- Blog
- 11.01.2019
Data Self-Service: 5 Steps Toward Implementing It (Plus a Bonus Step)

Every business today is looking for faster time to insight, in order to rapidly make decisions, innovate faster, get to market more quickly, and other competitive advantages. We know that transforming and analyzing data in the cloud can significantly speed up time to insight.
Limited data access is a barrier to insight and innovation
However, even leveraging the cloud, there are still barriers to fast information. At most companies, executives and line-of business teams still need to rely on IT for the most basic access to data and insights. According to a recent survey by Matillion and IDG Research, more than half of respondents said that lines of business rely on IT or data teams to build and set up BI and analytics dashboards, versus handling these tasks themselves.
(In fact, respondents who work on data teams put that number closer to 70 percent. Make of that what you will.)
The point is, at most companies, employees do not have direct access to data or to the tools that help them analyze their data. For many businesses, and definitely for many Matillion customers, data self-service is the next milestone in achieving rapid time to insight and real-time business agility.
What is data self-service?
With data self-service, the aim is to empower business users and decision makers at all levels to use available data to do their jobs effectively. This can take multiple forms:
- Regular users with access to predefined reports and dashboards
- Power users or content creators with the autonomy to build reports and dashboards as needed
- Business analysts and data scientists who have complex needs around data modeling, exploration, and analysis
Moving to data self-service can be challenging
But whether giving increased data access to new users or helping traditional data users achieve more advanced analytics tasks, the goal is the same: More people with agency to quickly get the information they need, without submitting a ticket or waiting in a backlog.
Sounds like a dream for many business users. But for IT and the enterprise, data and analytics self-service presents several challenges, including:
- Acquiring data from a multitude of sources, often numbering in the hundreds
- Handling a variety of data formats, both structured and semi-structured
- Finding sufficient storage to hold rapidly increasing volumes of data
- Harnessing enough power and ability to process large volumes of data
- Making data accessible from anywhere, anytime
- Ensuring consistent data quality
- Implementing security controls and governance needed to meet corporate and government requirements
- Providing the right tooling for BI and analytics
- Conducting thorough end-user training so data users can be truly self-sufficient
Businesses must give thought to all of these challenges as they consider democratizing data across the organization. It can be daunting. But there is a way to systematically move through challenges as you move toward data self-service. Here are five steps (plus one pre-step) that can help you organize your data self-service initiatives.
Step 0: Move data to the cloud
The pre-step to the other five steps is this: to do data self-service right, consider moving your data from an on-premises data warehouse to the cloud.
Why? Many obstacles to achieving data self-service are related to infrastructure and the inability to use data quickly and in a cost-effective way. On-premises data architectures often come up short when trying to handle the sheer volume and complexity of data we see today, especially within a practical budget.
A cloud data warehouse does a good job of addressing two of the biggest requirements for data self-service:
- The need to store enormous volumes of data, and
- The need to rapidly provision and scale infrastructure on demand
Both of these things will unshackle your organization from the limitations of an on-premises infrastructure. The cloud offers the flexibility and scalability you need to explore and analyze your data when, where, and how you need. Which cloud environment you choose depends on the needs and requirements of your business. But any data self-service initiative should start with seriously considering a move to the cloud, or expanding your cloud presence if you’re already there.
What does a modern cloud data analytics architecture look like?
A modern cloud data analytics architecture will look something like the image below:
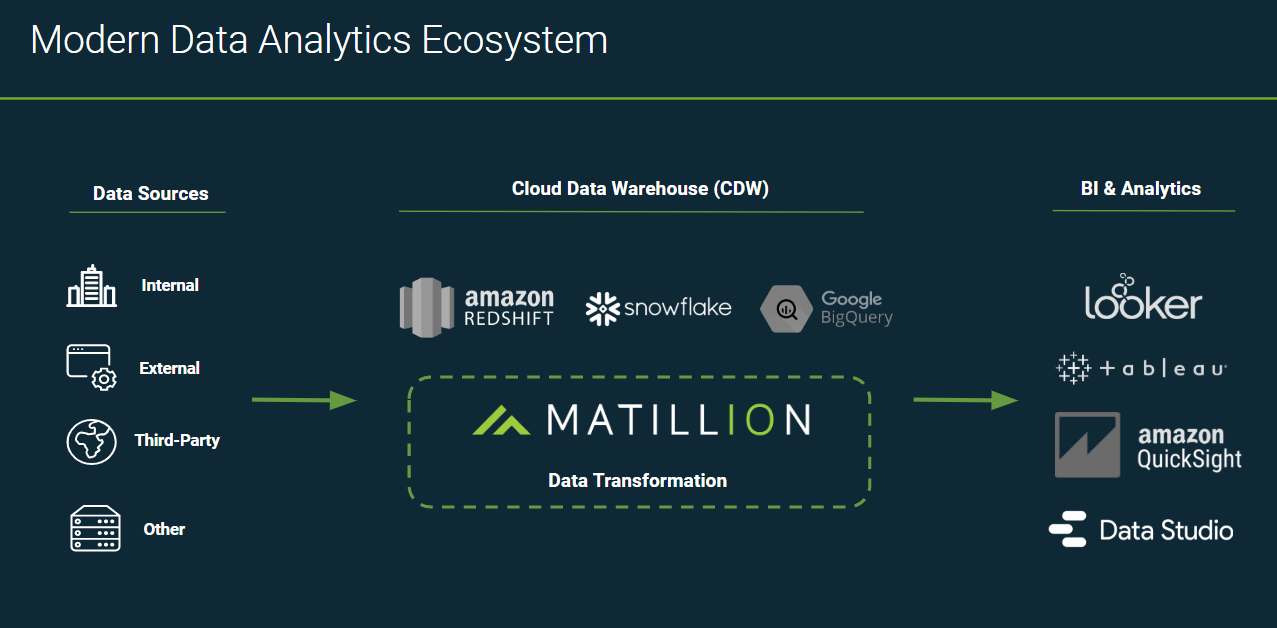
On the left, you have your data sources: Data will be both structured and semi-structured. It will reside both on-premises and in the cloud (for example, in a SaaS application). In the middle, you have your cloud data warehouse, where you will bring data in from those data sources. Matillion, which is cloud-based, can handle your data loading and transformation with speed and simplicity, at scale. On the right, you have your data analytics and visualization tools, which end users will use to pull in the transformed data that they need to create their own reports and dashboards.
Step 1: Build a data and analytics strategy
First things first: you need a comprehensive plan where you ask and answer several important questions involving end users, governance, and the goals of your organization. For more information on these questions, read our blog post, Establishing Data Self Service: 4 Questions You Need to Ask.
Step 2: Choose where you will put your data
In order to facilitate data self-service, you need to break down silos between data sources and bring data into a centralized location. If that location is the cloud, there are a few choices of how that will look. In moving data to the cloud, you will need to focus on three things:
- Data acquisition
- Preparation and transformation
- Storage
Considerations when choosing a cloud data environment
In determining where and how your data will reside in the cloud, there are many factors that come into play. Here are some considerations:
- Will a cloud data warehouse or a data lake best suit your needs? Sometimes compliance or regulatory requirements will guide or dictate your choice.
- How important is familiarity? For example, Amazon Redshift is based on PostgreSQL 8.0.2. A company operating an on-premises PostgreSQL data warehouse be more comfortable moving to Amazon Redshift, since they share many aspects due to common ancestry.
- What cloud platform/vendor services do you already use? Choosing a cloud platform related to your existing services may make it easier to trust, land, and expand. For example, many customers subscribing to Google Analytics 360 can export their Google Analytics data into Google BigQuery for free. Organizations that use Microsoft products may find it easier to operate in Microsoft Azure.
- Sometimes a vendor offers a clear differentiator, which in itself could be a winner. For example, if your company that needs to share data with multiple third parties in a safe and secure manner, Snowflake’s data sharing feature may appeal to you.
Cloud architectures to consider
When bringing data into the cloud, you have three main choices of cloud architectures to choose from. Again, what’s best for you, depends on your business.
Infrastructure as a service (IaaS) is a bare-bones cloud infrastructure from a cloud provider – for example, AWS, Google Cloud, or Microsoft Azure. It allows you to set up your own data infrastructure in the cloud to suit your needs. And it also offers the most control. But it can also be a complex choice.
Platform as a service (PaaS) is a managed service that sits inside a cloud infrastructure – examples include certain cloud data warehouses or an Amazon S3 bucket. A PaaS is a well-defined service that gives you scalability and also lets you retain some control. Choosing a matching platform within your existing cloud service can reduce maintenance and overhead. But depending on your cloud infrastructure, your choices might be limited.
Software as a Service (SaaS) is an end-to-end managed service with little or no maintenance or overhead. Examples include Domo and Sisense. A SaaS platform lets you focus on business needs and not worry about maintaining a tech stack. But you have the least amount of control over factors such as security and how data is stored.
It’s not necessarily a choice between IaaS vs. PaaS vs. SaaS. You may prefer a mixed model with some of each.
Step 3: Choose your BI and analytics tools
After choosing the platform that will hold your data, consider your BI and analytics tools. As with the data platform, analytics infrastructures and tools be structured in different ways, depending on IaaS, PaaS, and SaaS.
Depending on the choices you make, you may be able to continue to use some or all of your existing ETL/reporting/analytics tools. But moving to the cloud allows you to explore newer technologies and products that align better with your data analytics needs and your future strategies.
IaaS
Within an IaaS, you could move your existing analytics structure into the cloud. End-users may see improved performance due to changes in topology as well as any infrastructure-related upgrades that were carried out as part of this move.
PaaS
Sometimes, on-premises services can be replaced with equivalent or similar PaaS cloud offerings. For example, if you move to a CDW like Amazon Redshift,, Snowflake, or Google BigQuery, you may be able to load a CDW database driver into your reporting platform and continue to use your existing investments. Or, you could have an ELT process that loads your file directly into a table in your CDW.
SaaS
Some SaaS offerings come with their own visualization tools. Like PaaS, depending on your choice, you may be able to use existing tools or explore alternatives.
Step 4: Implement and train
Once you select your cloud data and analytics platforms, you’re half done. Next comes the equally important (or possibly more critical) step of implementing your solution and getting your team up to speed.
Implementation and the value of a proof-of-concept (POC)
Before wide-scale implementation, it’s wise to embark on a POC to test the waters. You can try the tools and determine whether they meet your requirements.
As with any project, It’s important to have the right skills and experience to get the best ROI. Many companies with in-house technical teams tend to carry out the POC themselves. This involves:
- Researching the technologies
- Learning to use them
- Building a minimum viable product
The benefit of an in-house POC effort is that it gives your internal teams firsthand experience with the tools, the learning curve and suitability for the job.
Also consider approaching a technology partner who specializes in the chosen platforms and tools. It will cost more, but you will benefit from the partner’s extensive experience in implementing similar systems.
Train your organization’s members to help themselves
Training is the other critical aspect of a successful implementation. Many users in your organization will have limited or no experience with running their own analytics and creating their own data visualizations. Set aside ample time to train them. Even if you think users have experience and will quickly get up to speed, training on new tools and processes benefits everyone.
Step 5: Build a support structure
Every self-service initiative needs a well defined support structure. . Every user needs a clear path to get help if needed. There are two types of support:
- Support for products and tools. This can be relatively easy to put in place. Most vendors have robust support offerings available for a subscription. Most noteworthy and popular open source products tend to have active user-forums or paid support. If you have a technical partner, they may also step in to fill any gaps.
- Business process support. This support is equally important and needs careful consideration. It’s nearly impossible to train an end-user for every eventuality or requirement they may encounter. For example, a user may need information that is not available in their daily dashboard . To create an ad-hoc report, they need to understand the underlying data model to be able to make effective use of it. A power user of the tool could be on standby to help in such a case.
Establishing a self-service data analytics platform can be a daunting task – especially if you need to modernize your data architecture to do it. However, considering how much you can improve time to insight for your entire organization, and the quality of those insights that leverage all of your structured and semi-structured data, it’s well worth the effort. Just remember:
- Take the process step by step
- Lean on the expertise of your IT and data teams and your partners
- Use the right tools to help you get data into the cloud and ready for analytics
- Choose ELT, analytics, and visualization tools that are graphical and intuitive for end users
If you follow the steps and keep these things in mind, you will be on your way to making data accessible to every person in your organization who needs it.
Curious how Matillion ETL software can help you democratize data at your organization? Get a demo.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: