- Blog
- 11.22.2021
- Dev Dialogues, Data Fundamentals
Declarative Data Vault 2.0 in Snowflake with Matillion ETL
In this article I’ll talk about the part Data Vault has to play, underpinned by the Snowflake Data Cloud’s storage and compute capabilities.

After replicating your data into your cloud data platform, a key part of unlocking its value is storing it in a flexible and scalable way. The Data Vault modeling technique is a great approach to use for this transformation. Integrating previously siloed data in a consistent, unified way enables you to present and use it reliably.
Matillion ETL for Snowflake, which is built to take advantage of the Snowflake features and architecture, is the enabler that helps you design and orchestrate Data Vault transformations inside Snowflake on an enterprise scale.
Let’s bring some of this theory to life!
Inside the Data Architecture
A typical enterprise data architecture is made up of many layers. For our purposes, I’m going to focus on the Data Vault part, but of course it exists within a broader context.
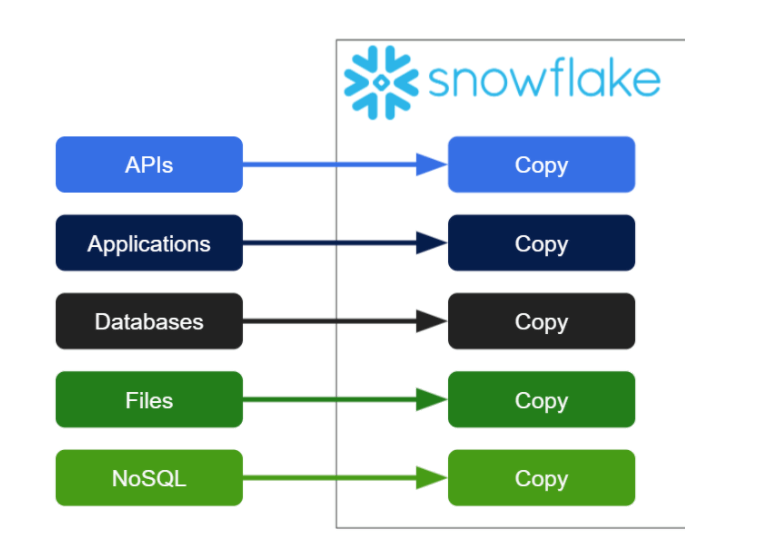
For operational and performance reasons, it makes sense to start by just copying all of your data into the same place. You could use a bulk load command, a Data Share, a Stream, or a dedicated data pipeline tool such as Matillion Data Loader or one of Matillion’s data connectors.
Ingesting your data into a central location is the important first step. But it’s important to note that, after colocation, data from different sources is not yet integrated; it’s still logically siloed.
One of Data Vault’s central concepts is that it stores all information about business entities in the same place. These entities are called Hubs. Anyone in the business should be able to identify Hub entities, using a well understood and unique business key identifier. For example, in a civil aviation model, Airports would be a good choice for a Hub, and the business key could be the IATA code. Similarly another Hub to choose might be Aircraft, with Tail Number as its business key.
So when you’re providing the input data to a Data Vault model, you need to be sure about the granularity of the data, and about how to find the business key. In this case, I’ve chosen to use database views to impose a defined taxonomy onto the raw input data.
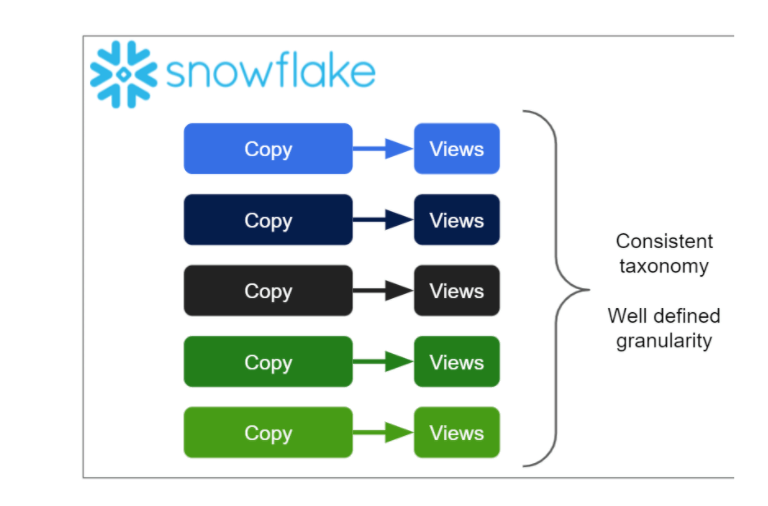
With Matillion ETL, you can create the necessary Snowflake views in the graphical user interface.
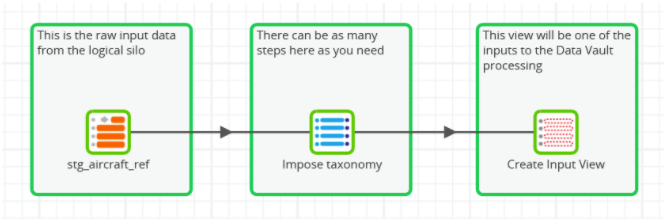
This layer of views provides the first opportunity to handle schema drift at source.
Most business users (and most BI platforms, and AI/ML implementations) prefer to consume simple data structures. A star schema is the natural design choice.
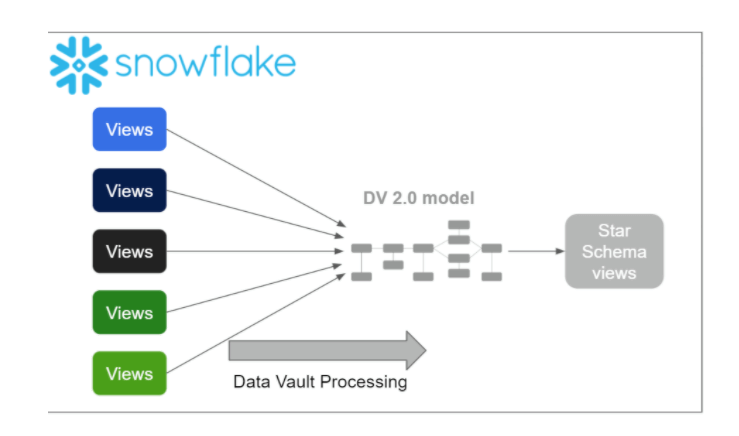
For the presentation layer, once again I have chosen to use database views on top of the Data Vault structures. More on this subject later. First, let’s have a detailed look at the implementation of the Data Vault Processing.
Declarative Data Vault implementation
Here’s the full DV 2.0 data model that I started to describe in the previous section.
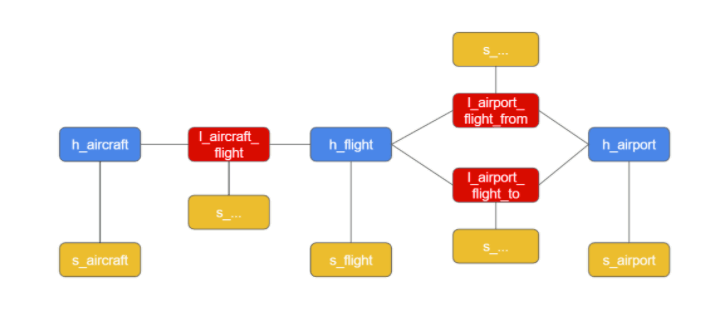
There are Hubs for Aircraft and Airports, which are straightforward, as you would expect. There’s also a Hub for Flights, which has a more sophisticated key since it must cater for cancellations, rerouting etc.
Hubs can be related to each other. Every Flight is made by an Aircraft, and goes from and to an Airport. Unsurprisingly, in Data Vault these tables are the Link entities. Both Hubs and Links have associated Satellite entities to hold all information beyond the business key.
Even for this small scenario there are 12 tables. So it’s clear that pushing data into a Data Vault model requires a reasonably sophisticated piece of data transformation. You have to hash the right values, check the conditions accurately, and put the data into the correct places. Furthermore, what’s really most important about this is the data in the model, not how it got there. If the reports don’t add up, or the machine learning insights are contradictory, business users will be unimpressed to hear a boast about the ETL technology!
It would be great if the ETL setup and processes mirrored that priority. I don’t want to have to remind it to hash the correct key columns, or exhaustively explain how to link this table to that one. I’d prefer to be able to just tell it: here’s the data, these are the keys… you do the plumbing.
Matillion ETL’s Shared Job feature enables you to use that declarative style for Data Vault. Here’s what the processing looks like.
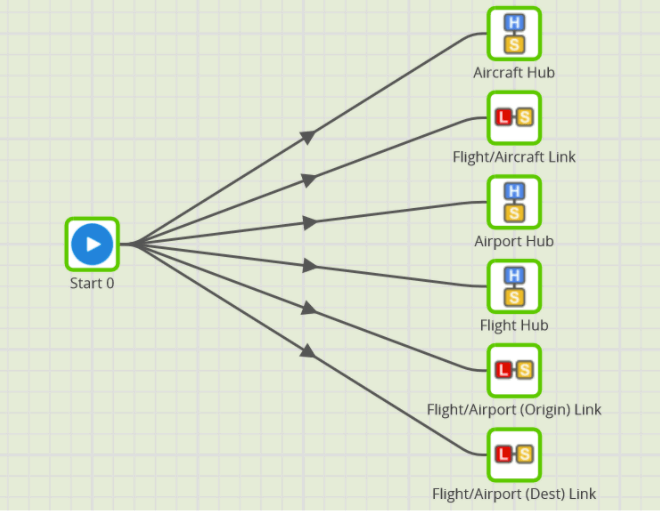
That’s all there is to it! All the tasks can run in parallel thanks to the hash keys. All the information that the jobs require is passed in as parameters to the Matillion tasks. You have the choice of hardcoding them (good for a quick prototype) or making it metadata driven, as you’d probably choose for production.
Hub and Link implementation details
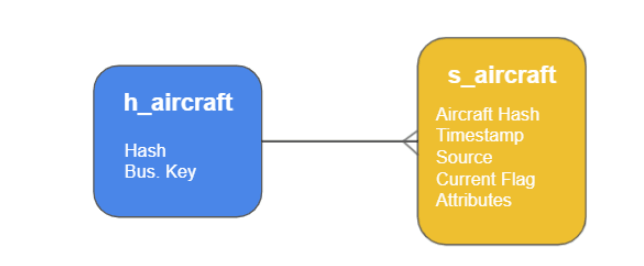
Every Data Vault Hub has three closely related Snowflake database tables. The Hub itself is named h_<entity>, and it has a small set of standardized columns. There’s always an associated Satellite table named s_<entity>. This holds all the additional information about every Hub.
For example an Aircraft Hub table would contain pretty much just the Tail Number. Whereas the Satellite table would contain potentially many attributes such as the make, model, year of manufacture, number of seats, etc.
I’ve also added an error handling table named e_<entity>. This is not part of the Data Vault 2.0 specification, but is useful for audit and traceability. Its job is to hold all the information that did not make it into the Hub and Satellite tables for any reason. Common examples are missing or duplicate business keys.
The tables are linked by MD5 hashing the business key column(s). If it’s a multi-part key, then the columns are taken in alphabetical order when generating the hash. Small items of consistency such as this are a vital part of guaranteeing data integrity, but they are easy to overlook or get wrong if you are hand-coding. It’s a major benefit of this kind of automation.
There’s a similar story for Data Vault Links. In addition to the l_<entity1>_<entity2> table, a Satellite table exists to provide any extra context that the link needs. An example of “link context” might be the information that the Aircraft that took this particular flight was a substitute and not the originally planned one.
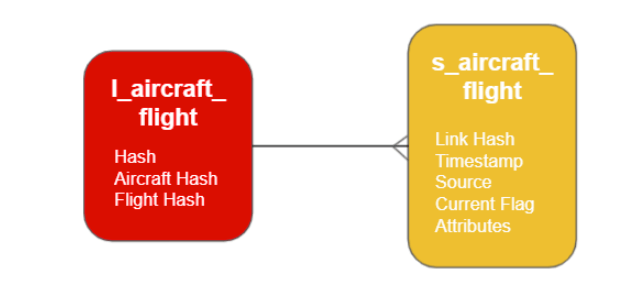
An important thing to notice is that there can be more than one Satellite record per Hub or Link. This is fundamentally how changes are tracked over time. It also helps integrate siloed data by allowing the context data to come from more than one source. For example, an Aircraft may be refitted over its lifetime to have a different number of seats, but (provided the Tail Number does not change) it’s still the same Aircraft.
In the next section I’ll talk about some of Snowflake’s unique technical features that Matillion uses to make all of this happen.
Technical highlights of Snowflake when using Data Vault and Matillion
Kent Graziano’s series of tips describes various ways to optimize a Data Vault architecture on Snowflake. I’ve added some general application design principles, and grouped them into five main areas below.
Hash keys
Every Data Vault model contains many foreign key relationships. Using surrogate keys and lookups would require at least two steps to transform the data correctly. First, you would create a new Hub record with a new surrogate key. Then afterwards, you would join on the business key to find the foreign key value for the related Satellite record. It’s technically fine, but there is an easier way.
Instead of that approach, Snowflake’s UDF feature and semistructured data handling capabilities make it easy to use hash keys instead. Here’s how it looks in Matillion ETL.

Snowflake’s ARRAY type makes it simple to deal with multipart keys. When calling the UDF, Matillion uses the ARRAY_CONSTRUCT function.
Parallelism
Two main design features give the most opportunities to take advantage of Snowflake’s parallelism and scalability.
First, the use of Hash Keys means you can run all the Hub, Link and Satellite loads in parallel, as you saw in the Matillion job earlier.
Second, Matillion ETL makes use of Multi-Table Inserts to perform its DML operations. It’s all encapsulated into the Shared Job so you don’t need to code anything, or even be aware of how it works. If you’re interested to see how it transparently increases the load performance you can view the generated SQL using the Metadata API.
Interface Minimization or Loose Coupling
Some parameters are required, such as database names and schema names. But as a guideline, you should not have to pass in any information that the application can look up for itself.
A good example of this is when you are linking Hub tables. The hash codes are generated by taking the MD5 hash value of the business keys (in alphabetic order, remember!). The business keys are known to Snowflake because they were defined as metadata when the table was created. So at runtime, the job looks up the keys for itself using the GET_DDL function. You don’t have to provide that information yourself: less can go wrong.
Object/Relational techniques
Satellite tables hold all of the additional columns, which give the contextual information about a Hub or Link. This means they have to deal with a diversity of input data, both from schema drift and from cases where multiple source systems contain information about the same thing.
Snowflake provides a simple schema on read solution using OBJECT_CONSTRUCT(*). Of course that pushes the schema drift problem downstream, so it’s helpful to virtualize the data presentation layer. This saves having to physically reload everything every time the semantics change.
Presentation layer views
Your Data Vault model does not dictate your presentation layer. You are free to create any downstream structures that are needed by the business.
Using views to virtualize the data presentation layer has several advantages. First of all, no data is materialized so there’s no actual process to run.
It also gives the flexibility to create different views against the same source. For example, you can create at least three different kinds of star schema objects from a single Data Vault entity.
- A “latest status” dimension (known as a Type 1), useful when the business just wants to analyze by the current value. Snowflake’s windowing functions are very helpful for this purpose.
- A time variant dimension (known as a Type 2), which provides the ability to look back in time and analyze by the value as it was in the past. All Data Vault 2.0 Satellite data is already time variant so these are often easier to create than the Type 1 views.
- A fact table based on the same data. This provides the option to report at the natural granularity of that data, optionally linked to other dimensions.
And all of this happens with no risk of the views ever becoming desynchronized.
Try it for yourself
Matillion is Snowflake’s Technology Partner of the Year for Data Integration. Since 2017, Matillion and Snowflake have helped customers like Slack, Peet’s Coffee, Cisco, and Western Union make data useful.
You will find the two Shared Jobs used in this article pre-installed if you tick Include Samples during the Create Project process. You can also download them from the Matillion Exchange.
Or get a demo of Matillion ETL to see how else cloud-native data integration and transformation can help your business do more with data.

Ian Funnell
Data Alchemist
Ian Funnell, Data Alchemist at Matillion, curates The Data Geek weekly newsletter and manages the Matillion Exchange.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: