- Blog
- 02.28.2022
- Data Fundamentals, Dev Dialogues
“Data-Oriented Programming Needs Data Integration”
To help deliver consistently quick and scalable value from data, it is vital that data processing pipelines are resilient against change and accessible to all.
This is the first article in a five part series on data integration. The series will cover the following foundational topics:
- Data-Oriented Programming needs Data Integration (this article) – App and format proliferation, the challenge of a process oriented mindset, data colocation vs integration, data integration methodologies and boundaries
- Creating Highly Consumable Quality Data with Data Integration – Data quality, centralization and interdependence, semi-structured data considerations
- Create Data Driven Organizations with a Good Data Culture – ETL and data science teams, interfacing with the wider business
- Data Change Management – Iterate Rapidly and Track Lineage – Change as an opportunity, low-code/no-code, data lineage
- Data Has State – Data Functions and Design Patterns – data processing functional design patterns, and the development lifecycle

Imagine, if you will, working in the reporting, analytics, or data science team at a company that used only one application. Things would be relatively simple 🙂 If the application only used one data store, and if it were a relational database with predictable data structures, it would be even easier.
There would be almost no need for any data processing. With only one source, there is no debate, nor any choice. The simple mechanics of ingesting the data would be your biggest challenge.
Now back to reality. In the world where most of us work, there is a huge variety of more and more specialized applications, each with its own niche and unique part to play. An average enterprise uses 400 different data sources, with 1000 or more not uncommon. There is no more “big data”: there is only “data”. The explosion of SaaS solutions and Low-Code / No-Code platforms in particular have played a major part.
At the same time, new kinds of non-relational data have become commonplace. These data types have demanded new storage and processing techniques, with cloud scalability playing a key enabling role. It is more difficult to interpret semi-structured and unstructured data. But format proliferation is an opportunity rather than a threat: it is the only way to get hold of all the necessary information.
All of those applications manage more and more specialized kinds of data. As a consequence, to get the full picture about anything you increasingly have to look in multiple places, gather and interpret multiple varied data formats, and then try to somehow collate it all.
Legacy decision support systems – such as an on-premises data warehouse – are often still valuable as input data sources. Those legacy systems are likely to have undergone changes over time, and the data they manage sometimes still reflects those changes. That means the same information can be represented in multiple different ways even within just one system.
One of the most important things about programming an application has been a focus on process. There are a lot of verbs in most application guides: log on here, press the button, complete this form, do that. More specialized applications focus on more specialized processes. Applications and their processes give businesses a great opportunity to program uniquely customized products.
However, from the perspective of a data consumer, the application is irrelevant. Those verbs are not very helpful. The data left behind by an application has a life cycle of its own, usually with a far wider and longer lasting scope. To most successfully get value from all that data, it is vital to move beyond a solely process-oriented mindset and instead into a data-oriented design mindset.
Process Orientation
The two manifestations of a process-oriented mindset that are most concerning to data professionals are these:
- The design, marketing, specification, and programming of most applications is primarily concerned with process rather than data
- Applications store their data in whatever way is most convenient for themselves
Both those things are completely logical from the point of view of the application. But data consumers need to look at things in a different way.
Here’s an example of the first point. I wanted to find out some more about Google Calendar so I Googled it…
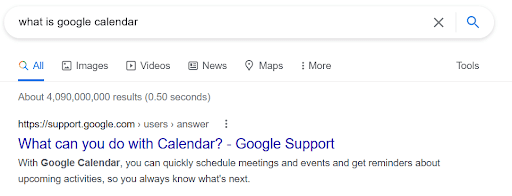
In an effort to be helpful, the search engine went as far as changing the question before answering it. I asked what it is: I got an answer about what it does.
Answers like these tell you a lot about how to use an application. But at best they reveal only peripheral information about the data underpinning the application – which is what we really need to know as data consumers.
I chose Google Calendar just as a convenient example. But you will probably have a similar experience with questions about any application – whether developed internally, or bought off the shelf, or a SaaS application that you are using in the cloud.
Probably you could make a fairly good guess about how the data is organized. For a calendar application, you might start with a logical model like this:
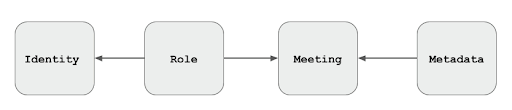
People can join many meetings, and meetings can involve many people. The role a person plays in a meeting is the unique factor. It would not be too difficult to go further and guess that roles would include Organizer, Attendee, Optional Attendee and maybe Zoom Attendee. But then what about Optional Zoom Attendees? Is that a role in its own right, or a combination of attendance method and optionality? There is no way to be certain.
Unfortunately, in most cases it really does remain a guess until you can get hold of some actual data from the application. In a future article I will discuss in more depth the impact this has on a data team’s ability to deliver their work. Meanwhile, I will summarize the first problem caused by a process oriented mindset like this:
Ask for nouns. Get verbs.
Moving to the second point I mentioned above, applications will – of course – store their data in whatever way is most convenient for them. Semi-structured and unstructured data are common examples of this happening. From the perspective of the calendar application I have been using, this is absolutely fine and correct. If people want to book meetings, they should be using the well-designed interface. Not hacking around in the backend!
But a data consumer is not interested in operating the application. They just want to find out about all the meetings that have been booked.
With most applications, it is not possible to access the backend database directly. This practical difficulty is just the beginning of why source data is often described as having only bronze standard consumability. Many applications provide a REST API, or a data export function, or some other bulk mode data access. But what is certain is that the designers of the application’s data store had one primary concern in mind: making the application work as well as possible.
Even if data accessibility and analysis was originally given some data-oriented design priority by the application designers, it was likely a secondary consideration at best. Furthermore, application vendors naturally don’t want you to take your data elsewhere so it’s understandable and normal for there to be barriers at the data level.
Larger applications such as ERP systems may have data integration as a built-in priority. But the approach is always that data is integrated within that one application, in the application’s own data model. It is the user’s responsibility to present data to the ERP system in the way and format that it requires. As part of a wider scoped unique business offering, it is still equally challenging to integrate with other applications at the data level.
Process orientation is the first barrier that a data-oriented consumer must overcome to start collecting value from data. For now, let’s assume you are able to get past that problem, and can acquire data from the many applications your business uses. You are in a good position to start looking for some valuable, joined up intelligence.
Colocation vs integration
The first step in getting value from data is simply getting hold of it. Or, more formally, “extracting” it, by copying it exactly as-is from one place to another. This work is often done by change data capture (CDC) processes such the one found in Matillion Data Loader 2.0, or alternatively by one of Matillion ETL’s connectors.
The newly extracted data must be stored somewhere. Taking advantage of cloud economics, a good storage choice is, of course, your data lake, or lakehouse.
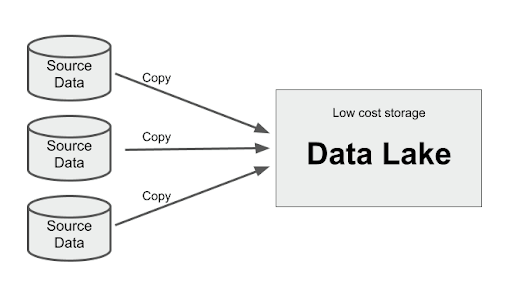
The act of storing data from many different sources in one place is known as colocation. It is a similar principle to a “colo” data center, which rents out space to third parties. All the data is stored using one infrastructure, in one place, but is otherwise unrelated. The colo just provides the storage space; the third parties cannot see each other’s data.
In a process-oriented design that is the end of the story. All the data is in just one place, and it can be conveniently queried using just one technology.
Process-oriented methodologies do not differentiate between data colocation and data integration.
Why not dive right in and start to get valuable, joined up intelligence and insights from the collocated data? How hard can it be? To answer that question, there is a big clue in the fact that data lakes have usually quickly turned out to be data swamps.
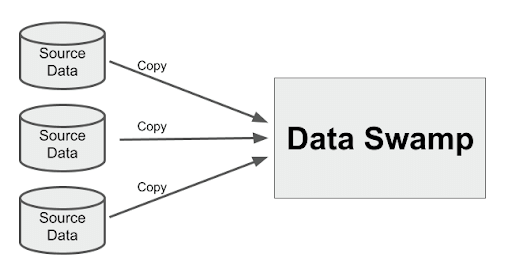
As we have found, data swamps are an unusable dead end which offer no business value.
With colocation, all we do is copy data from place to place. Absolutely nothing gets changed. There is only one conclusion to draw from this: The source data itself is the swamp.
Well, at least now we know what the data professionals are spending more than 80 percent of their time doing 🙂
It is clear that a first – and vital – step in obtaining value from data is to do some deswampification. One of the main tasks involves transforming the data to make it consistent across domains and more consumable. This is known as data integration.
Data integration requires data transformation
The intermediary step of data integration may be a role or it may be an application, or a combination of both. Either way, it is the transformation work performed during integration that starts to make data most valuable.
Data Integration as an intermediary
We have seen that you can not just point a reporting tool, or a dashboard tool, or a data science tool at 400 collocated data sources and press “go”. That was the theory behind dumping all the data into one place (swamp) and expecting it all to interoperate perfectly.
Application and format proliferation results in a lot of data sources, and a lot of different data formats. Getting value from all that data requires an intermediary to integrate it first.
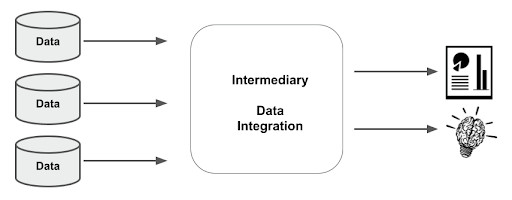
Broadly there are two ways to implement intermediary data integration:
- Using an application – where technology and expertise are centralized, and the intermediary is known as a data warehouse
- Using a role – known as the data mesh or shadow IT approach – where individual experts independently solve all the data integration problems for their particular business domain
Data Warehouse
With the data warehouse approach, the goal is to centralize data and make it more consumable for all parts of the business. This is done by transforming and integrating it through various layers. You can see here how a data integration architecture can be designed, and I will also add more detail in a future article in this series.. Three-tier data architectures tend to be the best way to increase the value of data while keeping down long term maintenance costs.
The main technologies underpinning a modern data warehouse are an ETL platform like Matillion, and of course a cloud data warehouse (CDW).
Data Mesh
The combination of ETL platform and CDW also underpins the data mesh approach. Individual experts use those technologies to deliver quick value for their specific department. Project scope is deliberately limited to domain-specific needs, rather than also aiming for cross-domain consistency. Consequently, mesh data architectures tend to be two-tier in nature. Attempts to produce insights that span more than one domain are likely to come up against the politics of polysemes, which I will discuss in another article.
Regardless which of the above two approaches is chosen for data integration, there are two information boundaries:
- Source data → Intermediary
- Intermediary → Consumer
In the next article I will look at the factors involved in building an information system which spans those two boundaries.

Ian Funnell
Data Alchemist
Ian Funnell, Data Alchemist at Matillion, curates The Data Geek weekly newsletter and manages the Matillion Exchange.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: