- Blog
- 01.16.2024
- Technically Speaking
Large Language Model Performance in Classifying Customer Feedback

Matillions' prior three-part blog series on AI for data engineers delved into integrating Large Language Models (LLM) into data pipelines for classifying and labeling semi-structured data. Now, with various models offered by different providers in the market, our focus shifts to comparing their performance in a unified task. Our primary aim lies in assessing these models’ comprehension accuracy, alongside examining their processing speed and cost.
Within this evaluation, we utilized our Prompt Component within the Data Productivity Cloud to interface with several LLMs:
- Azure gpt-3.5-turbo and gpt-4/preview 1106
- Openai gpt-3.5-turbo and gpt-4
- AWS Anthropic Claude v1, v2, v2.1 and instant-v1
- AWS Meta llama2-13b-chat-v1 and llama2-70b-chat-v1
The Task
We created a set of fake reviews for consumer products. These reviews varied: some conveyed frustration from dissatisfied customers, others highlighted aspects of the product they appreciated or disliked, while a few pinpointed potential issues that could either be actionable defects or suggestions for new features.

The reviews were manually analyzed and flagged with columns to mark:
- Does the customer sound unhappy?
- Is there a call to action in the review?
- Is there a defect highlighted in the review?
- Is there a feature request highlighted in the review?
The reviews were loaded into Snowflake via the Data Productivity Cloud. The flags were set aside to be used later in the scoring process. The reviews alone (without the analyst flags) were sent to each of the LLMs in the test with the following prompt details.
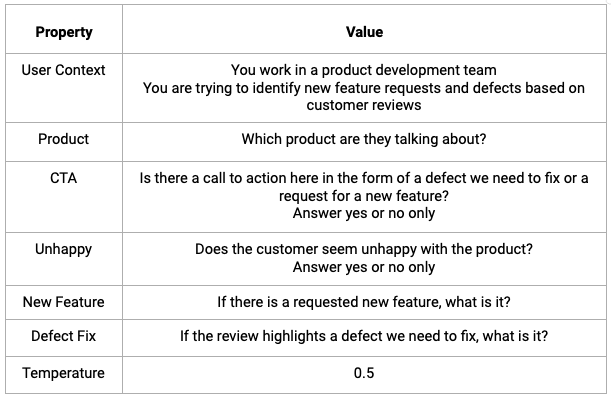
The standard output from this can be compiled within a data pipeline to generate a report, as seen below. This type of outcome is ideal for sharing with product development teams as a comprehensive summary of user feedback.

Scoring
To gauge the response quality within the report and determine the most suitable model, we configured data pipelines in the Data Productivity Cloud. These pipelines posed identical questions to each available model within our repertoire, allowing us to systematically aggregate and assess their responses.

As new models continually enter the scene, we anticipate this process becoming a standard element of Machine Learning Operations. Our goal is to streamline the setup of automated jobs that monitor model effectiveness for specific use cases, facilitating seamless switches between models based on accuracy, cost, and speed.
The scoring job analyzed responses according to the following criteria:
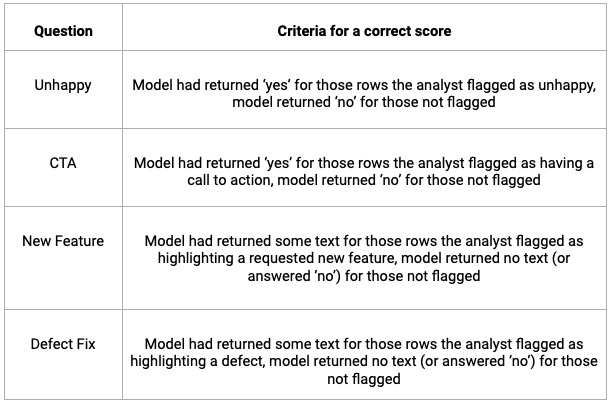
These criteria, slightly simplistic, leave room for a more intricate manual evaluation of responses, particularly regarding new features and defects.
Afterward, the scoring job aggregated the percentage of correctly answered questions for each model based on these criteria.
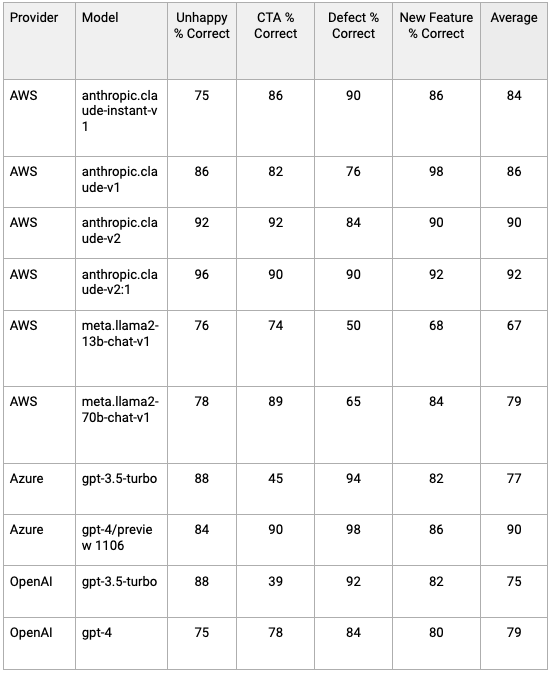
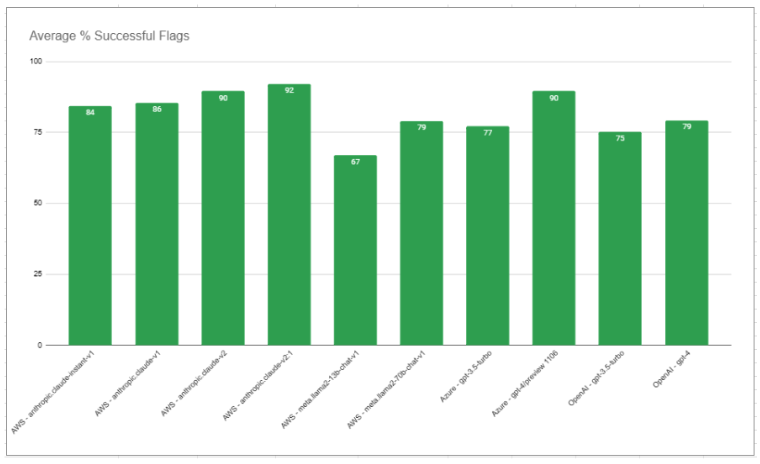
AWS Anthropic Claude-v2.1 emerges as the most effective model for this task, boasting a 92% accuracy rate, narrowly surpassing Azure’s gpt-4 in overall performance.
Measuring Speed
While accuracy is crucial, it’s not the sole determinant. Speed and cost are equally significant. The pipeline metrics from DPC provide insights into the duration taken by each model for the task, along with the number of tokens processed and generated in response.
Notably, with our prompt component, the LLM perceives each row as an individual request. However, it’s important to note that this analysis is conducted on a small dataset comprising 51 reviews. We’ll delve into performance on larger datasets in a subsequent exercise.

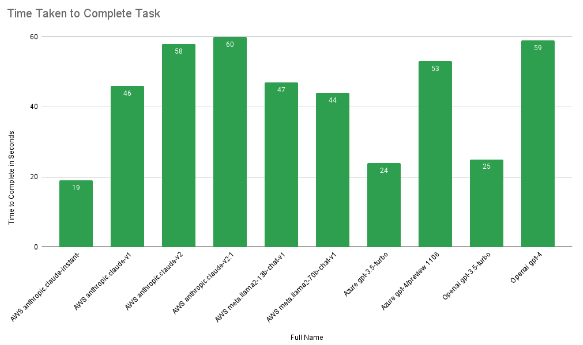
In assessing the models’ performance on the same dataset and prompts, our primary focus is the overall time taken to complete the task, directly correlating to rows processed per second. Claude-instant emerges as the clear frontrunner when prioritizing speed, closely followed by the GPT-3.5 models.
Claude-instant’s impressive 84% accuracy compared to the Azure and OpenAI GPT-3.5 models at 77% or 75% stands out as the optimal choice if speed takes precedence.
Interestingly, while the most accurate model (Claude v2.1) excels in accuracy, it operates slower. Among the high-scoring models (achieving 90%+ accuracy), Azure GPT4 stands out for its swiftness.
Calculating Costs
To factor in pricing, we’ve gathered costs per token from the pricing pages of the three companies as of January 4, 2024. Here are the links for your reference:
- https://aws.amazon.com/bedrock/pricing/
- https://openai.com/pricing
- https://azure.microsoft.com/en-gb/pricing/details/cognitive-services/openai-service/
With this pricing data, we can evaluate the overall cost for the task based on the number of tokens processed by each model.
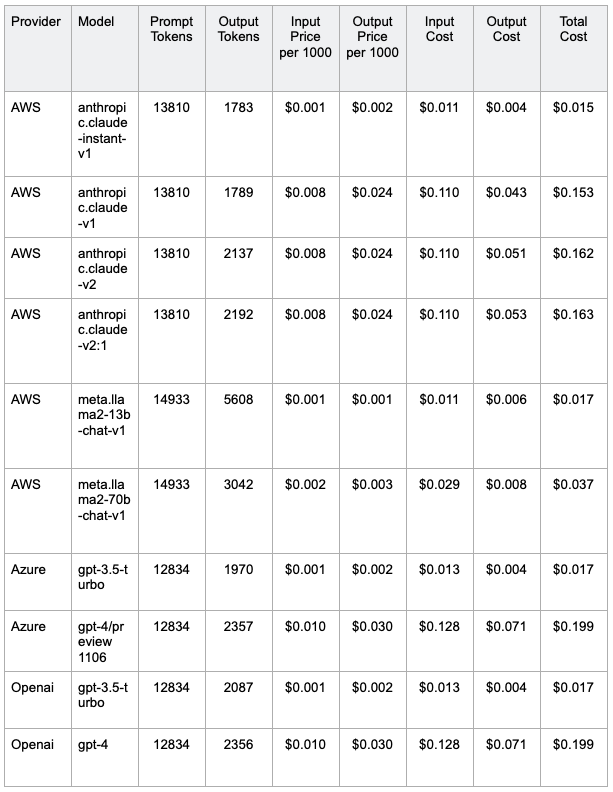

In terms of cost, Claude-instant-v1 is again the winner. Alongside IIama2 and the GPT3.5 models, it showcases significantly lower costs compared to the GPT4 and other Anthropic claude models. Among high-scoring models (90%+ accuracy), Claude v2/v2.1 also presents notably lower expenses than the GPT4 options.
Horses for Courses
There are a lot of trade-off decisions to be made here. Anthropic Claude-instant-v1 is the fastest and cheapest model while retaining a respectable accuracy of 84%. Claude v2.1 is the most accurate, at 92%, but that 8% improvement comes with an 11x increase in cost and a 3x increase in time taken. Deciding the acceptable threshold for accuracy is a key decision for using an LLM within a data pipeline.
It is also interesting that the Azure versions of GPT-3.5 and GPT-4 outperform their OpenAI equivalents for both accuracy and speed, although the comparison between GPT-4/preview 1106 and GPT-4 may not be a true like-for-like comparison.
Overall, depending on the priorities of the business case, for this use case, we get a different best-in-class model for the combinations:

Are you curious to explore further? Experience it first hand yourself!

Julian Wiffen
Director of Data Science
Julian Wiffen, Director of Data Science for the Product team at Matillion, leads a dynamic team focused on leveraging machine learning to improve products and workflows. Collaborating with the CTO's office, they explore the potential of the latest breakthroughs in generative AI to transform data engineering and how Matillion can play a pivotal role in supporting the needs of those working with these cutting-edge AI models.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: