- Blog
- 07.29.2021
- Data Fundamentals, Dev Dialogues
Serverless File Conversion with Matillion ETL
Matillion ETL has a large set of top level integrations. Each of these integrations has a built–in, top-level connector so that users can easily extract data from sources and bring it into a chosen cloud data platform. These integrations support a variety of file types and data sources. But along with pre-built connectors, there will always be a “long tail” of more niche formats that require some extensibility to process. This article introduces one such example.

While researching for another article, I found an interesting data set that I wanted to use in Matillion ETL. The Reserve Bank of Australia publishes a range of financial statistics, including this table of exchange rates. At the time of writing the current file was ‘Exchange Rates – Daily – 2018 to Current’, available from this direct link.
But one problem appeared straight away. The data was in the 1997-2003 Excel .xls format, which has been officially deprecated for many years. Matillion ETL did not have any component to handle that kind of data natively. So I needed a format conversion into a much more open JSON structure.
Matillion ETL’s primary extensibility option–Python–was clearly the answer. I had three main requirements:
- For this one-off task, I wanted to use a custom Python library without having to actually install anything onto my Matillion instance.
- I found the raw file was unpredictably large, so I needed a scalable way to process it that did not depend on the finite resources of my Matillion instance.
- There’s a data integrity risk with any format conversion, so I was looking for an automated quality control mechanism to detect any problems.
Here’s how I was able to extract and load the file using Matillion ETL to meet those requirements.
Examining the source XLS data
The RBA’s table of exchange rates is typical of many Excel files:There are a number of header lines, formatted in various ways for visual appeal, followed by rows of data.
In Apache OpenOffice it looks like this:
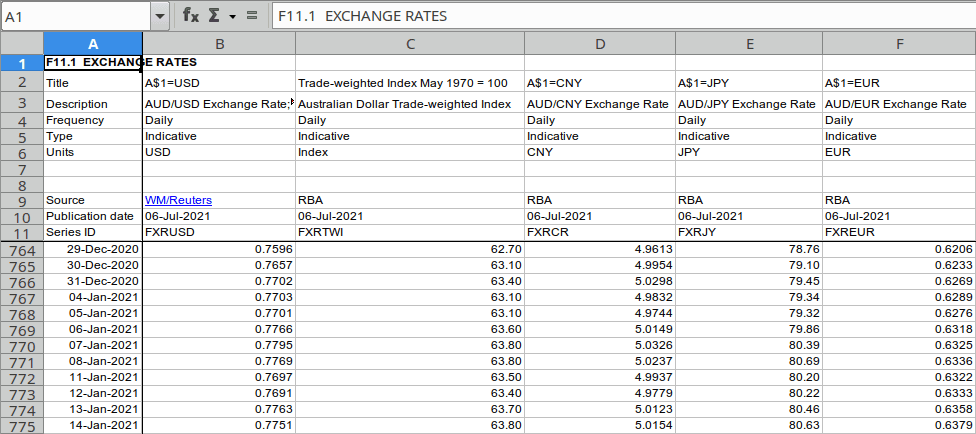
For automation purposes, the most useful data is:
- Row 6, identified by the “Units” keyword, containing the currency codes
- Rows 12 onwards, identified by having a date value in column A, and with the exchange rate values in columns B and onwards
Using the Python module
The xlrd package was written to handle Excel files in the historical XLS format. It provides an easy way to loop through the cells in the workbook and access the values.
There are two important considerations with xlrd:
- When reading a workbook, it has to be entirely held in memory. The files can be big, and I don’t want it to cause memory problems competing with other workflows. So it’s preferable to do that in an independently scalable way, entirely separate from my Matillion instance.
- With a one-off exercise like this, I prefer not to have to install xlrd (plus who knows how many dependency libraries) on my own Matillion instance.
A good solution to both considerations is to have Matillion run the conversion as a throwaway, serverless Python task using AWS Lambda.
Two Matillion orchestration components are needed:
- A Data Transfer
- An instance of the Run Serverless Shared Job from the Matillion Exchange
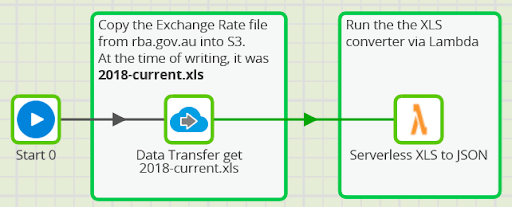
The Data Transfer component copies the XLS file from the RBA website into cloud storage. It’s good practice to make a copy of the original in this way. It reduces the interdependency between the components, and means you have a backup of the source data.
The Run Serverless Shared Job reads the XLS file from cloud storage, and converts it into a JSON file, which Snowflake can read. It uses Python source code which you can download from here.
Four components for quality control
It’s only possible to find out how many records are in the XLS file while it’s being parsed. These are all the rows with a date value in column A, as I mentioned above. The serverless execution saves a logfile into cloud storage, and it includes a line stating how many rows matched.
Four Matillion Orchestration components are used to load the data and check that nothing was missed:
- Expected rows – a Python Script component that reads the logfile from cloud storage, and sets a private variable to the expected rowcount
- Recreate stg_xrate – (re)creates the staging table with a single VARIANT column
- Load stg_xrate – which loads the JSON records into the staging table, and which exports the actual rowcount into another private variable
- Assert Rowcount – an Assert Scalar Variables component that fails unless the actual rowcount exactly matches the expected rowcount.
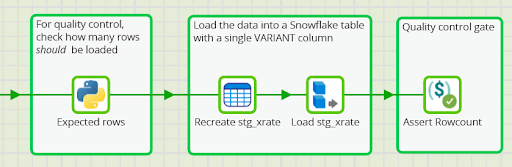
After those four components have completed, a database table will be present in the staging area. It will contain all the exchange rate data with a verified rowcount. You can download an export of the Matillion ETL job from here.
File conversion achieved!
So, first part of the problem solved!
Both Matillion ETL and MDL have a wide variety of connectors. But there will always be formats which don’t have their own dedicated connector for various reasons. So if you have to handle an unusual source data format, consider downloading the Run Serverless Shared Job from Matillion Exchange and using Matillion’s extensibility feature – Python – to access the data programmatically.
Next, on to working with the data in the file, and moving it on from the unstructured, “bronze” area by filling in some of the blanks. This will be the subject of another blog post.
Let Matillion ETL help you convert your data
Looking to extract, load, and transform your data? See how Matillion ETL’s cloud-native capabilities, combined with the power of your cloud data platform, can help, using pre-built connectors or built-in extensibility.

Ian Funnell
Data Alchemist
Ian Funnell, Data Alchemist at Matillion, curates The Data Geek weekly newsletter and manages the Matillion Exchange.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: