- Blog
- 09.19.2018
- Data Fundamentals
Using the Zendesk Query component in Matillion ETL for Amazon Redshift
Matillion uses the Extract-Load-Transform (ELT) approach to delivering quick results for a wide range of data processing purposes: everything from customer behavior analytics, financial analysis, and even reducing the cost of synthesizing DNA.
The Zendesk Query component in Matillion ETL for Amazon Redshift presents an easy-to-use graphical interface, enabling you to easily pull data from Zendesk directly into Amazon Redshift. Many of our customers use the Zendesk Query to automate and enhance their customer support with Zendesk Support.
The connector is completely self-contained: no additional software installation is required. It’s within the scope of an ordinary Matillion license, so there is no additional cost for using the features.
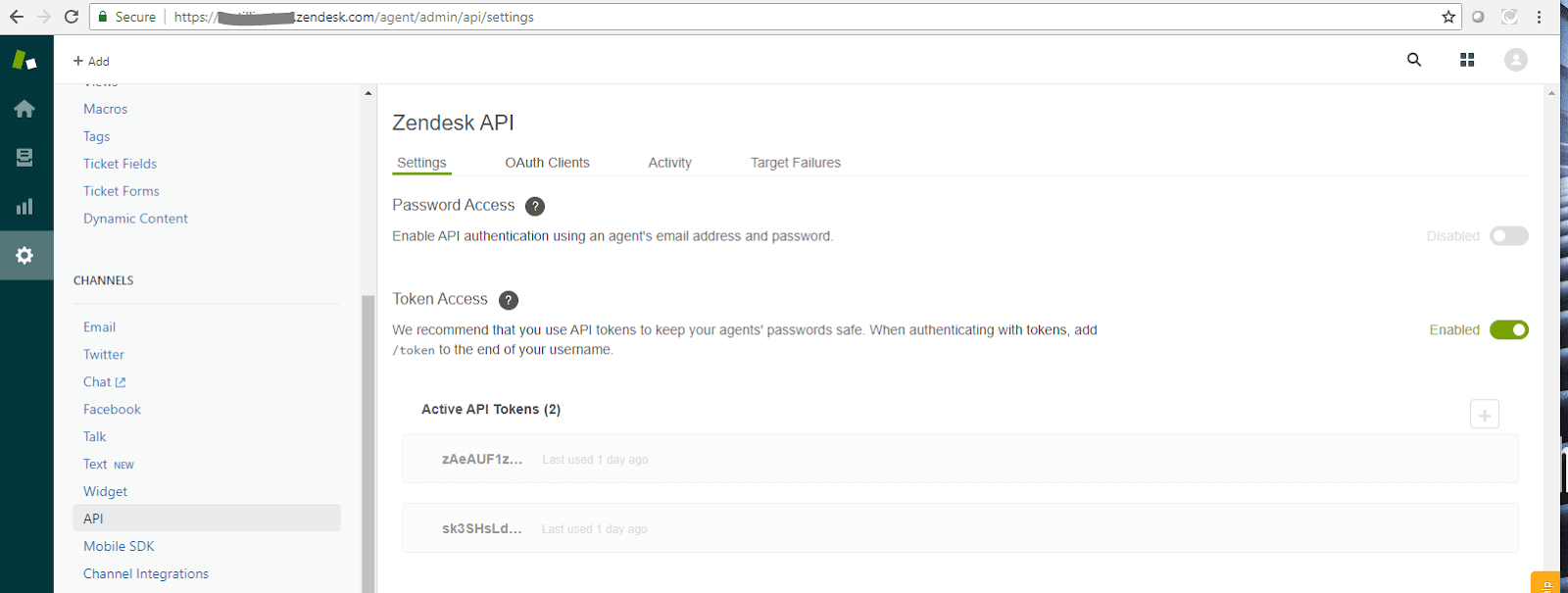
Configure your Zendesk account
- Log into your Zendesk account
- Create a token on your account by using the left-hand menu Admin (gear) → API
- Enable Token Access
- Generate a (new) token if one is created automatically
Data Extraction
Start by creating an Orchestration job to extract the required data from Zendesk. In the ‘Components’ search bar type Zendesk. Drag and drop the Zendesk Query component onto the job canvas.
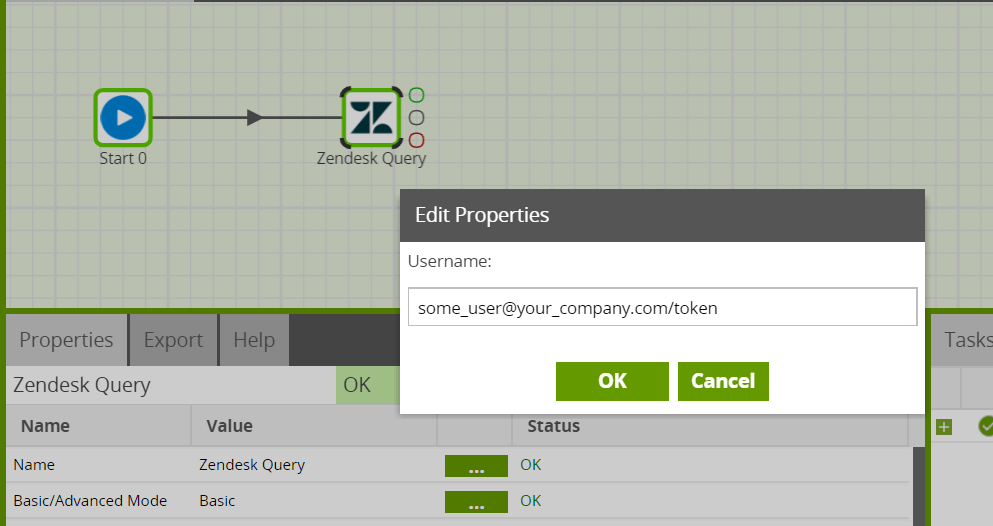
Authentication
The Zendesk Query supports Username and Password authentication. The first step in configuring the Amazon Redshift component is to provide the Authentication to Zendesk. Clicking on the ellipsis next to the Username property will bring a pop up the box to populate the Username. Add “/token” after the email address. Then populate the password attribute.
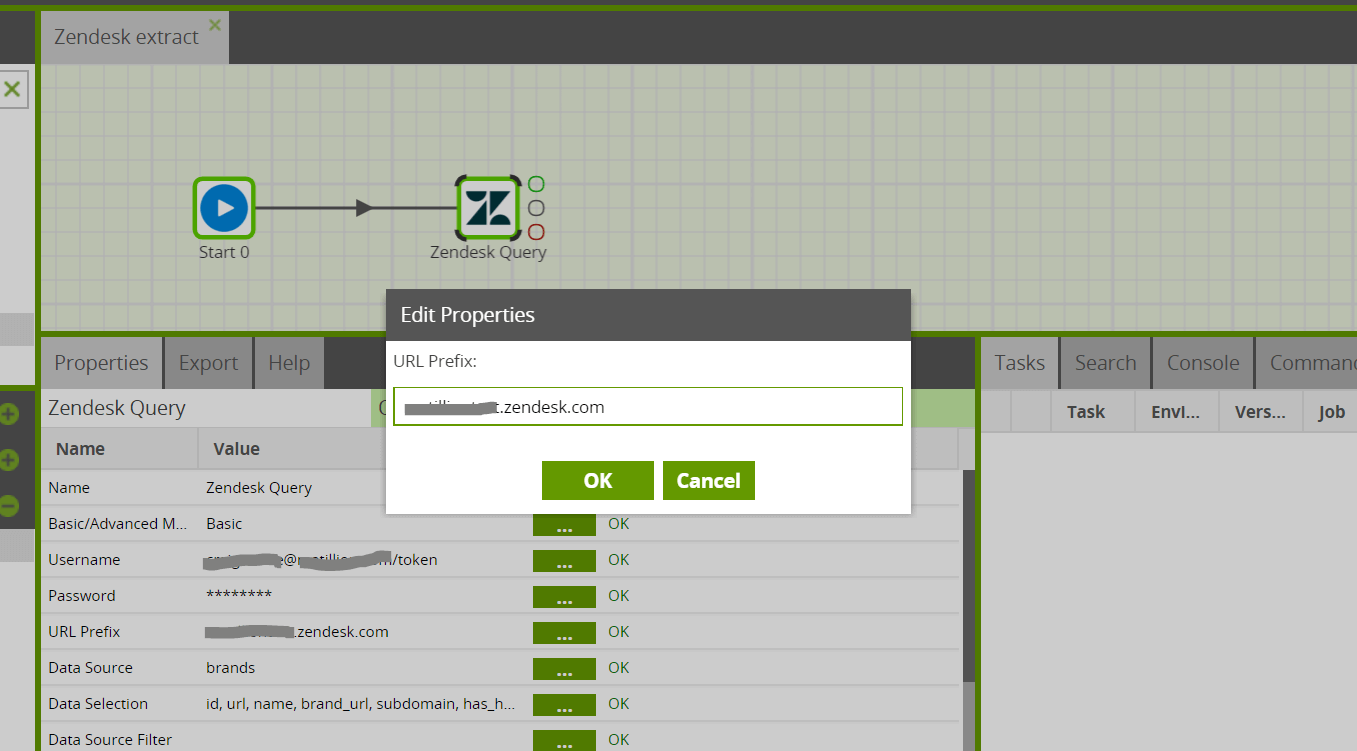
URL Prefix
Next, specify the URL Prefix to get to your Zendesk account.
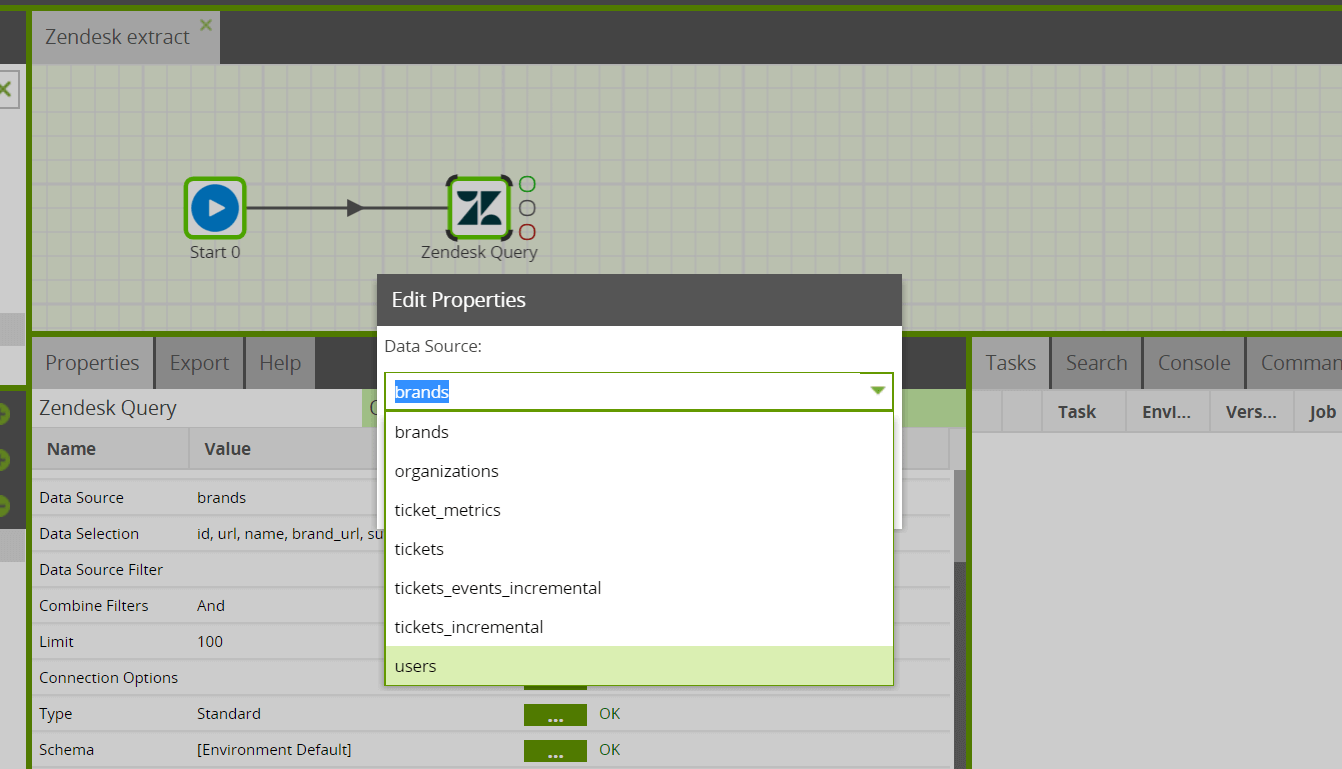
Data Source
Next, select the Data Source (table) you want to pull data from displayed in the Data Source drop down.
Data Selection
Select the columns from the data source that you are interested in. Matillion will supply a list of the columns available to you in the Data Source previously selected. This will form the new table which you will create in Amazon Redshift with the help of Matillion.
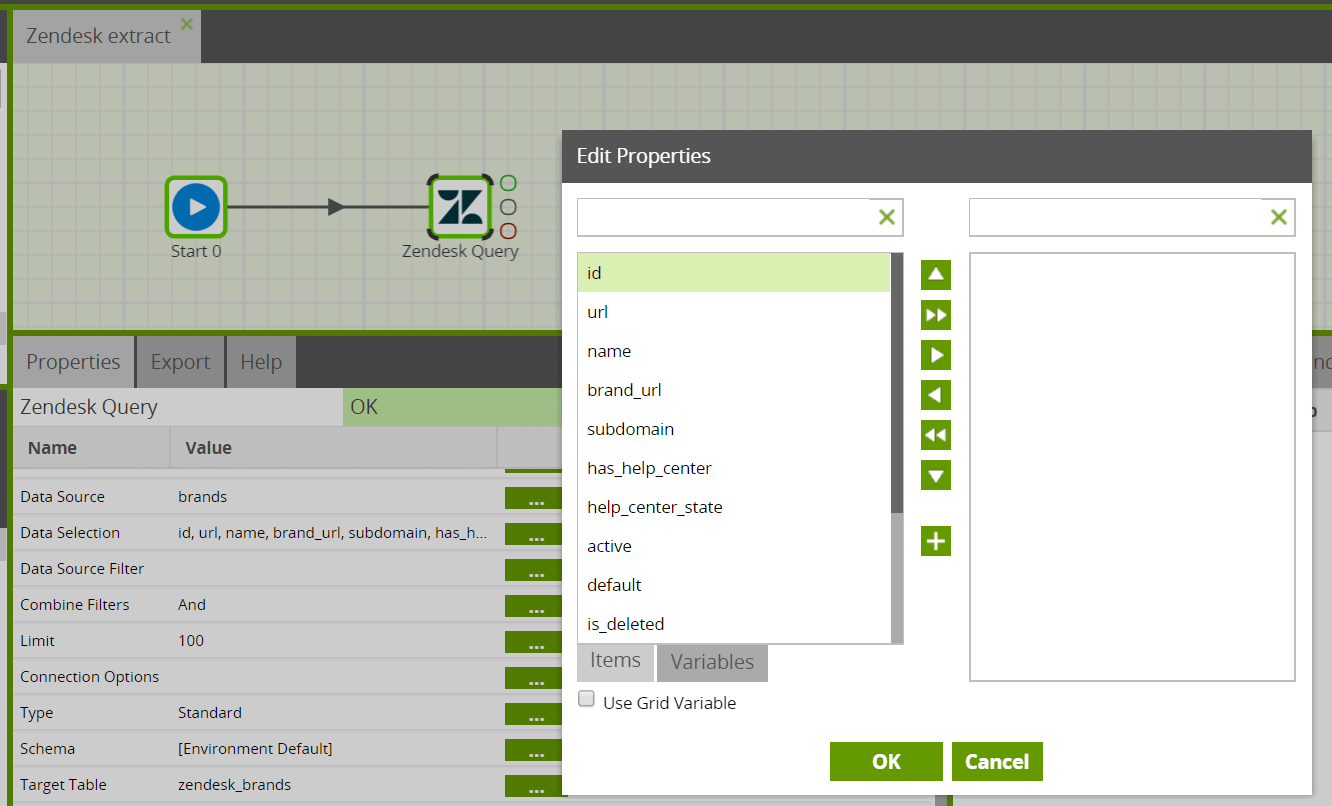
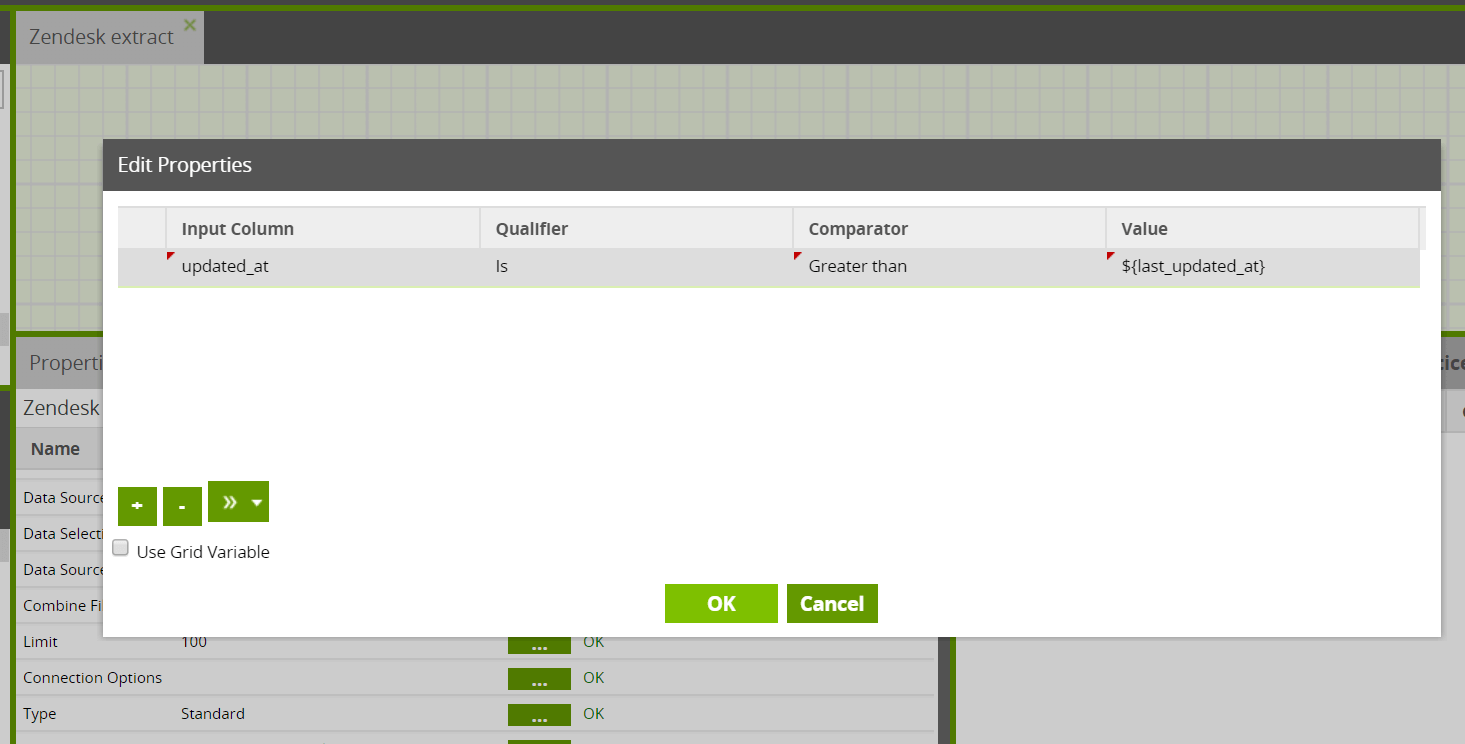
Data Source Filter
Leaving the data source filter empty will allow the query to return all rows (based on the setting in LIMIT). You may want to pull just the new records, for example, since the last time data was pulled from this data source. If so, populate the data source filter accordingly. Here is an example of pulling just new rows based on a variable “last_update_at”:
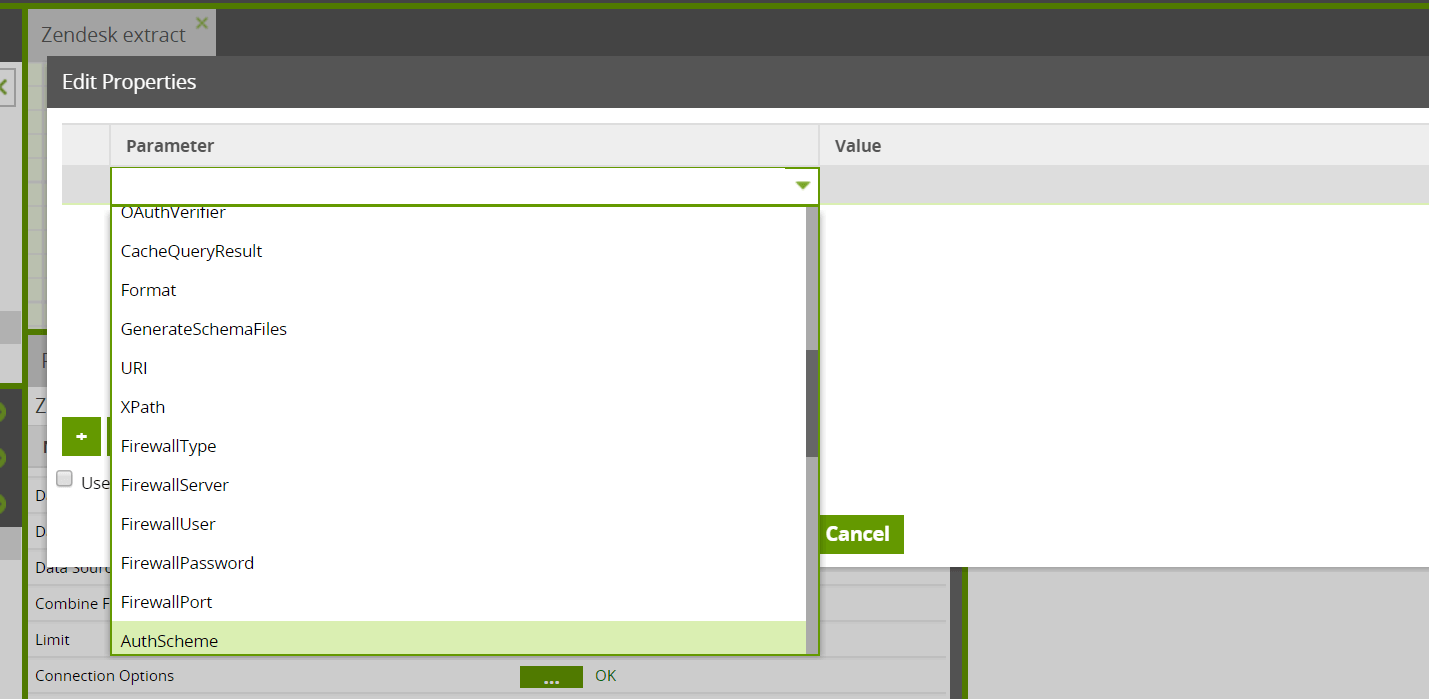
Connection Options
Several connection options are available for the Zendesk Query if needed. Normally, the connection option attribute can be left blank.
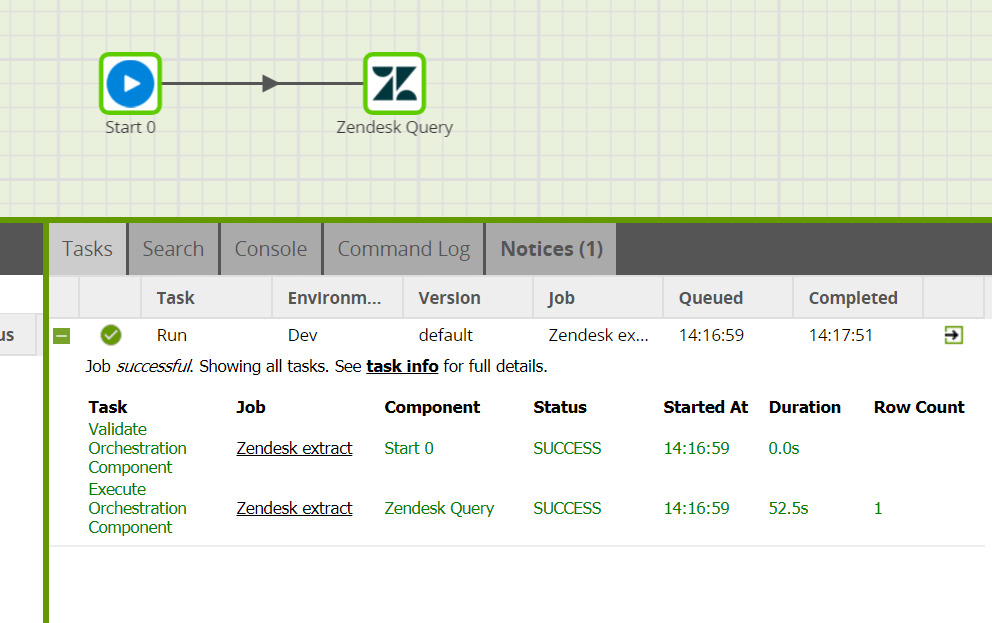
Running the Zendesk Query component in Matillion ETL for Amazon Redshift
Before you can run the component, you need to specify a Target Table name. This is the name of a new table that Matillion will create (or overwrite) to write the data into Amazon Redshift. Also, an S3 Staging Area must be specified. This is as S3 bucket which is used to temporarily store the results of the query before it is loaded into Amazon Redshift.
This component also has a Limit property which forces an upper limit on the number of records returned.
You can run the Orchestration job, either manually or using the Scheduler, to query your data and bring it into Amazon Redshift.
Transforming the Data
Once you have extracted your data from Zendesk and loaded into an Amazon Redshift table, you can start to transform the data.
In this way, you can build out the rest of your downstream transformations and analysis, taking advantage of Amazon Redshift’s power and scalability.
Useful Links
- High Performance Integration of Zendesk into Amazon Redshift
- Zendesk Query Data Model
- Zendesk Query component
Begin your data journey
Try the Zendesk Query component in Matillion ETL for Amazon Redshift. Arrange a free demo, or start a free 14-day trial.
Featured Resources
Enabling DataOps With Data Productivity Language
Discover how Matillion leverages Git and the Data Productivity Language (DPL) to enable seamless implementation of DataOps ...
BlogCustom Connector for Public Statistics (Police API)
A demonstration of the practical steps for setting up components, manipulating and validating data, creating and scheduling ...
BlogMastering Git At Matillion. An In-Depth Guide To Merging
Merging in Git is the process of integrating changes from one branch into another. Merging is the backbone of collaboration in ...
Share: