- Blog
- 09.08.2022
Matillion ETL support for Amazon Redshift Serverless delivers more productive data integration at scale
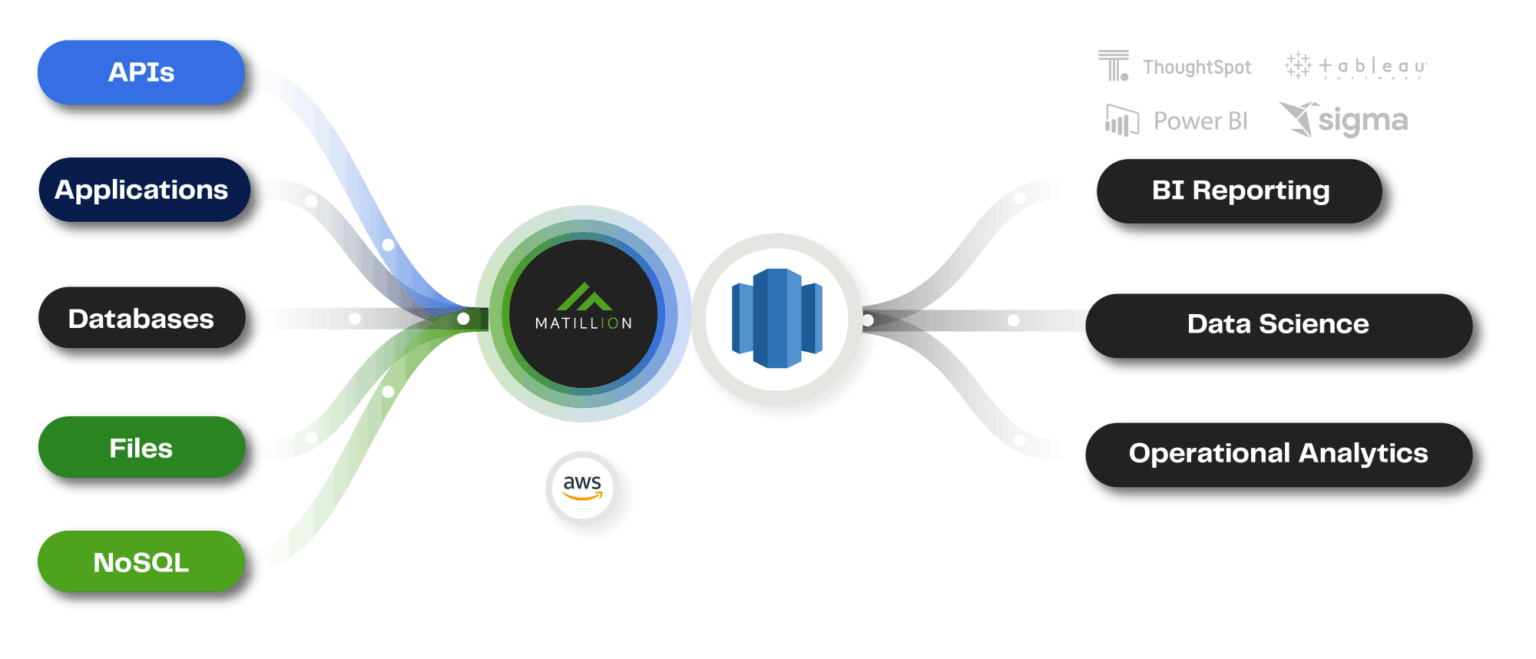
AWS recently announced the release of new serverless offerings to help organizations simplify the management of their data and analytics environments. Amazon Redshift Serverless enables customers to run high-performance data warehousing and analytics workloads on petabytes of data without having to manage a data warehouse infrastructure.
The new serverless service simplifies the management of an organization’s Amazon Redshift platform by automatically provisioning and intelligently scaling data warehouse capacity, enabling faster performance for the most demanding and unpredictable workloads. Organizations no longer have to worry about setting up and managing clusters, so no administration of the infrastructure, and they only pay for what they use.
Out-of-the-box support for data integration and transformation with Matillion
You can use Matillion ETL for loading data from different sources to Amazon Redshift and make sure that the data is in an analytics-ready state – i.e. teed up for your BI applications, AI/ML models, and any other portals, applications, reports, etc. that your data consumers need. Matillion ETL simplifies this process by orchestrating the loading of data into Amazon Redshift from virtually any data source and then helps you transform that data within Amazon Redshift into meaningful insights, all with its easy-to-use low-code/no-code interface.
Built from the ground up for Amazon Redshift, Matillion ETL works out-of-the-box with Amazon Redshift Serverless, ensuring that current and future customers who want to use the serverless option will not face any undue obstacles. “We believe that our customers demand two things when it comes to their data platform - productivity and scale. Matillion’s support for Amazon Redshift Serverless delivers on both” said Ciaran Dynes, Chief Product Officer for Matillion. “Simply choose your Amazon Redshift Serverless agent from the drop-down menu inside Matillion ETL, and you are done. It’s that easy to scale your data analytics”
"With Redshift Serverless, customers can easily run and scale analytics without provisioning and managing data warehouse clusters. Simply point the application to the Serverless end point and start running analytics to get insights from data in seconds," said Yan Leshinsky, Vice President, Amazon Redshift at AWS. "Customers only pay for the compute capacity used to process the workload on a per-second basis. No changes necessary for existing analytics and business intelligence applications."
Begin your data journey now with Matillion
Want to learn more, or ready to get started? Get a Demo to Learn more or Get Started with a Free Trial
Andreu Pintado
Featured Resources
Best Practices For Connecting Matillion ETL To Azure Blob Storage
Matillion makes data work more productive by empowering the entire ...
BlogHow to Choose Your GenAI Prompting Strategy: Zero Shot vs. Few Shot Prompts
Large language models (LLMs) produce output in response to a natural language input known as a prompt. The prompt contains ...
BlogEnabling DataOps With Data Productivity Language
Discover how Matillion leverages Git and the Data Productivity Language (DPL) to enable seamless implementation of DataOps ...
Share: