Data Engineer’s Guide to AI Prompt Engineering - 1

Building AI-Powered Data Pipelines: Labelling Unstructured Job Title Data for Efficient Lead Processing
In the age of AI and data, businesses are constantly seeking ways to improve their data management processes, making them more efficient and productive. At Matillion, we have been exploring the potential of Large Language Models (LLMs) to revolutionise data transformation, and we are excited to share our findings with you.
My name is Julian Wiffen, Director of Data Science for the Product team at Matillion. In this series of blogs, we will delve into the fascinating opportunities that LLMs present for comprehending semi and unstructured data. The first instalment focuses on a pervasive challenge that has troubled Marketing and Demand Generation teams for years: unstructured job title data. This is an excellent example to explore how AI-powered data pipelines, specifically Matillion’s Data Productivity Cloud, can address this issue.
Challenges of Unstructured Job Title Data
One of the core challenges faced by data teams is dealing with the wide variation in job titles, especially when collected from free text fields. Acronyms and abbreviations abound. Job titles can range from common acronyms like "BI Analyst" to more elaborate versions like "Business Intelligence Manager." These variations make it challenging to standardise and categorise job titles efficiently. Historically, attempts to standardise these titles have been manual and labour-intensive, building up mapping tables based on a human making judgement calls and regex expressions is time consuming. This painstaking approach often proves inefficient, especially when faced with rapidly evolving job titles and dynamic business landscapes.
The Role of Large Language Models
LLMs have emerged as a game-changing technology in the realm of data transformation. Their ability to understand and categorise text data is a revolutionary development, and here's why they play a crucial role in AI-powered data pipelines: LLMs bring automation to the classification of unstructured data, significantly reducing the manual effort and time required for data transformation. They excel at handling the variability in data, recognizing semantic similarities and differences in job titles, acronyms, and language differences. LLMs are known for their speed and efficiency, capable of processing large volumes of data rapidly, ideal for real-time data pipelines.
Integrating LLMs into data pipelines is made easy with solutions like Matillion's Data Productivity Cloud, offering a competitive advantage in the data-driven landscape. As we explore this use case further in this blog series, you'll gain a deeper understanding of how LLMs come to the rescue by providing the basic reading comprehension needed to automate this process. They can classify job titles into predefined categories, streamlining the entire process. While manual classification is an option, it still requires significant effort to transform the output into usable data for further processing.
You can see what happens when you ask ChatGPT to classify a job title into one of a list of values:
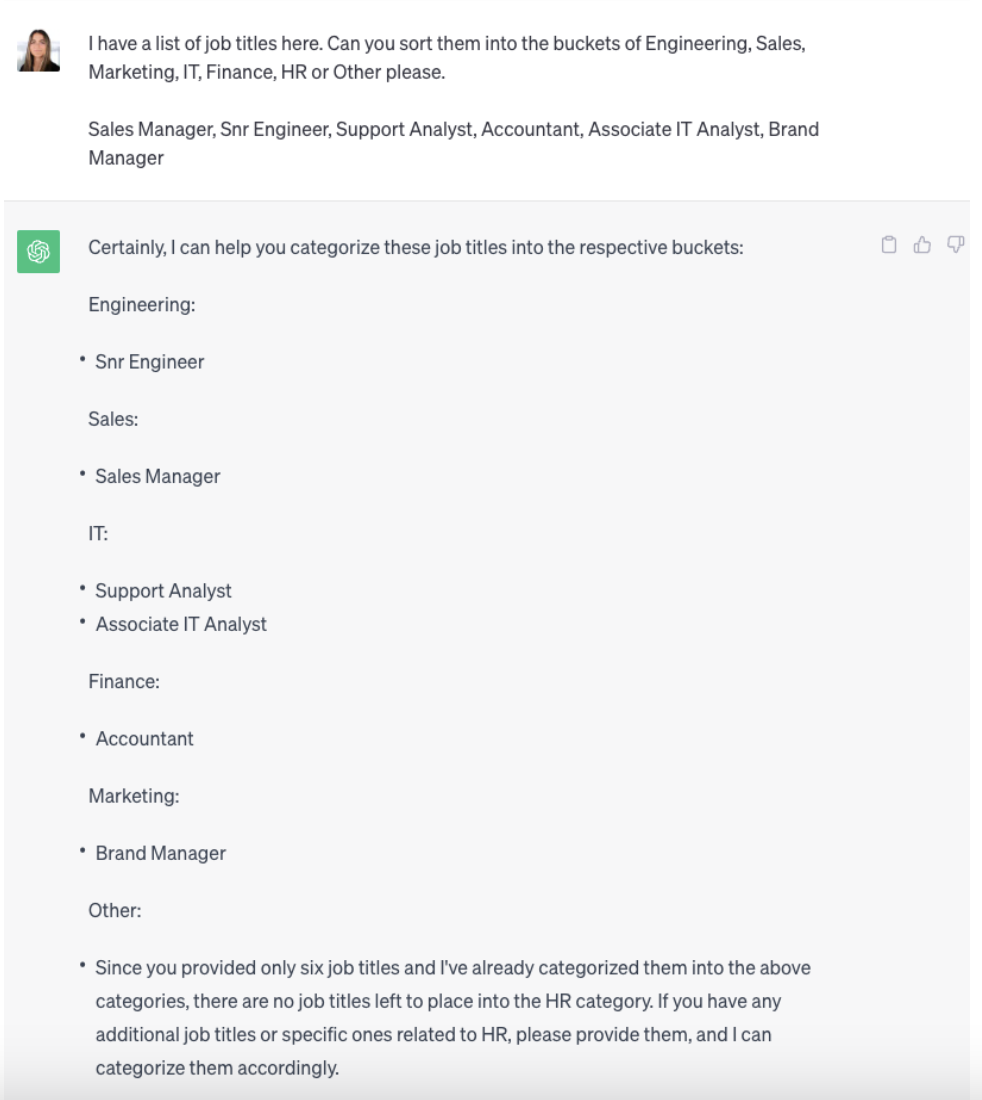
ChatGPT 3.5 has done an excellent job of classifying the job titles into the categories we specify. Doing this manually within the chat User Interface (UI) is an option but then still requires work to transform the output into something we can use in a data transformation job.
Building AI-Powered Data Pipelines
Matillion's Data Productivity Cloud introduces a powerful solution for this problem. We have developed a proof concept component within our Data Productivity cloud that can call the APIs for OpenAI, AzureAI and AWS Bedrock LLMs to ask questions directly within a data pipeline.
Here's how it works:
- We start with a list of job titles, including various languages and unconventional titles.
- The Data Productivity Cloud's prompt component is configured with a set of questions to ask the LLM about each job title.
- The LLM's responses are then written to a new table.
Let’s dive in:
We set up our example list of job titles, including some of the curveballs you often get with a free text field.

In this case, it turns out that many attendees at the conference we attended gave answers in a range of languages. A little work with Google translate could tell us that Praktikánt means intern, Datenwissenschaftler is Data Scientist, Informaticien means programmer, Jefe de inteligencia de negocios is Head of Business Intelligence.
However, we’re not going to bother giving those translations to the LLM as it can handle a variety of languages. We are going to feed this list to our prompt component within the Data Productivity Cloud. The component is configured with a set of questions it is going to ask the LLM about each line of data in the table it receives, then write the responses out to a new table.
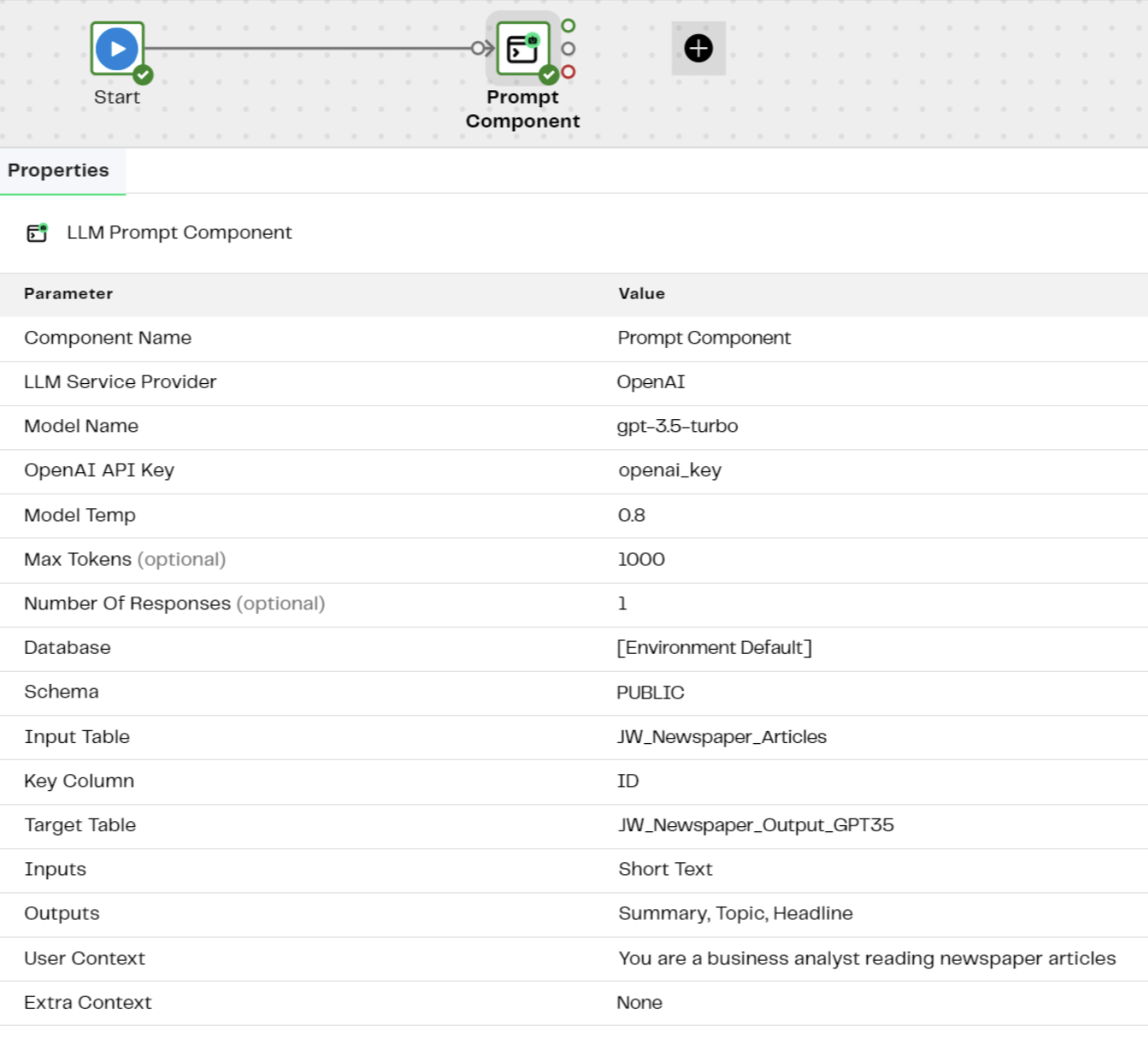
There are a range of parameters that are configured here. In this example, we are connecting to Microsoft’s AzureAI models, using a GPT-3.5 model. The User Context and Outputs are the most important pieces here that we can configure and play crucial roles in this process. The User Context provides background information, while the Outputs specify the questions you want to ask about each job title.
The User Context sets the general background:

The second line is an important piece — we just want the LLM to give a simple answer, without it elaborating or explaining why, because we want that answer to be something that is easy to work with downstream in the pipeline.
The Outputs are the specific questions we want to ask about each job title in turn, for example:
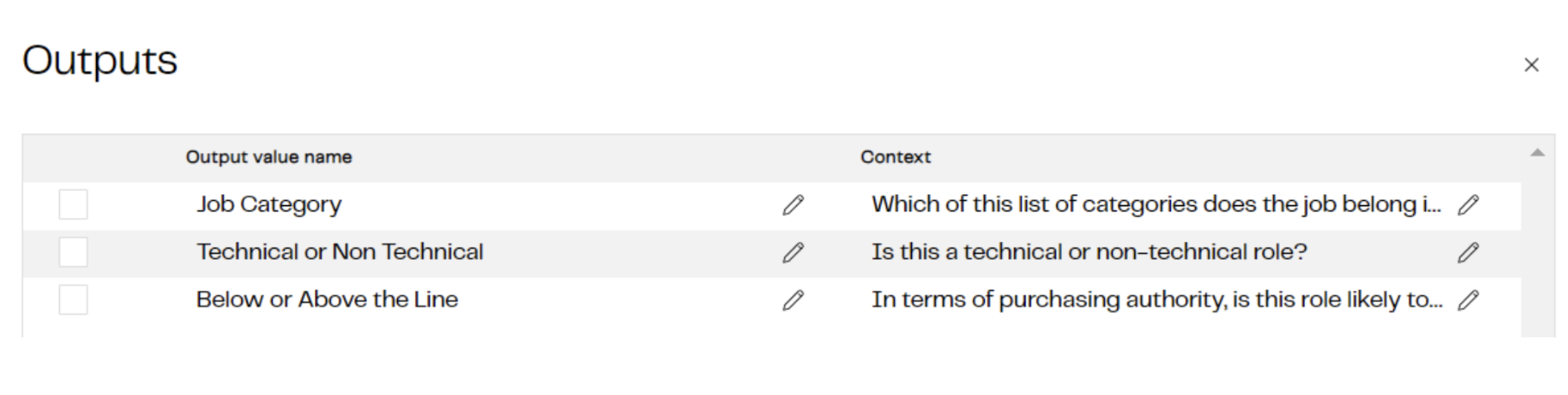
- Job Category: Which of this list of categories does the job belong in - sales, engineering, finance, HR, supply chain, IT, marketing, executive
- Technical or Non Technical: Is this a technical or non-technical role?
- Below or Above the Line: In terms of purchasing authority, is this role likely to be below the line or above the line?
Our prompt component will assemble these questions, the user context and some standard system instructions, along with the job title from each row, which it then sends off to (in this case) the AzureAI API.
The combined message sent to the LLM looks like the following:
context prompt: You are handling marketing leads from a trade conference Answer each question with just the category selected, do not give reasoning
data object: {"Job Title":"SDR"}
output format: {"Job Category":"Which of this list of categories does the job belong in - sales, engineering, finance, HR, supply chain, IT, marketing, executive","Technical or Non Technical":"Is this a technical or non-technical role?","Below or Above the Line":"In terms of purchasing authority, is this role likely to be below the line or above the line?"}
For that line we got back the following response:
{ "Job Category": "sales", "Technical or Non Technical": "non-technical", "Below or Above the Line": "below the line" }
The results are received in a structured JSON format that can be easily transformed using the Data Productivity Cloud. The job titles are transformed into structured, categorical data, ideal for reporting and lead routing.
The results we get look like this:
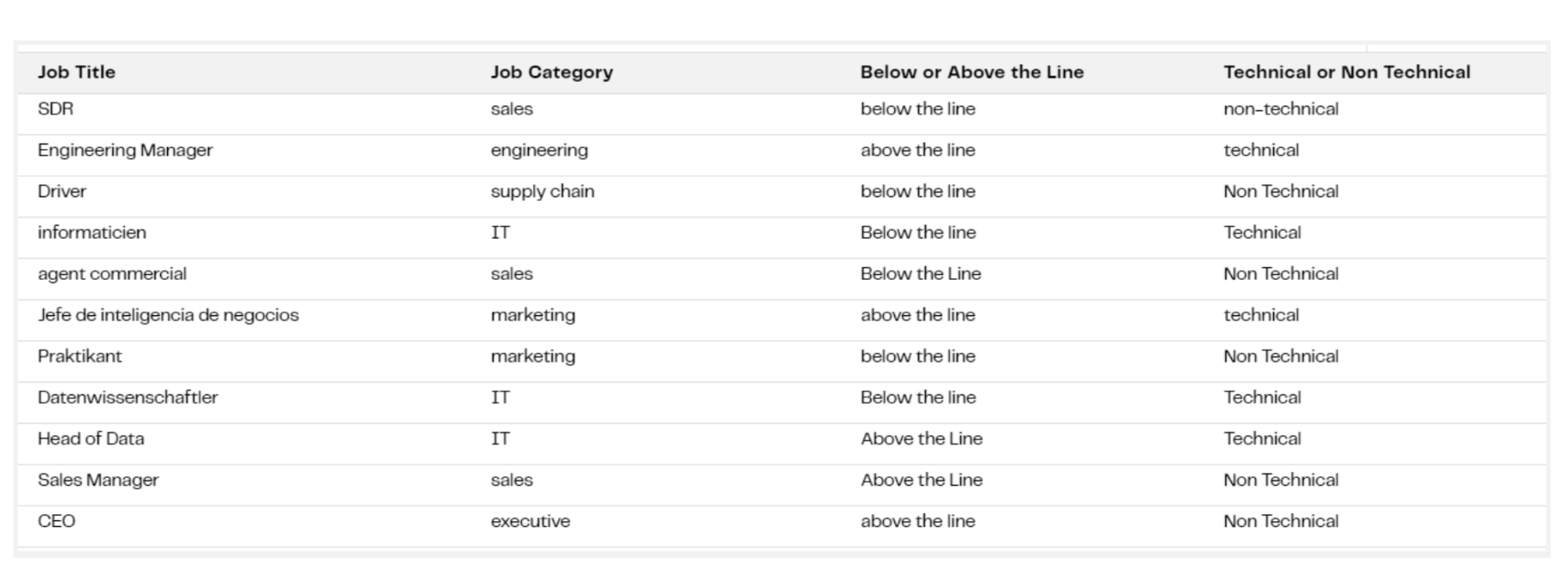
The answers in “Job Category” all match up to values from the list we requested. This has transformed the free text, relatively unstructured data in the job titles into structured, categorical data that can then easily be reported on for business intelligence purposes or used in lead routing rules.
The mappings received all look sensible. The only questionable assignment is mapping “Jefe de inteligencia de negocios”, which is Spanish for ‘Head of Business Intelligence’ to “marketing”, but with the list of categories we allowed, there isn’t a single natural fit for it — marketing is probably as good a guess as any.
While there is some variation in cases, the values for Below or Above the Line, and Technical or Non Technical are consistent enough we can write filter conditions upon them.
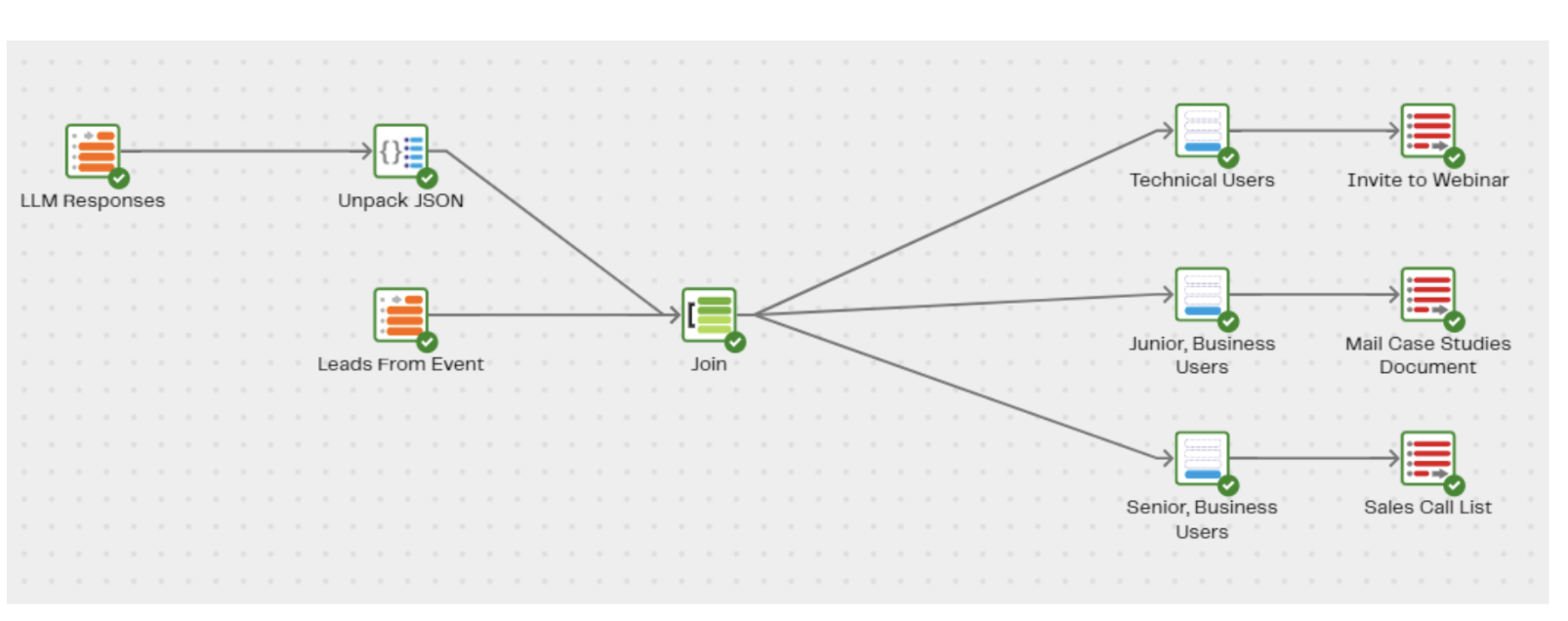
Using the filters we can split the list up into buckets and arrange the most appropriate sales outreach sequences for. The technical roles are perhaps appropriate folks to invite to a ‘how-to’ webinar to demonstrate some of the more technical functionality of our product.

The roles identified as non-technical, we might send the junior ones an email sequence starting with case studies showing how other customers have successfully used our products and tailored to a non-technical audience.

Finally, perhaps those who are both senior and non-technical are passed directly to the sales team to attempt to set up a sales call.

This process streamlines your data, making it suitable for various business intelligence purposes. You can use the categorized data to create sales outreach sequences, technical webinars, email campaigns, and more. LLMs, when integrated into data pipelines, offer a powerful solution for handling unstructured data.
Streamlining Data Transformation with LLMs: A Game-Changer for Data Teams
The LLM has been able to handle the variations in job title, common acronyms, and multiple languages for us with very little effort. It has translated this highly variable input field into something that is simple to report on and easy to use with transactional rules.
We believe having the ability to do this with a data transformation pipeline will provide great utility. It would be easy to continue this use case using our connector to Salesforce, for example, to pass on the recommended outreach approach for each lead. This functionality represents the tip of the iceberg of how using LLMs within a data pipeline allows us to access information that previously was hard to access within unstructured data. Check out the next installment on building AI-powered data pipelines that delves into summarizing, classifying, and filtering large qualities of text.
Want to see this action?
Join thousands of your peers from across the globe to become Enterprise Ready, Stack Ready, and AI Ready. Register for free today to secure your spot in the data-driven future and stay tuned for announcements about our stellar lineup of leaders, influencers, and data experts.

Julian Wiffen
Director of Data Science
Julian Wiffen, Director of Data Science for the Product team at Matillion, leads a dynamic team focused on leveraging machine learning to improve products and workflows. Collaborating with the CTO's office, they explore the potential of the latest breakthroughs in generative AI to transform data engineering and how Matillion can play a pivotal role in supporting the needs of those working with these cutting-edge AI models.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: