- Blog
- 11.21.2017
- Data Fundamentals, Dev Dialogues
Webinar l ETL vs. ELT – What’s the Big Difference?
Matillion hosted a webinar “ETL vs. ELT – What’s the Big Difference?” during which we looked at the traditional ETL approach and associated challenges and investigated ways in which ELT overcomes these. Kalyan, Solution Architect, provided a comprehensive demonstration of 3 common ETL/ELT patterns and how employing an ELT approach can benefit your data warehousing strategy.
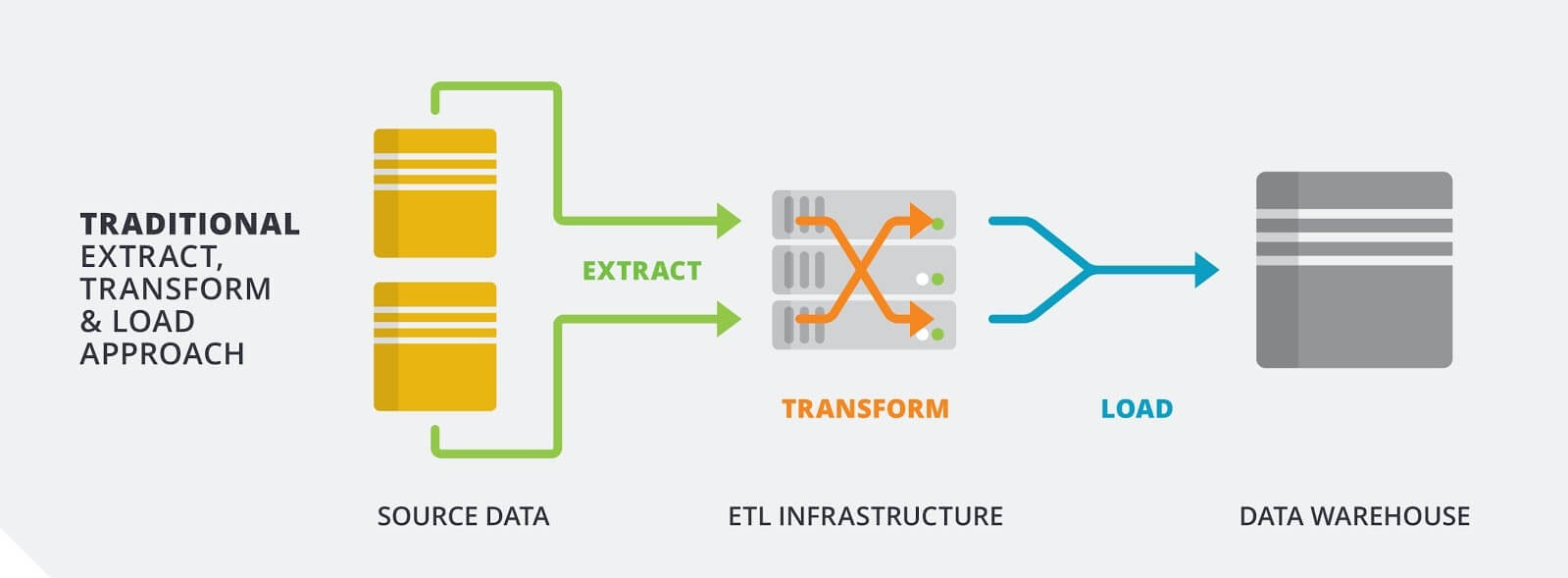
 Instead of transforming your data in your ETL engine/server, you use the power of your data warehouse to process your transformations once loaded. We are confident that you will find great performance with this strategy.
Matillion follows ELT and makes use of the capabilities of modern MPP platforms (like Amazon Redshift, Snowflake, Google BigQuery) to help transform your data. You 'Extract' data from the source system and stream it to intermediate storage, such as Amazon S3 or Google Cloud Storage before i'Loading' it into the target data platform. Extracted data passes through Matillion but is never persisted to disk. You facilitate transformations by generating and executing appropriate SQL on the target MPP database.
When designing a data warehouse, there are two common patterns you could follow.
Instead of transforming your data in your ETL engine/server, you use the power of your data warehouse to process your transformations once loaded. We are confident that you will find great performance with this strategy.
Matillion follows ELT and makes use of the capabilities of modern MPP platforms (like Amazon Redshift, Snowflake, Google BigQuery) to help transform your data. You 'Extract' data from the source system and stream it to intermediate storage, such as Amazon S3 or Google Cloud Storage before i'Loading' it into the target data platform. Extracted data passes through Matillion but is never persisted to disk. You facilitate transformations by generating and executing appropriate SQL on the target MPP database.
When designing a data warehouse, there are two common patterns you could follow.
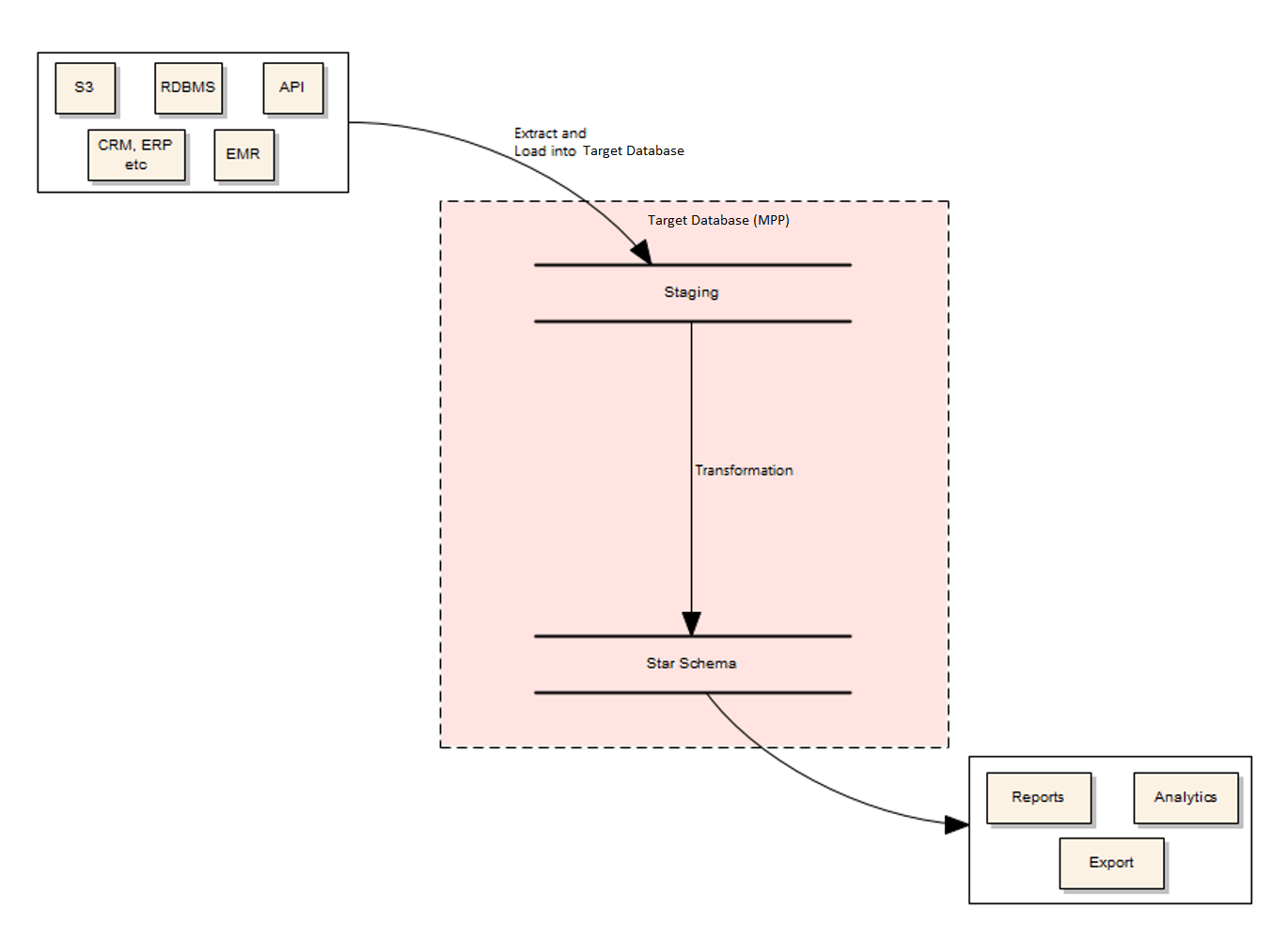 The lines in the diagram represent the data flows. The box in the middle is the database. The idea is that you Extract data from various sources and Load them into target database. There is no data transformation at this stage. Following these two steps, your data then becomes available in the database (staging area) or separate schema for raw data ready to do something with downstream. That leaves the T, for transformation. The final stage sends transformations into the Star Schema. Transformations in Matillion use SQL to do everything within target database. Once you push your data you can share access, for example, with the reporting team to build reports, or denormalize structures for more sophisticated analytics downstream.
The lines in the diagram represent the data flows. The box in the middle is the database. The idea is that you Extract data from various sources and Load them into target database. There is no data transformation at this stage. Following these two steps, your data then becomes available in the database (staging area) or separate schema for raw data ready to do something with downstream. That leaves the T, for transformation. The final stage sends transformations into the Star Schema. Transformations in Matillion use SQL to do everything within target database. Once you push your data you can share access, for example, with the reporting team to build reports, or denormalize structures for more sophisticated analytics downstream.
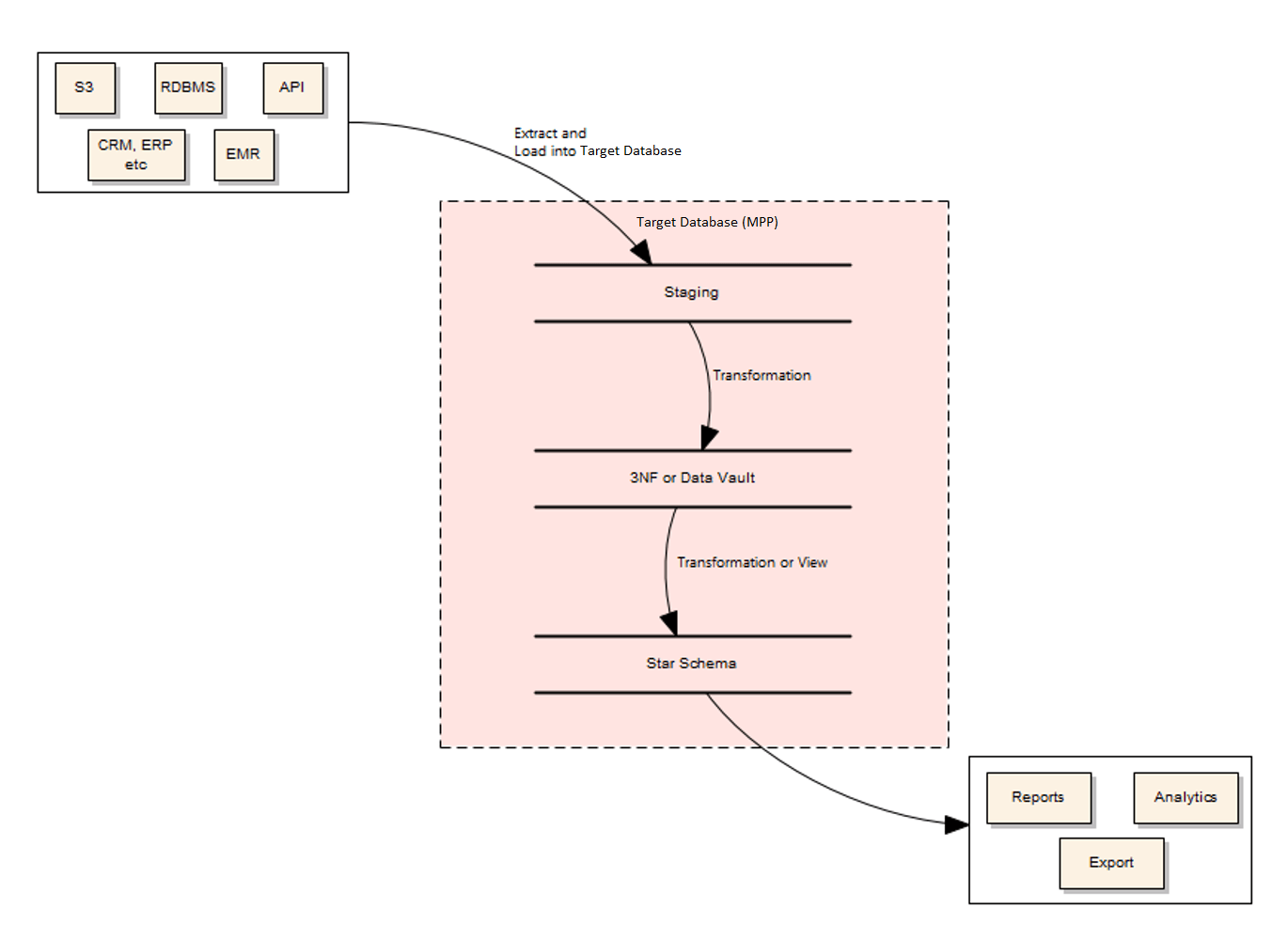 It is almost identical to the Kimball Model, but with the addition of another tier. The benefit of this model becomes evident when you are having to repeatedly perform complicated transformations or applying complex business rules on the same set of data. Once you do your transformation you can use that data over and over again across star schemas. This solves consistency problems you might experience as your data warehouse expands.
It is almost identical to the Kimball Model, but with the addition of another tier. The benefit of this model becomes evident when you are having to repeatedly perform complicated transformations or applying complex business rules on the same set of data. Once you do your transformation you can use that data over and over again across star schemas. This solves consistency problems you might experience as your data warehouse expands.
Extract Transform Load
ETL is the traditional method for Extracting data from numerous source platforms, Transforming the data on your ETL server and then Loading transformed data into a data warehouse ready for analytics and visualization.
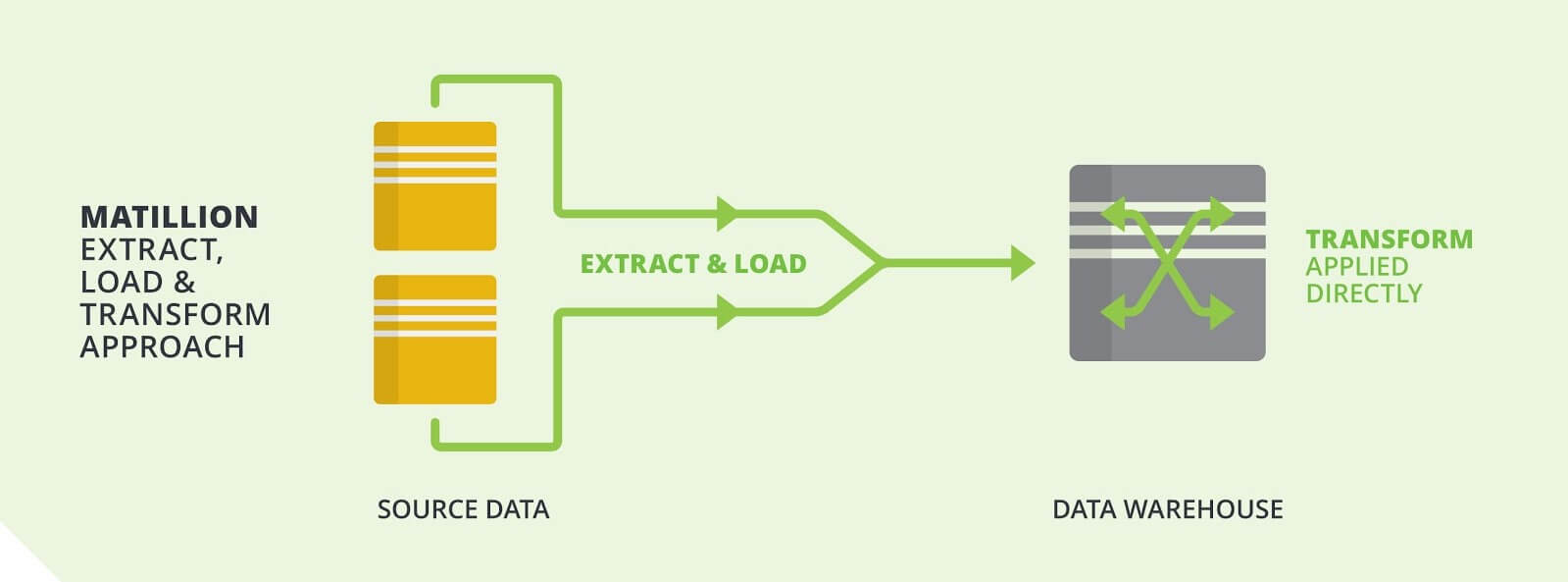
Extract Load Transform
Extract and Load - the ‘E’ and ‘L’ portion of ELT - are done in one move straight to target data platform. Transformations are then applied on your target data platform.
Instead of transforming your data in your ETL engine/server, you use the power of your data warehouse to process your transformations once loaded. We are confident that you will find great performance with this strategy.
Matillion follows ELT and makes use of the capabilities of modern MPP platforms (like Amazon Redshift, Snowflake, Google BigQuery) to help transform your data. You 'Extract' data from the source system and stream it to intermediate storage, such as Amazon S3 or Google Cloud Storage before i'Loading' it into the target data platform. Extracted data passes through Matillion but is never persisted to disk. You facilitate transformations by generating and executing appropriate SQL on the target MPP database.
When designing a data warehouse, there are two common patterns you could follow.
Kimball Model
First is the 2-Tier Data Architecture or Kimball Model.
The lines in the diagram represent the data flows. The box in the middle is the database. The idea is that you Extract data from various sources and Load them into target database. There is no data transformation at this stage. Following these two steps, your data then becomes available in the database (staging area) or separate schema for raw data ready to do something with downstream. That leaves the T, for transformation. The final stage sends transformations into the Star Schema. Transformations in Matillion use SQL to do everything within target database. Once you push your data you can share access, for example, with the reporting team to build reports, or denormalize structures for more sophisticated analytics downstream.
Inmon Model
The second approach is the 3-Tier Data Architecture, or Inmon Model.
It is almost identical to the Kimball Model, but with the addition of another tier. The benefit of this model becomes evident when you are having to repeatedly perform complicated transformations or applying complex business rules on the same set of data. Once you do your transformation you can use that data over and over again across star schemas. This solves consistency problems you might experience as your data warehouse expands.
ETL vs. ELT – What’s the Big Difference?
The big difference is performance. MPP databases such as Amazon Redshift, Google BigQuery and Snowflake have been designed and optimised for ELT. ETL often unearths performance problems when dealing with large data sets. To exemplify the differences between ETL and ELT we looked at 3 common operations - calculations, lookups (joins), aggregations.Calculations
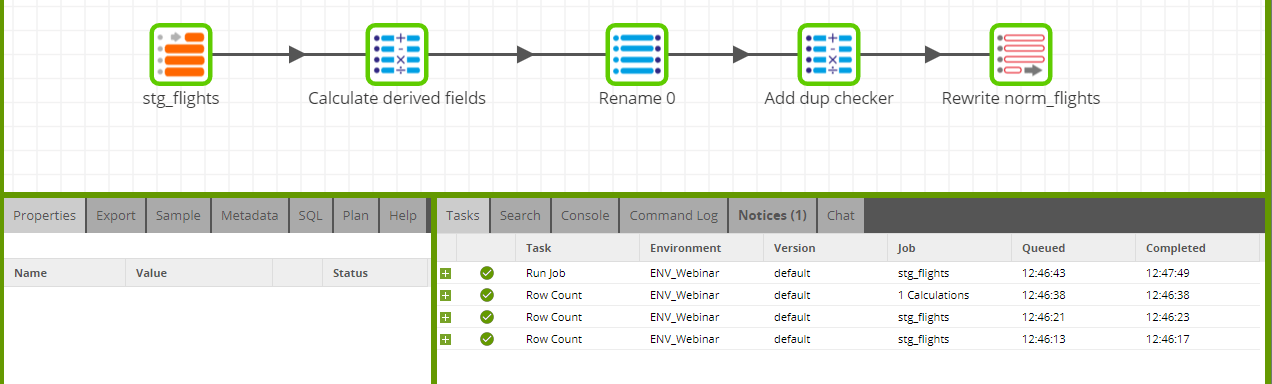
ETL: Calculations can be expressions or applied functions within the ETL server itself. Modern ETL tools are fairly quick with smaller datasets but performance may vary when dealing with large volumes. Calculations may result in overwriting existing columns or a new derived column appended to the data set and pushed to the target platform. ELT: Bring raw data into target database and then easily add a calculated/derived column to existing data. The below example shows how this can be done by using a Matillion ETL Calculator component, and you may specify SQL expressions compatible with your target platform to drive your calculations.
Lookups (Joins)
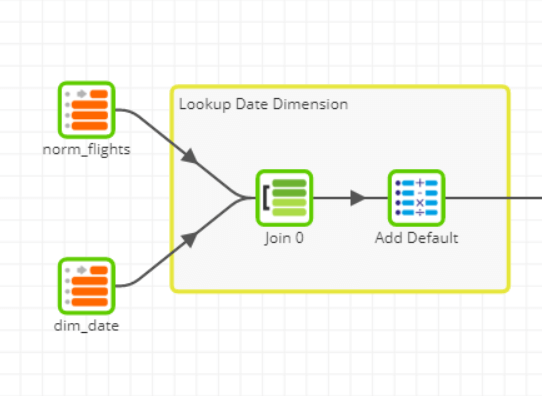
ETL: To perform a lookup, ETL would go row by row to map a fact value to dimension key from another table or source. An API lookup or execute function would bring back a key which is then appended to the data and pushed to target. Usually this works okay, but there is a constraint of needing both facts and dimensions or whatever sources are helping you with this data to be available at that point in time. Another challenge is the amount of data you’re working with when performing lookups. If the dimension table is really big you might have to partially or fully cache the data set. Performance is dependent on the capability of your ETL server and the options provided by your ETL tools. ELT: With ELT you can marry fact table records with appropriate dimension key. Again this is implemented using SQL and typically a Left Join in order to find matches. All the data you need for your join is already present since it was extract and loaded previously. ELT differs from ETL in that MPP platforms are designed and optimised for handling large quantities of data, quickly. This could lead to faster processing times to populate your data warehouse. The below example shows an ELT lookup to a date dimension.
Aggregations
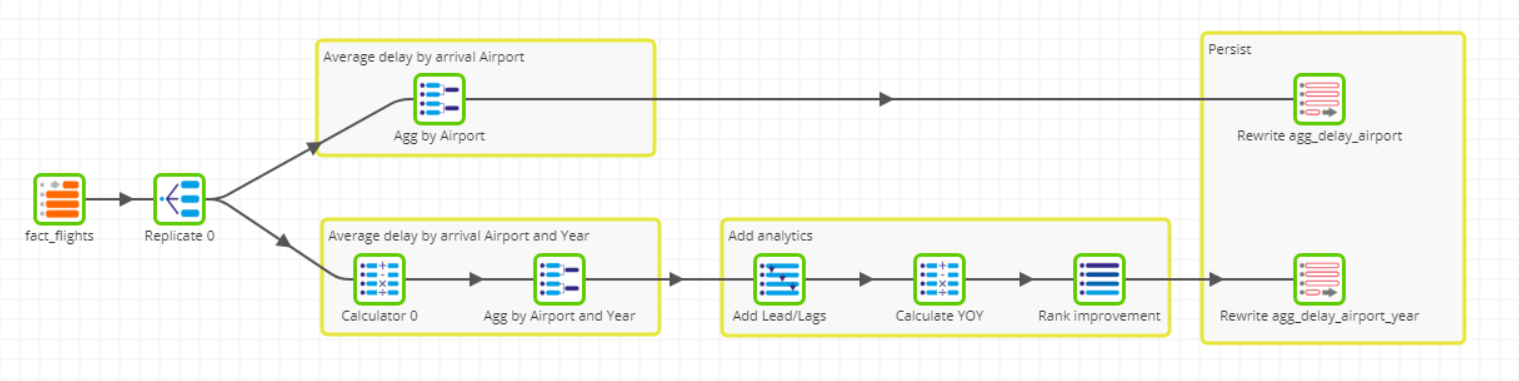
ETL: These are very tricky in the ETL world, especially if you want to keep granular and aggregated data. You will end up with multiple stores of the same dataset with different granularity levels. Aggregations are further complicated by very large datasets. Performing aggregations on the ETL server can be very expensive and you may need sufficiently powerful ETL servers to handle large datasets. Some ETL tools allow you to perform pushdowns where possible, but require a lot of hand holding and manual coding and is a departure from how ETL usually works. ELT: By loading the data first you can then use the capability and power of target platform to transform. You can easily multiplex (below) to use the same input with different transformation-flows or use tables with transformed data from previous jobs to build complex workflows on large datasets. You can write the table(s) that result from the aggregation to storage platforms like S3 or Google Cloud Storage. The table(s) can then be imported into another database/data lake if you so require. The below example shows a source data set that we have multiplexed to create different aggregations, including an inline year-on-year calculation.
3 Common ELT/ELT Jobs
Watch Kalyan walk through calculations, joins and aggregations. https://youtu.be/YTloTRUFkhI?t=19m55sQ&A
When should I choose ELT over ETL?
With ELT you get the advantage of your powerful database twice over: during transformations and processing queries. Furthermore, your choice to use ETL vs. ELT should be based on your target platform. ETL workflows tend to fire DDL (inserts/updates/deletes) for each processed row. This may work fine with traditional databases but not as well with modern MPP platforms which are read optimised but usually a bit slow with writes. ELT is a arguably a better choice when dealing with modern MPP platforms.Does that mean when I have a powerful database I should always choose ELT approach?
It does not mean you MUST do that, but it will probably get better value for money and performance if you do use ELT.Can you trigger a Matillion job using an API?
Yes, you can. Matillion has a REST API that you can use in this instance. If you want to use an external tool to launch jobs in Matillion, ensure your Matillion server is visible to your tool.What is the best practice for creating history? Is this usually done within Matillion?
A historical load is simply an extra-large "delta" load. But you may wish to implement a one-off historical load with a specific technique for that data. In regards to Matillion, it is data agnostic. It doesn't know or understand your data. So when you say history, you're probably interested in how you can hold all of your historical data in the target platform. You can use Matillion to push data into platform with various components that can help with this process. Depending on your use case you can also append and load data and manage partitions, etc.How do you enforce referential integrity in the star schema?
Within the context of Amazon Redshift, enforcing a constraint is not something these platforms are good at. They simply ignore it. In one of our examples we restricted our data to a range from 1990-2023. Whenever you are you are performing a join for lookup use a left join; use the calculator component to identify null values in the reference column, that you can then map to certain values. There are other components with Matillion ETL that can help identify data for example, Except or Intersect. Once you have identified your data you can then take further action, such as assigning a dummy value or even Filtering it out. You can read more about this in our Data Quality Framework.How can I load the data from a Database to Redshift using Matillion?
You would need two things: 1) network connectivity, and 2) use Matillion's Database Query component, which uses JDBC queries. If your database is not listed, as long as you have JDBC driver, you can load to Matillion and connect to your database to pull data in.Does Matillion give the option to create different types of Indexes that Amazon Redshift supports?
Amazon Redshift itself actually doesn't have indexes. However, Matillion can create the database structures that it does support, such as key distribution options and sort keys.Can we do bulk load using Matillion, meaning drop the sortkey, append the data and recreate the sortkey after?
You would have to drop the table really. The sortkey is just the physical ordering. So best to create a second table with the new sortkey, and then drop the originalWhat provisions are there for manual cleaning of data where a general SQL solution is not feasible?
You could use Bash or Python, but that's not really ELT, so I would recommend using SQL if possible.When working in Matillion can you write data out to another target other than Amazon Redshift?
Yes. If you are using Snowflake or Google BigQuery you can follow the process to write to your respective database. If you are pursuing a Data Lake strategy and want to write tables externally to S3 there are two ways you can do this. First, you can use the External Table Output component to append existing external tables. Second, you can use the Rewrite External Table component to output a new external table rather than appending. This is usefulAbout Matillion
Matillion ETL is a data integration tool that we purpose built for Amazon Redshift, Google BigQuery and Snowflake. When we read the product name Matillion ETL. Main reason for ETL is searchability and name recognition. Matillion ETL for Amazon Redshift, Snowflake and BigQuery is actually an ELT product. Following an ELT approach Matillion loads source data directly into your database allowing you to transform and prepare data for analytics using the power of your database.Begin your data journey
Want to find out more about Matillion ETL? Select your data warehouse below to learn more
Ian Funnell
Data Alchemist
Ian Funnell, Data Alchemist at Matillion, curates The Data Geek weekly newsletter and manages the Matillion Exchange.
Featured Resources
Blog
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: