- Blog
- 02.09.2022
- Data Fundamentals, Dev Dialogues
The Best Way to Make a Contingency Table in Matillion ETL
In this article I will show you how to use Matillion ETL to create a Contingency Table from a large set of input data. It will be part of an investigation into the relationship between domestic flight delays and federal observed holidays. So this contingency table will be a highly aggregated summary by volume for those two categorical variables.
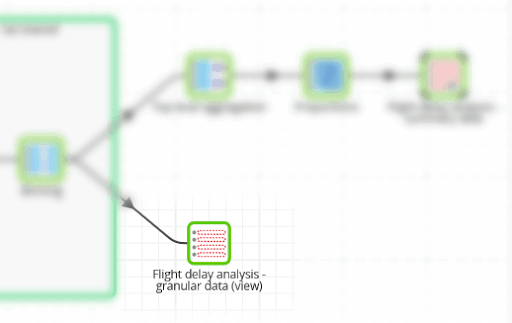
The finished Matillion ETL job is shown below. You can download it from here to follow along on your own Matillion ETL instance.
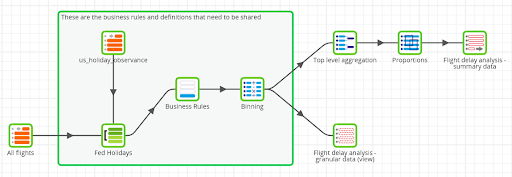
To begin with I have data points from several million domestic flights. My first goal is to aggregate them in order to search for any patterns.
As a secondary goal, and for the purposes of internal alignment, I intend to share my working. The rules are not that complex, but nevertheless it is part of a good data culture to share and reuse derivations where possible.
What is a contingency table?
A Contingency Table is a crosstab of counts by two categorical variables. In this article they are:
- Holiday – true or false, showing whether the flight departed on a federal holiday
- Lateness – which I will bin into three values: “On Time”, “Medium Delay”, or “Large Delay”
The definition of “lateness” deserves some explanation. The Federal Aviation Administration takes 15 minutes as the boundary after which a flight is considered to be delayed. There is a second boundary at 45 minutes for longer delays. I will use this as the cutover from “Medium Delay” to “Large Delay”.
Scheduled and actual flight arrival times are published by the Bureau of Transportation Statistics. Like all incoming data, it is sometimes a little messy and incomplete: it has a few consumability issues. For this data especially, dates and times are occasionally missing or unreadable.
So the first task is to calculate the two categorical variables, using holiday information and time boundaries. The solution must be able to deal with all the dates and times even if they are missing or unreadable. This logic is known as the business rules that are applied to the data.
After that, the solution must aggregate by those two categorical variables, and share the outputs.
Business rules and aggregation
In the Matillion ETL job, I have a note around all of the business rule implementations, to make them stand out in the generated documentation. The incoming data volume is shown in the sample row count.
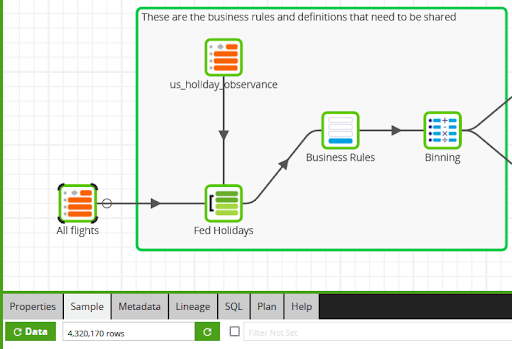
Adding a true/false holiday flag is straightforward. It is done with a left join component to a reference table containing all holiday observances.
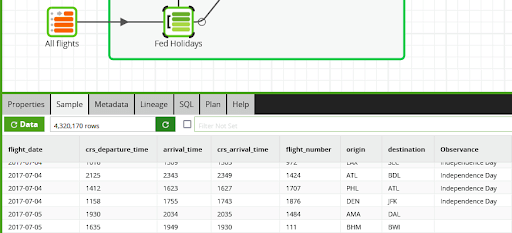
In the next screenshot you can see some fight records that are on a holiday and some that are not. The data sample also confirms that the join did not alter the row count.
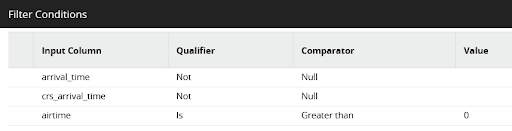
To deal with the quirks, a filter excludes records that do not have both a scheduled and actual arrival time. It also ignores records that were recorded with a zero or negative airtime.
To apply the binning, a second business rule performs calculations on the times, including:
- Work out the number of minutes between two times expressed as integers. For example, the difference between 1815 and 2031 is 136 minutes, not 216.
- Correct for flights where the scheduled and actual arrival times fell on different days
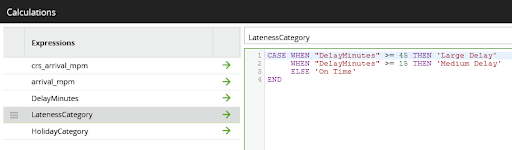
- Use a CASE statement to bin the delay into the three possible categories
The rules are implemented using a Calculator component like this:
Once both of the categorical variables are in place, the data can be summarized. An aggregate component groups the values first. I intend to draw a stacked bar chart using R, so a window calculation component helpfully adds the holiday category totals. Lastly, a rewrite component saves the data to a small new table for export.
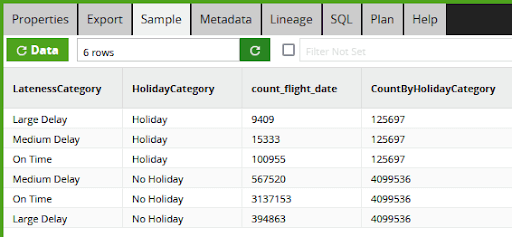
From the sample tab of the last component you can see how the four million input records have been aggregated down to just six records. It is not a crosstab yet, but this is the data that will appear in the contingency table.
Internal alignment
If I share nothing but this highly aggregated data, my colleagues will be able to see the output of this particular analysis, but they will not be able to do much else with the data.
One wasteful thing that could happen is if my colleagues try to do their own “flight lateness” analysis from the same input data, and spend their time recreating the same business rule implementations.
Even worse, if they used slightly different rules, they would end up with different results! Whenever you see reports from different departments showing what is supposed to be the same metric – but the counts do not add up – then this is probably how it happened.
To help you avoid that, I have also shared the granular data, which includes all of the derived fields. That is the purpose of the second output component. It is implemented as a view so it consumes no space. Furthermore, access can be governed in the same way as for all other database objects.
Visualizing the contingency table
The data from the transformation needs to be cross tabulated to form an actual contingency table. Using R you can do it like this:
df$Proportion <- df$count_flight_date / df$CountByHolidayCategory
ct <- xtabs(Proportion ~ LatenessCategory + HolidayCategory, df)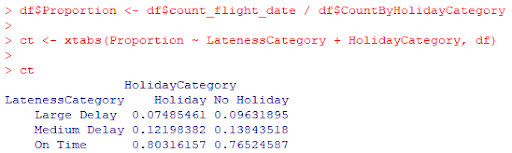
Then plot the results visually, like this:
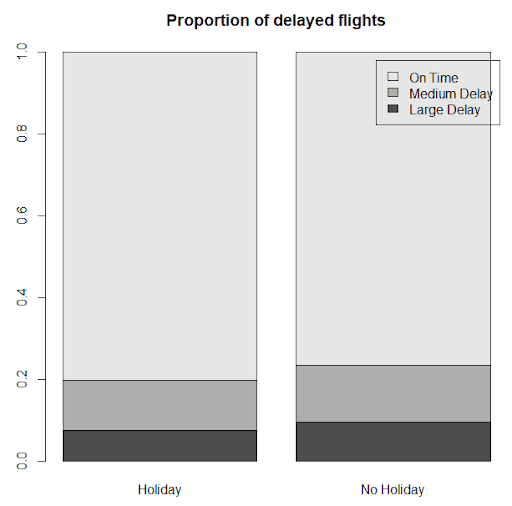
Contrary to what I would have guessed, the proportion of delays is slightly lower on federal observed holidays. Perhaps it is because – on average overall – there are slightly fewer flights on those days.
To check if the result is statistically significant would require a chi-square test. Read here for a walkthrough that demonstrates how to prepare, run and interpret a chi-square test from end to end: In this case, to gauge weather forecast accuracy by comparing predictions to actual results.
Begin your data journey
Want to try this example on your own Matillion ETL instance? Start by downloading Matillion’s example solutions, and then follow the instructions to run the “DevRel Examples Downloader” shared job. Afterwards look for the job named “example contingency table transform” under matillion-examples.

Ian Funnell
Data Alchemist
Ian Funnell, Data Alchemist at Matillion, curates The Data Geek weekly newsletter and manages the Matillion Exchange.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: