- Blog
- 09.07.2020
Where to store your data: Amazon Redshift vs. S3
If you are employing a data lake using Amazon Simple Storage Solution (S3) and Spectrum alongside your Amazon Redshift data warehouse, you may not know where is best to store your data. This is because you will probably want to store data in both locations! This is because data storage can impact performance and costs when querying that data. Therefore, to make the most of these benefits, some data is best stored on Amazon Redshift, while other data is better on S3 and accessed via Spectrum.
In this blog, we will walk you through an example of using IoT device data. For an extensive list of where to store what data typs, download our eBook Amazon Redshift Spectrum: Expert Tips for Maximizing the Power of Spectrum.

IOT Data Scenario
The diagram below maps out the journey of IoT data generation to visualization and analysis of that data.
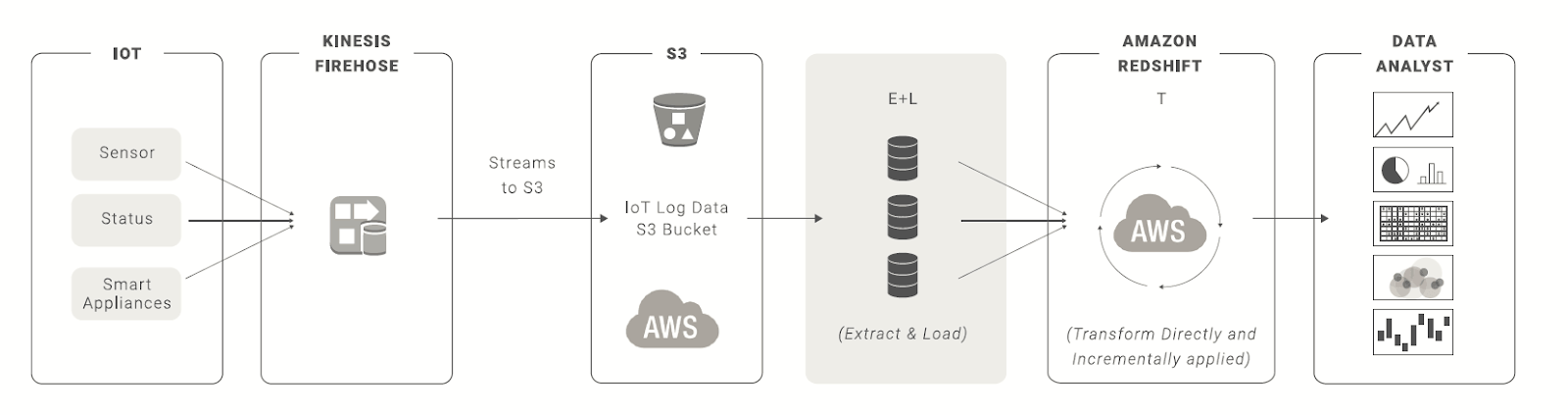
1. Data collection and load to S3
Data is collected by devices, such as Amazon Alexa, Echo or Fire TV Stick, and streamed into S3 via Kinesis Firehose.
- ⇨ Why are we sending data to S3?
By staging the data in S3 and accessing it via Spectrum, there is no data loading time since the data stays on S3.
2. Store data in S3
The data can then be streamed to S3 and a bucket, which can then be read by Spectrum when we execute a job.
- ⇨ Why are we storing log data in S3?
S3 offers cheap and efficient data storage, compared to Amazon Redshift. However, the storage benefits will result in a performance trade-off. This is because the data has to be read into Amazon Redshift in order to transform the data.
3. Combine data sources for analysis
Using Matillion ETL for Amazon Redshift, we can build and trigger a job to read the data and combine it with data stored on Amazon Redshift.
- ⇨ Tip: Aggregate and Filter in Spectrum
Spectrum is fantastic at filtering and aggregating very large datasets. The best performance comes from taking the load off Amazon Redshift. This means you should filter and aggregate in Spectrum before you start joining data, which can be handled in Amazon Redshift.
4. Create a new table
This will create a new table with the aggregated/joined data.
5. (Optional) Load your new table to S3
Finally, we can take our new table and write it back to S3 if required, using the Rewrite Table or Rewrite External Table components.
- ⇨ Tip: Partition your data!
Partitioning your data allows you to place in sensible breakpoints, based on the data, that split up the data into logical chunks. This means a partition, as opposed to the full dataset, can be tackled by multiple nodes improving processing times and reducing cost.
There are a lot of hybrid scenarios. In some instances, you may want to keep some data in Spectrum. In others, you will be better off storing your data in Amazon Redshift dimensional data star schemas. We encourage you to use the considerations in the table within our eBook to see what data you should store where. Ultimately, your best practices will be defined by you, based on your data and use case. Try it out, and see what works for you and let us know what your findings are!

Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: