integration – App and format proliferation, the challenge of a process oriented mindset, data colocation vs integration, data integration methodologies and boundaries
- Creating Highly Consumable Quality Data with Data Integration – Data quality, centralization and interdependence, semi-structured data considerations
- Create Data Driven Organizations with a Good Data Culture – ETL and data science teams, interfacing with the wider business
- Data Change Management – Iterate Rapidly and Track Lineage (this article) – Change as an opportunity, low-code/no-code, data lineage
- Data Has State – Data Functions and Design Patterns – data processing functional design patterns, and the development lifecycle

One of the main barriers to the scalable delivery of value from data is the constant demand for speed. Businesses are able to move very rapidly, especially when accelerated by cloud technologies. They need DataOps solutions that can respond equally rapidly. There are technical considerations around data extraction and data transformation and integration. Considerations also exist around the need to create the optimal business architecture in which teams can collaborate most effectively
Of course this is not unique to the data management domain. Many other “ops” terms have sprung up, including DevOps, AIOps, MLOps and DevSecOps, for example. They all refer to architecture and operating principles that enable quick and reliable iteration in their particular discipline. Without those principles, trying to unnaturally force speed can result in design compromises and technical debt. This in turn leads to fragile and brittle solutions.
The demand for constant change cannot be ignored. Instead, the best way forward is to accept that change happens, and to embrace it. Change is a good thing! And so we need a data integration platform that is built to deal with it.
Celebrate change
Changes to information processing are an opportunity, not a threat. The ability to manage change quickly and reliably can be a superb differentiator.
For maximum productivity the ideal is a continuous loop:
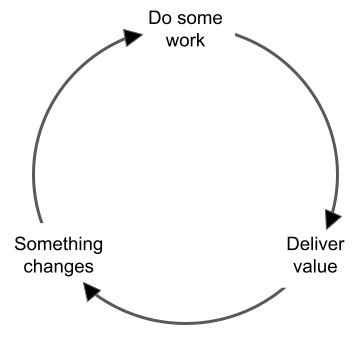
After data analytics delivers value to the stakeholders, several things can happen next. All are great signs that the business is alive and well:
- A request for new, related insights or models
- New systems that provide and manage relevant data come online
- Aspects of the source data change. This is known as schema drift
Let’s use the analogy of a factory floor to illustrate schema drift:
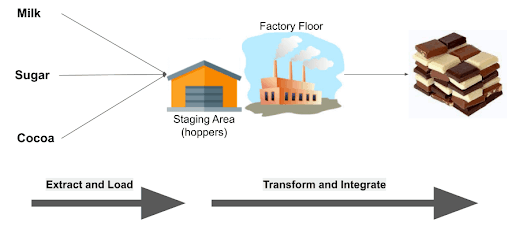
The definition of “done” should be clear from the above. An end to end piece of functionality means the users get their chocolate. The “extract and load” step is a vital part, but on its own does not deliver transformation and integration.
Schema drift means that the source systems can (and will!) unanimously decide to change the data that is written, either semantically and/or structurally.
In this analogy, schema drift means the source ingredients suddenly change:
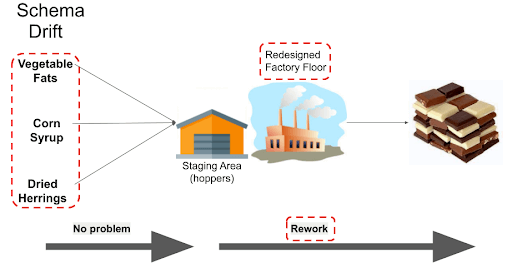
It should be no problem to dump a different set of raw ingredients into the hoppers. Modern data pipeline tools handle schema drift automatically. The scalability challenge is that the resulting internal redesign and rework must also be done quickly and reliably.
In a healthy data culture, the changes I listed a few paragraphs ago will be happening often. That means the data team must be ready to issue software changes and enhancements in short release cycles. A key enabler for this is Low-Code / No-Code tools.
Low-Code / No-Code
To solve a problem using software, there are three classic approaches: build, buy, or outsource. The “build” approach is by far the most flexible of the three, and enables you to create a uniquely differentiated data processing solution. To hand-code, professional developers must understand what needs to be done and must know how to code it in a programming language.
Good knowledge of any programming language is a very high barrier to entry. It is even more difficult to maintain someone else’s programming work, or to program in an easily maintainable way in the first place.
The aim of Low-Code / No-Code (LCNC) is to remove those barriers, and deliver the benefits of the “build” approach without the need to be a programming expert.
A non-professional developer – usually known as a “citizen” developer – should be able to use a LCNC platform to perform the same data processing, but without needing esoteric technical skills. Furthermore, every citizen developer should be able to easily understand what someone else built, and alter it quickly.
The ease of use of a LCNC platform makes it possible for anyone in the business to create and deploy a quick minimum viable product (MVP). It could be any type of data product: a report or dashboard, a piece of analytics, or a machine learning model. Similarly, LCNC platforms make it easy to understand and change an existing data product. This removes barriers that usually make the “build” approach difficult, by taking away the bottleneck of having to exclusively use professional software developers.
LCNC platforms are primarily visual development environments, making extensive use of drag and drop steps to create data processing logic. In practice, there is a spectrum of capabilities:
- Low Code – sometimes known as Code Optional, which does leave some room for custom software development if the user wishes to do so
- No Code – fully graphical platforms, with no coding option. With a NC platform it is appropriate to delegate all development to the business
Of course, software is always needed to process data. The difference is that the LCNC platform writes the software itself. The user does not have to write any lines of code. Instead, the interactions are more high level, declarative and model-driven.
To bring this to life, I will give a few Matillion LCNC examples, starting with one of the simplest. The Rewrite Table component highlighted below will succeed whether or not the target table exists.
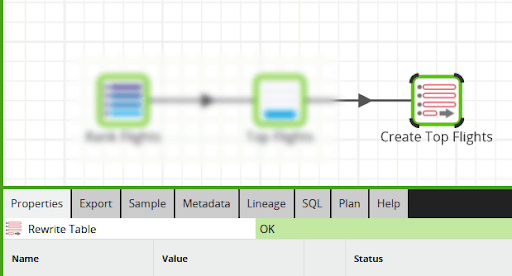
A software developer would have to remember to handle the error generated if the target table already existed. With the LCNC solution, this problem is handled automatically.
Big time savings can also come from the automated exchange of metadata. Here is another example from a Table Input Component. It already knows the names of all the columns that are available. The user can quickly select the columns from a dialog rather than having to type them in by hand.
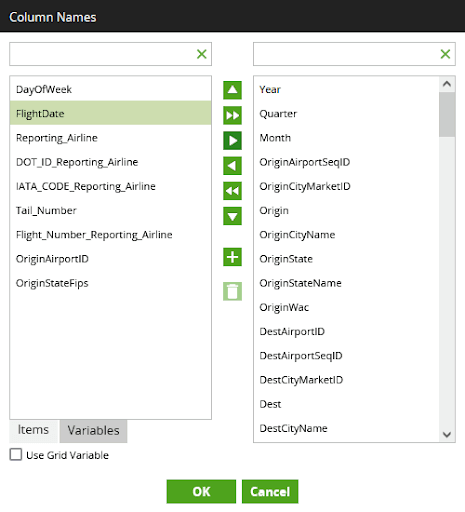
You can also see the option to parameterize the column list, in the form of the Use Grid Variable checkbox. That opens the possibility of making the component dynamic and metadata-driven.
Here is one last Matillion example, from the semi-structured world. The Extract Nested Data component below works out – in real time – what columns are available in the source data. It enables the operator to visually select items, rather than having to hand code it.
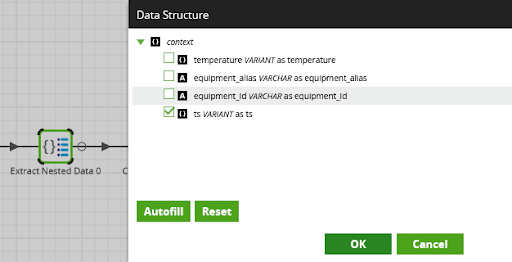
All three of the above examples are available to try yourself in Matillion’s example LCNC solutions that you can download onto your own instance.
In addition to ease of use and declarative encapsulation, another key feature of LCNC platforms is the ability to create reusable functionality. A good LCNC platform should have a wide variety of reusable modules available out of the box, plus an easy way to create and share new modules. This may be via a templating system or a formal marketplace or exchange.
Two great benefits come from code reuse:
- Reuse eliminates time wasted when multiple people solve the same problem. Or, even worse, when those multiple solutions are maintained differently over time. That leads to misaligned data and fragility.
- Reuse promotes the use of standardized definitions. These help with alignment, and are one of the foundations for creating reliable outputs and business confidence. Reusable modules remove some of the technical complications with polysemes that I described in the previous article.
LCNC platforms do not mean the end of software development! They empower both business users and professional software developers. The goal of LCNC is to use the machine to do what it’s good at: mundane, repetitive, and exacting work. This frees up the humans to do what they are good at: exploration, and creative and interesting work.
The main tradeoff with LCNC tools is that as they become simpler to use, their functionality becomes less flexible. With a low-code tool there may be ways to hand-code beyond the boundaries of what the tool was designed to do. Be careful of going too far down that path. It may be preferable instead to use a portfolio of individually more specialized LCNC tools within a larger platform.
A LCNC platform enables you to deliver and iterate rapidly. But that is no reason to tolerate lowered expectations regarding governance. Features such as auditing, source code control, documentation generation, and data lineage should all be built in and automated.
Data lineage
Data lineage means tracking where items of data came from, and where they ended up. This is a key enabler for rapid iteration, in two main ways:
- Data lineage enables quick impact analysis when a change is required. This is known as tracking forwards.
- Data lineage helps perform root cause analysis (RCA) after a problem has been detected. This is known as tracking backwards.
When passing through the typical data model layers in a data warehouse, data lineage tracking forwards looks like this:
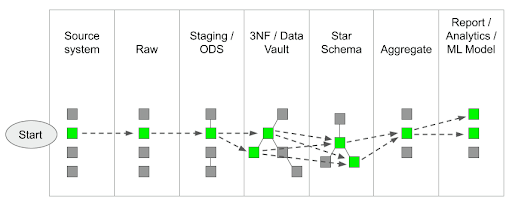
And data lineage tracking backwards looks like this:
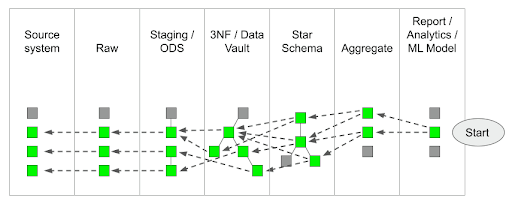
The two are never exact mirror images of each other. At every stage of transformation it is normal that data from one source is used in multiple targets. And data from one target comes from multiple sources.
It is possible to track data lineage at four levels of detail. In increasing order of sophistication they are:
- System-to-system (sometimes called “business lineage”) – This is most useful for data governance and regulatory compliance
- Table-to-table – This is most useful for root cause analysis and impact analysis. When schema drift occurs, it helps the data teams identify which parts of ETL need to be updated. Similarly, this level of lineage helps the data science teams understand which aspects of their feature engineering and ML models need to be reworked. The two diagrams above show table-to-table data lineage.
- Column-to-column – Expands the table-level lineage to enumerate at column level. At this level, there is a huge amount of information so it can become hard to manage. Also, there is the potential for some uncertainty over aggregates, filters, and complex derivations.
- Column-level lineage, additionally considering individual data values – For example, “When column A is 1 then set column B to 99, otherwise set column B to the value of column C”. This level of detail removes all uncertainty from the lineage. In fact, it goes beyond “lineage” and becomes a specification for data transformation and feature engineering. The information might be present in generated documentation or in the business rule specifications of the source apps.
When you get deeper than system-to-system, there is so much detail that data lineage generation has to be fully automated. It would be an impossible task to reliably manage the information manually and keep up with changes.
Another important point about data lineage: At any level of granularity, having timely and accurate data lineage does not prove that data values are correct.
Data lineage is unrelated to data quality
That’s because at any level of granularity, data lineage is a snapshot of software logic at a point in time. It is process-oriented information. When it comes to audit and compliance, several interesting things can happen that are unique to the world of data. Here are some examples:
- We used to use data from a particular source system, but the design changed and we no longer source from that system. It will disappear from a lineage diagram, but the data from that source will almost certainly still be present in the target system.
- We discover that a particular column occasionally contains personally identifiable information (PII) and tighten up the processing to anonymize it. That information security challenge will disappear from a lineage diagram, but PII data from before that change may nevertheless still remain in the target system.
- A data lineage diagram shows that data is sourced in a particular way. But did those data processing jobs ever actually run? And even if they did, maybe the changes were rolled back (i.e. reversed) anyway.
These are some of the reasons why data quality is unrelated to data lineage. They also pose fundamental challenges to iterating reliably and quickly. The underlying reason is that there is something unique about data: Data has state. I will talk about that in the next, and final, article in this series.

Ian Funnell
Data Alchemist
Ian Funnell, Data Alchemist at Matillion, curates The Data Geek weekly newsletter and manages the Matillion Exchange.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: