- Blog
- 01.26.2022
Load Parquet Data Files to Amazon Redshift: Using AWS Glue and Matillion ETL
Matillion is a cloud-native and purpose-built solution for loading data into Amazon Redshift by taking advantage of Amazon Redshift’s Massively Parallel Processing (MPP) architecture. Instead of extracting, transforming, and then loading data (ETL), we use an ELT approach. Our method quickly extracts and loads the data, and then transforms it as needed using Amazon Redshift’s innate, clustered capabilities.
Given the wide adoption of Data Lake architectures in recent years, users often call on Matillion ETL to load a variety of file formats from S3, a common persistence layer behind such data lakes, into Amazon Redshift. A popular file format in these use cases is Parquet, which stores data in a columnar format. Such formats offer advantages in data warehouse environments over more traditional, row-orientated files, notably preventing unnecessary I/O for columns you exclude from a given SQL statement’s SELECT or WHERE clauses.
So how do you load Parquet files into Amazon Redshift? There’s a number of ways:
- COPY Command – Amazon Redshift recently added support for Parquet files in their bulk load command COPY. Given the newness of this development, Matillion ETL does not yet support this command, but we plan to add that support in a future release coming soon.
- User-Defined External Table – Matillion ETL can create external tables through Spectrum. Here the user specifies the S3 location of the underlying Parquet files and the data types of the columns in those data files. This creates an entry for the table in an external catalog but requires that the users know and correctly specify column data types.
- Crawler-Defined External Table – Amazon Redshift can access tables defined by a Glue Crawler through Spectrum as well. Using this approach, the crawler creates the table entry in the external catalog on the user’s behalf after it determines the column data types. Once that’s done, table data can be accessed similar to the User-Defined External Table approach above, the only difference being that the data types were defined by the crawler rather than the user.
This article is about how to use a Glue Crawler in conjunction with Matillion ETL for Amazon Redshift to access Parquet files. Here we rely on Amazon Redshift’s Spectrum feature, which allows Matillion ETL to query Parquet files in S3 directly once the crawler has identified and cataloged the files’ underlying data structure. Now let’s look at how to configure the various components required to make this work. The basic steps include:
- Storing Parquet Data
- Creating a Database
- Defining a Table
- Creating an External Schema
Storing Parquet Data
There are a number of ways to create Parquet data, which is a common output from EMR clusters and other components in the Hadoop ecosystem. I’m working with a Civil Aviation dataset and converted our standard gzipped .csv files into Parquet format using Python and Apache’s PyArrow package (see here for more details on using PyArrow).
Note that Amazon Redshift Spectrum can utilize partition pruning through Amazon Athena if the datafiles are organized correctly. By naming nested S3 directories using a /key=value/ pattern, the key automatically appears in our dataset with the value shown, even if that column isn’t physically included in our Parquet files. These values correspond to partitions and subpartitions. WHERE clauses written against these pseudo-columns ignore unneeded partitions, which filters the record set very efficiently.
In this case, I instructed PyArrow’s parquet.write_to_dataset method to use partition_cols of Year and Month, resulting in a dataset with the following physical layout:
flights
|– Year=1987
| |– Month=10
| | `– 93fbcd91619e484a839cd8cb2ee01c0d.parquet
| |– Month=11
| | `– 880200429a41413dbc4eb92fef84049b.parquet
| `– Month=12
| `– 71c5e94b826748488bd8d7c90d7f2825.parquet
|– Year=1988
| |– Month=1
| | `– 44ea1fc894334b32a06e5d01863cca55.parquet
| |– Month=10
| | `– 21425bccf2204ac6aa084c0c3f11d76c.parquet
| .
| .
| .
| |– Month=8
| | `– a9dac37fa3ee4fa49bb26ef69b486e5c.parquet
| `– Month=9
| `– 9aab1a66f7f44c2181260720d03c3883.parquet
Creating a Database
With the directory structure described above loaded into S3, we’re ready to create our database. This can be done using a CREATE DATABASE command in Amazon Athena, or more simply by clicking the Add Database button inside Amazon Glue.

Defining a Table
With a database now created, we’re ready to define a table structure that maps to our Parquet files. This is also most easily accomplished through Amazon Glue by creating a ‘Crawler’ to explore our S3 directory and assign table properties accordingly.
To do this, create a Crawler using the “Add crawler” interface inside AWS Glue:
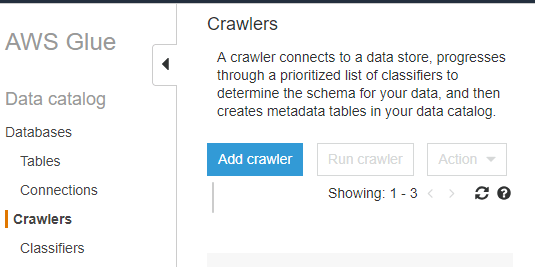
Doing so prompts you to:
- Name your Crawler
- Specify the S3 path containing the table’s datafiles
- Create an IAM role that assigns the necessary S3 privileges to the Crawler
- Specify the frequency with which the Crawler should execute (see note below)
- Last, you’ll need to tell the Crawler which database you’d like the table to reside in
Note: For cases where you expect the underlying file structure to remain unchanged, leaving the “Frequency” at the default of “Run on demand” is fine. Executing the Crawler once is sufficient if the file structure is consistent and new files with the same structure can be added without requiring a re-execution of the Crawler itself.
With all that complete, you can select your newly created Crawler and run it. This will create a table with the correct column definitions in the database you specified. Once complete, you can query the Parquet files through Amazon Athena or through the Amazon Redshift Spectrum feature, as discussed next.
Creating an External Schema
Creating an external schema in Amazon Redshift allows Spectrum to query S3 files through Amazon Athena. We cover the details on how to configure this feature more thoroughly in our document on Getting Started with Amazon Redshift Spectrum. To summarize, you can do this through the Matillion interface. First, navigate to the environment of interest, right-click on it, and select “Create External Schema.”
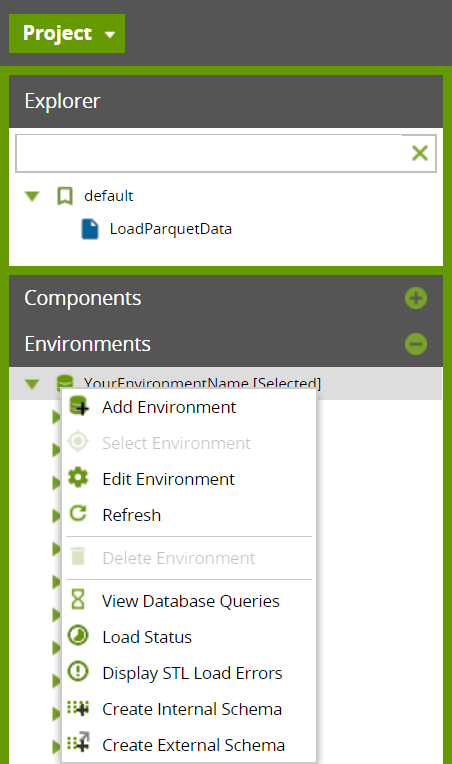
This will open a dialog box that prompts you to enter a name for the External Schema you’d like to create. You’ll also need to specify the Data Catalog, which is the database you created through Glue in the previous steps. Last, you’ll need to tell Amazon Redshift which Role ARN to use. Details on creating a role with the necessary privileges can be found in this IAM Policies for Amazon Redshift Spectrum document.
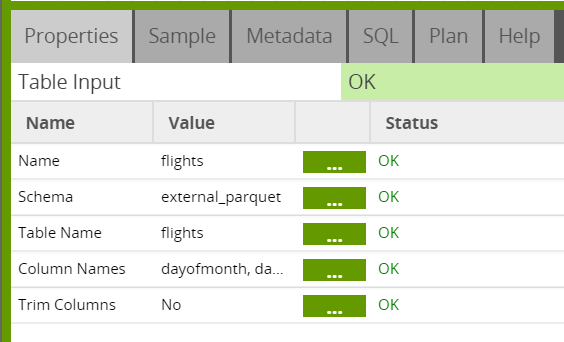
After clicking “OK,” Matillion ETL will create an external schema and you’ll have access to your Parquet files through the usual Matillion input components. For example, you can use a Table Input component to read from your Parquet files after you specify the Schema property with the external schema just created and the Table Name property with the table name created by the Glue Crawler as described above.
Also note that by using a SQL component and a query like this:
SELECT *
FROM external_parquet.flights
WHERE year = 2002
AND month = 10
We can leverage the partition pruning previously mentioned and only query the files in the Year=2002/Month=10 S3 directory, thus saving us from incurring the I/O of reading all the files composing this table.
Conclusion
By following the steps laid out in the discussion above, you should be able to access Parquet files using Amazon Glue and Matillion ETL for Amazon Redshift. Once you load your Parquet data into S3 and discovered and stored its table structure using an Amazon Glue Crawler, these files can be accessed through Amazon Redshift’s Spectrum feature through an external schema. From there, data can be persisted and transformed using Matillion ETL’s normal query components. This allows you to leverage the I/O savings of the Parquet’s columnar file structure as well as Amazon Athena’s partition pruning.
Useful links
Apache Parquet
Cataloging Tables with a Crawler
Amazon Athena
Getting Started with Amazon Redshift Spectrum

The post Load Parquet Data Files to Amazon Redshift: Using AWS Glue and Matillion ETL appeared first on Matillion.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: