- Blog
- 03.16.2022
- Data Fundamentals, Dev Dialogues
Creating Highly Consumable Quality Data with Data Integration
This is the second article in a five part series on data integration. The series covers the following foundational topics:
- Data-Oriented Programming needs Data Integration – App and format proliferation, the challenge of a process oriented mindset, data colocation vs integration, data integration methodologies and boundaries
- Creating Highly Consumable Quality Data with Data Integration (this article) – Data quality, centralization and interdependence, semi-structured data considerations
- Create Data Driven Organizations with a Good Data Culture – ETL and data science teams, interfacing with the wider business
- Data Change Management – Iterate Rapidly and Track Lineage – Change as an opportunity, low-code/no-code, data lineage
- Data Has State – Data Functions and Design Patterns – data processing functional design patterns, and the development lifecycle
Modern data integration
Modern data integration needs are a consequence of a large amount of application and format proliferation. This means that data consumers have to handle many different data sources, usually each with its own unique structure and formats. Experience with data swamps has highlighted how unlikely it is to gain reliable and scalable business value without data transformation and integration.
Modern data integration can be performed by a role, or by an application called a data warehouse hosted in a cloud data warehouse (CDW). When implemented by a role in a data mesh-style approach, the result is very similar, but ends up more like multiple colocated, and largely independent, data warehouses. Each individual data warehouse in the mesh performs all the data integration relevant to one specific business domain.
For simplicity I will represent both approaches like this:
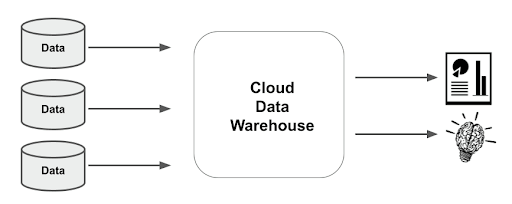
There are two boundaries where data crosses between domains:
| Boundary | Data Integration Goal |
|---|---|
| Source data → CDW | Understand and interpret all the data that is available from the sources |
| CDW → Consumer | Present all the correct data in a highly consumable way that matches the requirements |
Data coming in from source systems is being used to successfully run business operations, so it is in no way “poor quality.” It is more accurate to say that we need to be careful to read it correctly, and to not decrease its quality during data integration.
Making quality data consumable
Good data quality is a sign that the data is fit for purpose. When sourcing data from operational systems, that condition is already met. The data is being used to run the business, so by definition its quality is good. Operational source data may be less than ideally consumable, of course, but that is a different story.
When data is flowing in from multiple sources, and multiple formats are being used, it is not an option to use the data as-is. As I described in the previous article, that approach just leads to a swamp. To integrate data, it needs to be modified to give it consistent semantics and structure. This is known as data transformation. It is often a good idea to have several layers of modifications, as I discussed in Multi-Tier Data Architectures.
The business will be using integrated data to perform analytics, make decisions and gain insights, so it is vital to not reduce data quality during transformation.
Data transformation requires software. The value chain looks like this:
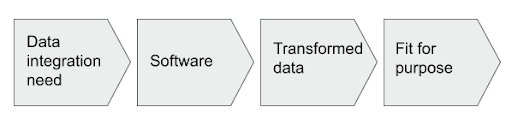
The fitness for purpose of the data is not directly related to the software. A process-oriented methodology would mistakenly focus on the quality of the software rather than on the fitness for purpose of the data. Just because the code is great, or runs fast, does not mean the data is correct! Low Code / No Code platforms create software, but only as a byproduct of the design. In the above diagram, software is in the correct place in terms of priority.
Loss of information or inconsistent transformation can degrade data quality. For example, let’s go back briefly to the calendar example from the first article in this series and imagine trying to integrate data from two calendar apps: Google and Office365.
The two applications serve very similar purposes, but there are some implementation differences. For a start, the meeting roles do not match exactly. For consistency, you could say that “Zoom attendee” and “Teams attendee” should both be converted to “virtual attendee.” But if we have done that conversion everywhere and someone now wants to know specifically how many Zoom attendees there were, can we guarantee that information has not been lost?
In general, the goal of data integration is to be a good data steward that increases consumability while keeping the data quality at its original high level. Data that has been transformed to make it highly consumable makes it look right. But if the data quality has been reduced, it is likely to be wrong or misleading. That kind of incorrect data leads to poor decision making.
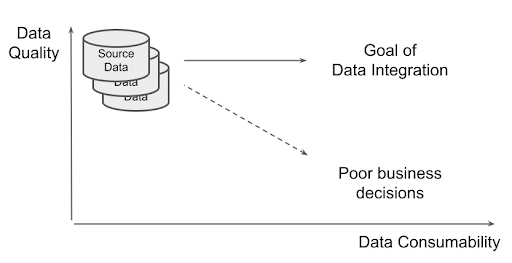
It’s usually not helpful to assign a numeric value to data quality. In the data science world it is common to calculate probabilities, and hence the degree of belief in a hypothesis. But for the underpinning data, it is a rather binary choice: The business either trusts the data or does not.
Data lineage is a great asset that I will discuss in a future article. But –just like the software it snapshots – data lineage is also unrelated to data quality. No business user is ever going to inspect a data lineage chart to figure out whether to trust the data. That’s why they employ a data integration team!
Going back to calendar data integration, many times in the past I have found a contact email address by looking in my calendar application. I remember that we were in a meeting together, although we never actually exchanged messages.
Of course, it’s strange to be looking for contact information in an application with an entirely different purpose. It’s also not very reliable, as the person might have moved or have a new email address. But it’s a good illustration of the fact that the more you dig into data, the more you discover how much is interdependent.
Interdependent metrics
Imagine you are a decision maker who needs to prioritize between three project proposals:
- Work out our sales efficiency
- Substantiate our churn KPIs
- Reliably catalog our customers
Well, I know what I would do. Project 3 is going straight to the bottom of the list. What possible value could that deliver? The other two projects have much more useful objectives.
The problem is that Projects 1 and 2 depend on Project 3.
At the top level, working out sales efficiency in Project 1 just involves aggregating the spend and comparing it to the revenue generated. But to make the insight actionable requires reliable attribution back to individual customers. Then we can find out what kinds of customers result in high sales efficiency, and decide to target those more. So we need a reliable customer catalog.
For Project 2, at the top level we can sum the gain and loss and come up with an overall figure. But once again, no meaningful action can be taken without the ability to link back to individual customers. Then we can find out what circumstances contribute to churn risk, develop predictive models, and take preemptive steps. Once again, we need a reliable customer catalog.
If Projects 1 and 2 went ahead separately without Project 3:
- Two project teams would be independently delivering a private customer catalog for their own needs. They would be wastefully duplicating effort
- Faced with the proliferation of data sources and formats, the two teams would inevitably have differing areas of focus when gathering data. It is almost certain that discrepancies would appear between the two customer catalogs. Efforts to maximize sales efficiency and minimize churn would then be guided by inconsistent data, and neither would be optimal
In other words, a reliable, shared customer catalog provides the level of detail necessary to consistently drill up, down, and across between domains. Without some degree of centralization, good quality, joined-up decision making is at risk.
Centralizing the data
Here is a snapshot of an enterprise dashboard that brings together metrics from multiple departments. It includes
- Renewal count by customer size (small, medium, large)
- Billing count by customer usage (high or low usage)
- Sales count by customer vertical (various)
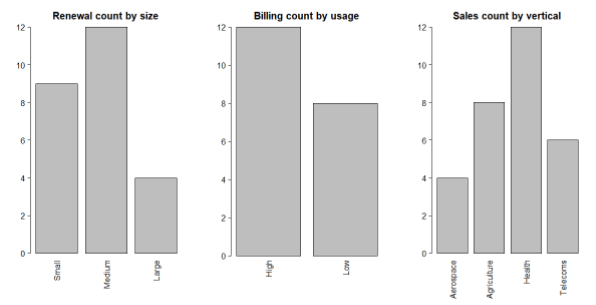
At first glance, it all looks very useful. But not so fast: The data behind the charts is not integrated, and so is not consistent. If you add up the numbers, the Renewals department claims there were 25 opportunities for renewal. But the Finance department reports that they only billed 20 customers. Whereas the Sales department made 30 sales.
Mismatches caused by not using centralized reference information make the figures look suspect. They also make it much more difficult to take action based on joined up decisions. The Sales department might choose to focus more on the Aerospace sector, noting that they saw the lowest number of sales in that area. But what if customers in that sector tend to have low product usage, and low propensity to renew? With non-integrated data, you can’t be certain.
The solution to this problem is to create and use a single, centralized customer reference data set. With data transformation and integration, you can give every customer all the attributes that the different departments need: size, usage,and vertical.
Of course it is helpful to independently decide, department by department, “whatever we are doing, let’s do it better.” But lack of data centralization makes correlation more difficult, which makes the fundamental questions hard to answer. In turn that makes it harder to define exactly what it means to “do it better.”
Using all of the data
In a typical business, which is using many different systems, every data source has a part to play in analytics and decision making. As a guideline, if data is being used operationally, then it is important and should be included.
The classic example of this is the Customer 360 view. You want to get an all round (360 degree) view of your customers in order to understand them, make them happy, and thereby to improve your business.
That means getting hold of all the data, and then linking it to a centralized customer catalog. In other words, integrating all the data. Data gaps are an undesirable consequence of not taking advantage of all the available data. Data gaps result in contextual errors and bad decisions. In the Customer 360 example, the most accurate and most highly personalized models can only be obtained by using data sets from all the many different channels of interaction.
In the not too distant past, the only data available was structured. It was possible to achieve a level of successful data integration using classic federated databases: pushing SQL onto multiple sources and collating the results. This was even possible using reporting tools, with client side blending and mashups.
Now, the proliferation of semi-structured data means that more businesses need to employ modern data integration applications. Integrating semi-structured data requires its own specialized techniques, and has its own unique set of considerations.
Semi-structured data
We are seeing more semi-structured data sources in correlation with the ever increasing number of applications that businesses are able to take advantage of. In parallel, as I described in “Data-Oriented Programming Needs Data Integration”, all those apps manage their data in the way that is most convenient for the app. Most SaaS applications provide bulk data exchange features by hosting an API. By far the most common API data serialization formats are semi-structured, particularly JSON.
Semi-structured data is easily both human-readable and machine-readable. It has a very high information density. Together these factors make semi-structured data sets a convenient and accessible format. The individual items of data are tagged, or marked up, in a standardized way. This makes semi-structured data completely self describing.
Consequently, storing data in semi-structured format is a way of postponing data integration. A widely used example is the design of Data Vault Satellite tables. They are built using fully relational structures, but the decision making interpretation of the data is left to the consumer. All you really know about an entity at any point in time is an unpredictable set of name-value pairs.
For data consumers looking to build scalable, cost effective integration solutions, the two most important considerations for semi-structured data are:
- The writer can, and will, unanimously decide what to place into semi-structured data. This is known as schema on read
- The writer can, and will, unanimously decide to change the way data is written, either semantically or structurally (or both). This is known as schema drift
Schema drift almost always means that some adjustment is needed on the part of the reader to consume and interpret the data properly. Data transformation and integration logic in the data warehouse will need modification. This presents a scalability challenge.
So I will add a caveat to my earlier statement.
Semi-structured data is the most convenient and accessible format for the writer of the data
The most consumable data format for readers is structured, and ideally presented as a star schema. So the main transformation task during the integration of semi-structured data is to flatten and relationalize it; looking for the data you need among the data that has actually been supplied.
The slippery lack of consistency with semi-structured data leaves endless wiggle room for changes. In fact, semi-structured data is a great enabler for unannounced schema drift. For an information system that is trying to make data consumable, semi-structured data must always be parsed and interpreted at runtime. This introduces performance considerations. There are also data governance challenges in terms of cataloging, cleansing, quality management, and security.
How have we managed to let such challenges and potential inconsistencies creep in?
Whenever an application provides semi-structured data, it is because semi-structured data is convenient and accessible for that application. Integrating the data is someone else’s problem. This is entirely understandable of course: In a process-oriented mindset there is no difference between data colocation and data integration! Data integration does not even register as a conceivable problem.
With SaaS applications, data integration was – naturally – not even a design consideration. Sometimes to the extent that the application actively tries to make external data integration difficult.
When it comes to internally-developed applications, data integration was also usually not originally a design priority. Exchange formats also often use semi-structured data, and there is frequent unannounced schema drift.
In fact, even within a single data integration platform there may be internal disagreement in how best to consume data. As I will discuss in the next article, all these things are part of data culture and cross department alignment.

Ian Funnell
Data Alchemist
Ian Funnell, Data Alchemist at Matillion, curates The Data Geek weekly newsletter and manages the Matillion Exchange.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: