- Blog
- 11.04.2021
Data Vault vs Star Schema vs Third Normal Form: Which Data Model to Use?

In the journey towards gaining value from data, it’s common to convert between formats. As discussed in this article, often it involves using Matillion to move data along the path from Unstructured to Semi-Structured and then to Structured formats. In its final, most compact, and most easily usable form, structured data is a dependable platform upon which to build reliable insights.
Data is classified as structured when it has a defined data model. Data Vault, Star Schema, and Third Normal Form (3NF) are all examples of types of data models. Each has its own unique place in data warehousing, and this article will describe how and why you might use each one.
I will include examples of all the different types of data models and how to build them. But first, let’s look at how the different models fit within a bronze/silver/gold framework.
Consumability: Bronze, Silver, Gold
One main goal underpins most data transformation and integration activity: to make data more easily and reliably consumable by end users. Consumability is a primary axis of variation between types of data models, and it’s a helpful way to differentiate them. We often use a bronze/silver/gold framework to characterize levels of consumability.
Raw format
The starting point, or “bronze” consumability phase is data in its “raw“ format. For all data engineering or data science activities, it just means whatever data you have been given!
Typical examples are:
- Data in long-term storage formats such as a data lake (which can become a data swamp when there is no documented data model)
- External or virtualized tables
- Transport formats – whether Unstructured, Semi-Structured or Structured
Bronze consumability does not imply poor data quality. The producers of this data are busy successfully running their parts of the business using exactly that data, and would be indignant to hear it described as such. As far as they are concerned, the data is perfect.
Raw data is probably not well integrated with any other data, and it may be rather inconvenient to read. But the producers would argue that their data quality is excellent. Data transformation activities within a data warehouse need to focus on not making the data quality worse.
Staging and operational data stores (ODS)
An alternative starting point might be a change data capture process such as Matillion Data Loader, any kind of incremental load, a virtualized or federated table, or a source-specific connector. Those activities just copy data from place to place, and the resulting data model is often described as “staging” or an “operational data store” (ODS). The emphasis is on colocation rather than integration, and data models in this phase simply copy those in the source systems.
There is an argument that data copied from a live, operational source system has already been treated, filtered, and approved by that system. You can successfully run system-specific operational reporting from an ODS. For that reason, it is already on its way to becoming “silver” in terms of consumability, despite lacking any kind of integration.
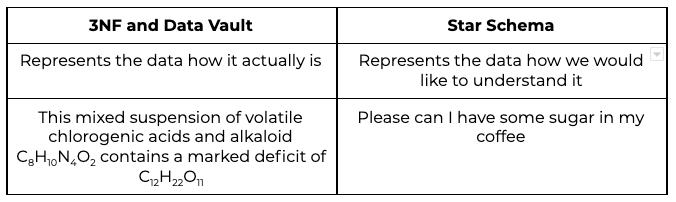
Third Normal Form (3NF) and Data Vault
Adding features sourced from multiple places, needed, for example, to obtain a customer 360 view, requires true data integration. In practice this requires transformation to adapt the data from those diverse sources to fit a unified data model. This is the role of Third Normal Form (3NF) and Data Vault (DV) models.
Sometimes getting data into the necessary shape requires a lot of transformation, and the application of many business rules. But when that is done centrally, consistently, and reliably, end users don’t have to do the work themselves. For that reason, 3NF and Data Vault represent the beginning of “gold” standard consumability.
The sophistication and flexibility of 3NF and Data Vault models means they can still be technically difficult to consume. Often there are esoteric structures, with many relationships that are complex to navigate. Sometimes there are aspects that still remain open to interpretation, for example when different source systems disagree with each other.
Dimensional models, star schemas and aggregates
Dimensional (also known as star schema) models offer a simplified way to structure data that is the most consumable. They are targeted towards specific reporting needs, and are consequently less flexible than 3NF and DV models. Tight targeting to requirements means that dimensional models represent the ultimate “gold” phase.
Star schemas may contain large volumes of data, so it can be useful to create data aggregations or denormalizations for performance reasons.
If you find that you are creating a lot of sophisticated logic inside a visualization tool, adding an aggregated data model can be beneficial. An aggregated data model can reduce tight coupling between systems, which gives you better long-term flexibility.
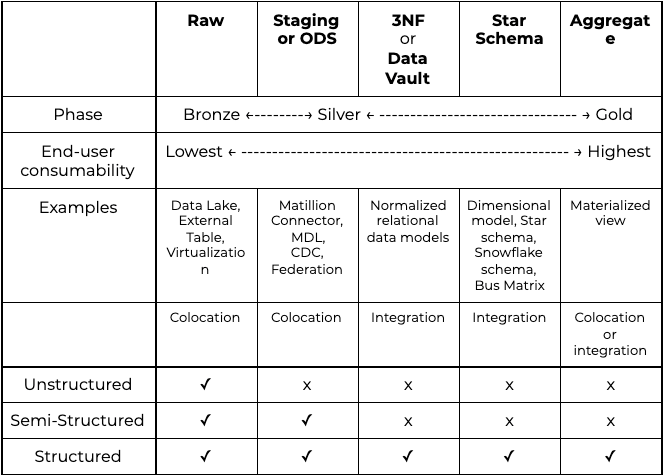
Data model types at-a-glance
The chart below shows a summary of the main data model types, in their different phases.
Data models: Nouns and Verbs
The key aspect of gold standard consumability is that everyone is clear what the data is. How it got there is of no concern to the consumer. If reports are wrong, or insights are misleading, business users will not be conciliated to hear that you used the latest and greatest technology, or that the runtimes were exceptionally fast and well tuned.
Good data models are therefore declarative (focusing on the nouns) rather than imperative (focusing on the verbs).
For example, this is a data model. It focuses on what the data looks like:
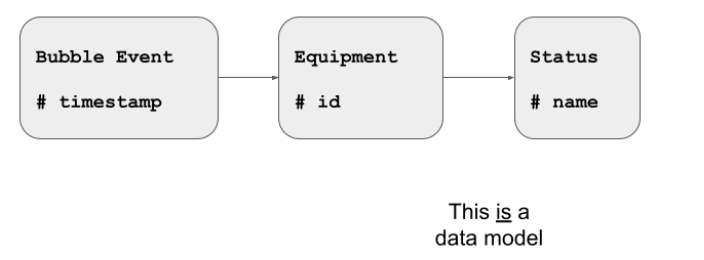
For example, this is a data model. It focuses on what the data looks like:
There are many nouns in the diagram, explaining what can be found in the data, how the various objects can be uniquely identified, and how they are interrelated.
At the other end of the spectrum, this kind of thing is not a data model:
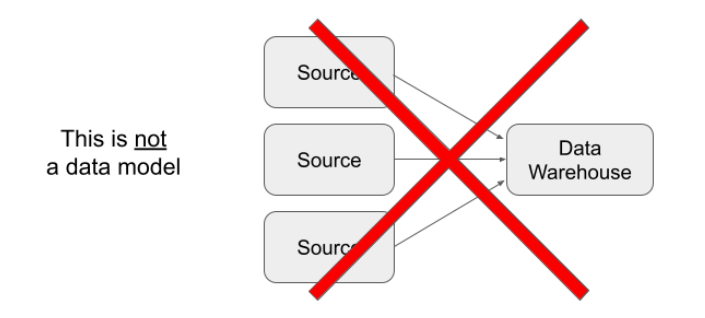
The few nouns in the above diagram are deceptive. They don’t give any clues as to what you might expect the data to look like. Instead there is a small amount of irrelevant information about how data is copied from place to place.
Similar can happen in the discovery stages of a project. Here are two statements that you might find in an analysis:
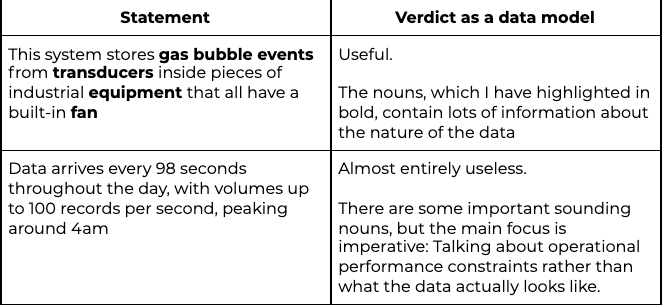
Let’s look at examples taken from the framework described above, starting with raw data models.
Raw data models
The raw phase is all about capturing whatever data has been supplied. It might have a well defined data model, whether documented or not. Or it might be semi-structured or even unstructured, in which case you will need to work out how to make the format more accessible.
Data modeling in the raw area is a reactive affair. You can choose to use a predefined model, hoping that incoming data adheres to that model. Or you can choose to use a data model defined at runtime, perhaps by an inferred schema in an external table.
The screenshot below shows what those two choices look like in Matillion ETL.
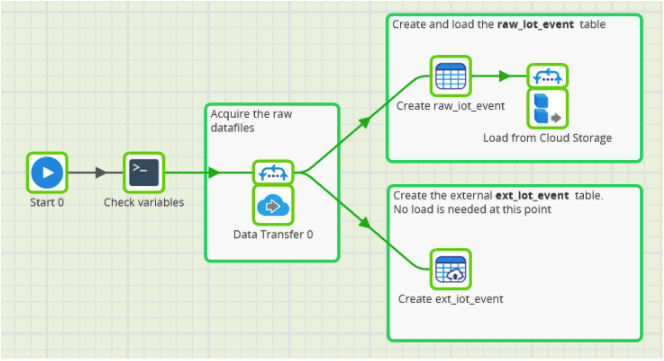
The initial components on the left copy the source files into cloud storage for ease of use, and for archiving.
In the two subsequent branches on the right:
- The raw_iot_event is a real database table. Data has to be physically loaded. It is therefore followed by a cloud storage load component inside a loop
- The ext_iot_event is an external table, just containing instructions about the location and names of the source files. This is a virtualized, or federated, data source which never needs to be actually loaded
Key characteristics of raw data models are:
- The actual data model is determined by the received data: there is no choice to be made
- This is the first step of data colocation
- There tend to be many single, standalone tables
- Incoming raw data is the ultimate audit trail
There are no typical data transformations at this stage. Nothing is rejected unless it really is physically unreadable
The raw area is all about the mechanics of acquiring the data. Following that, staging starts to be concerned with the question of how the data is supposed to look.
Unstructured data must be interpreted at this point. Semi-structured data is often relationalized at this point. In both cases, the goal is to make it more reliably consumable.
Here is an example of a relationalization process in Matillion ETL:
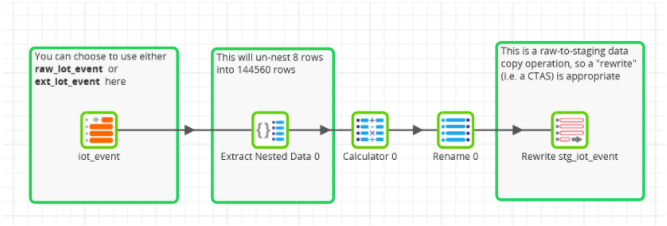
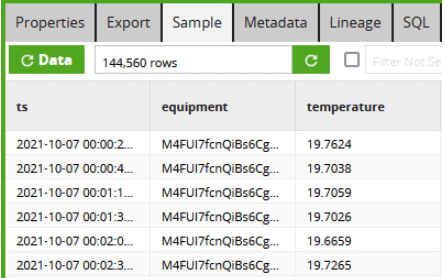
On the far left is the raw input. If you download the example jobs and try for yourself, you’ll find there are only eight rows. They correspond to eight input files, each one containing a large chunk of JSON data. Matillion data transformation components flatten it into 144,560 relational rows, which are much easier to read.
Staging data models
Key characteristics of staging data models are:
- The model is determined by the source system
- If it’s a structured, relational source: the staging data model is a direct copy of the source system’s physical data model
- If it’s an unstructured or semi-structured source, the staging data model is an attempt to match the logical structure of the source
Some characteristic data transformations that are often used while loading data into staging models are:
- You may add extra information, such as timestamps and source system names, for audit purposes or to help later with integration
- CDC sources might add technical fields, such as whether this change is an Insert, an Update, or a Delete
- For analog unstructured sources you may need AI/ML feature detection
- For digital unstructured sources, this is the time to separate presentation from content
- Avoid semantic transformations, as they reduce the data’s usefulness for audit purposes
- Similarly to the raw area, reject nothing unless it is physically unreadable
- Character set or other localization transformations may be required
Data received into staging is often incremental in nature. There’s no harm in expecting a full set of data if it is small, but it’s unrealistic and wasteful to expect a full, large data set every time. For that reason, staging objects are usually relatively short lived and transient.
In Matillion ETL the Rewrite Table component is widely used to perform drop-and-CTAS (create table as select) operations. You can see an example in the transformation job screen shot above.
It’s fine to use staging data as a feed into a 3NF or Data Vault model. But in cases where a full copy of the source system’s data is useful, an ODS model is the next step.
ODS data models
An Operational Data Store (ODS) is modeled in a very similar way to a staging area. In an ODS, the data model is also a copy of the source system.
The two main differences between staging and ODS are
- An ODS contains a full copy of the data from one source system. Whereas staging usually only contains a small set of recent changes
- An ODS is usually treated as a permanent data store, and may be useful for operational reporting from a single system. Whereas staging objects are usually temporary, and are often dropped and recreated
Having multiple ODS data models accessible inside one cloud data warehouse is a useful way to colocate data before integration.
To create an ODS in Matillion ETL, you would first create the target table(s) if they don’t exist yet, for example like this:
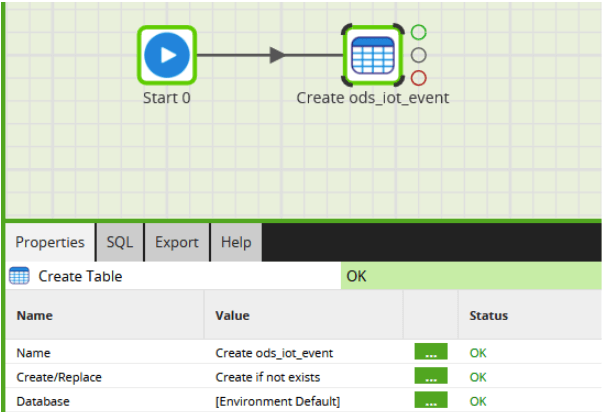
The above job needs only to be run once, to create the ODS table. After that, the data must be kept in step with the source system. This can be done by taking data from a raw input in a transformation job, or from a staging table as shown in the screenshot below.
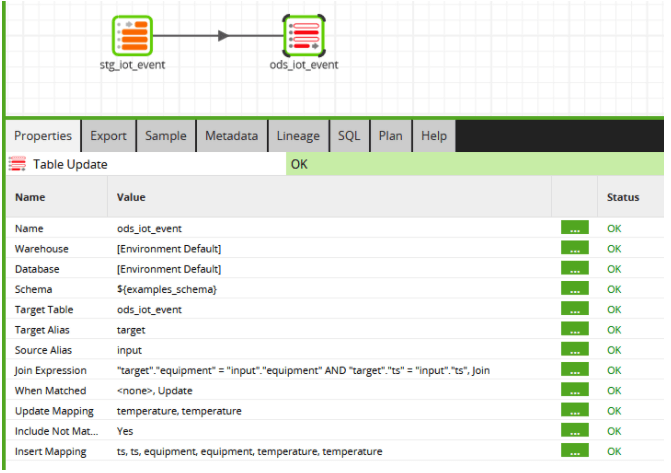
In the above example, there is both an update and an insert in a Table Update component. This is a great way to perform an idempotent change to the ODS data: a MERGE statement. There is a non-trivial cost to checking if every single new row is an update, so – depending how much you trust the source to not produce duplicate records – you may choose to use a Table Output component instead, which only ever appends records.
The main goal of a Change Data Capture (CDC) process is to maintain an ODS for one source system. A typical pattern is that the CDC process performs one potentially large initial data load into the ODS, followed by regular, much smaller, updates.
Updates may be handled in one of two ways. A CDC system may offer both choices:
- Just update the record in the ODS. Previous history is lost, but it’s simpler to query because the ODS is a copy that looks exactly the same as the source
- Never update the ODS: Instead, append a new version of every updated record. This is more like an audit trail and is slightly more difficult to query reliably. This type of data model is sometimes also known as a Persistent Staging Area.
An ODS keeps a full copy of data from its source system. Over time, data might get removed from the source system for operational or performance reasons. For example, closed accounts might get archived or even deleted from source. In this way it is possible over time for an ODS to become the system of record for that data.
Remember that all ODS data models are just a copy of the data model of one source system. An ODS layer maps to a source-oriented domain in Data Mesh. If you have two ODS databases in one CDW then there is colocation but no integration. To take that next step towards data integration you will need to create a 3NF or a Data Vault data model.
Third Normal Form (3NF) data models
A Third Normal Form area in a data warehouse is where real data integration can begin. The aim is to store data independently of the vagaries of any particular source system.
The essence of data integration in a 3NF model is that all the data on one subject is held in just one place. This is known as subject orientation.
To continue the example I have been using, imagine the business has many factories. Each factory supplies its own data to the head office. The data is held as many Operational Data Stores, each slightly different and with its own design quirks. To get an inventory of how many functional pieces of equipment the company owns in total, it would be necessary to trawl through every individual ODS, interpret the data, and then sum the counts. Whereas with an integrated 3NF data model, all the “equipment” data is held in just one place, in a single table, easy to query.
To get data into an integrated model, some transformation is usually needed in order to make the data representations consistent.
To continue the above example, in a 3NF data model there should be no need for a consumer in the head office to know that in factory A the code 99 means “functional,” and that in factory B it’s the codes 1, 7 and 19 that mean “functional.” The information should be unified in a way that enables everyone to reliably understand “functional” in the exact same way.
The data model I showed earlier, under “Data models: Nouns and Verbs” is an example of a 3NF model. You can create those structures in Matillion ETL like this:
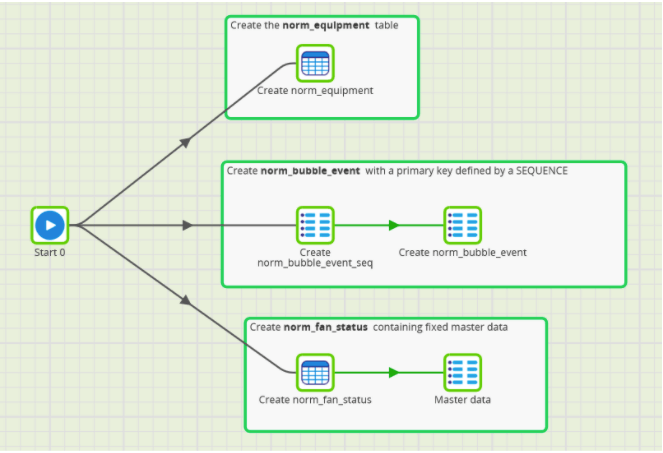
The fan status table contains only fixed reference data, and it is added at creation time in the orchestration job above. But the other two tables are data driven, and could be populated in Matillion ETL with a transformation job like this:
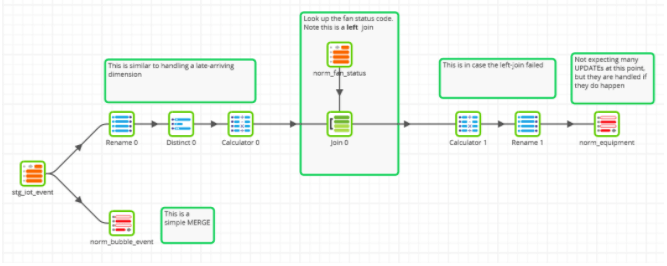
Both of the above branches end in a Table Update component in MERGE mode – i.e. with both an insert and an update. This makes the job idempotent: it can be run multiple times and the data will end up the same.
A full data warehouse solution would have many transformation jobs similar to the above, each taking data from a different ODS, and altering it to make it fit the integrated model.
Some of the reliability and consistency in 3NF comes from the fact that there are technical rules that must be followed:
- Data is stored as rows and columns
- There must be a unique identifier for every table. This is known as a primary key. For example, if you define an “equipment” table then you must have a way to uniquely identify every piece of “equipment,” and there must be only one record in the table for each.
- The granularity of the table is well defined and consistent
- Column values must be simple rather than containing sublists or substructures. This is called atomicity. It means that every single row in a given table has the exact same columns.
- You can require that a value in a particular column is restricted to only those values that already appear in another table. This technical rule is called a foreign key.
Don’t confuse 3NF, or any of the other “gold standard consumability” models with data quality. As I mentioned earlier, data quality is already excellent in the raw and staging areas. When copying new data into a 3NF data model, some transformation is almost always necessary. While doing that, the main concern is to not make the data quality worse.
Data transformations used while populating a 3NF model are the ETL embodiment of the business rules that are needed to interpret the data correctly. Typical examples include:
- Locating the correct source for all parts of the 3NF model
- Any semantic or structural transformation required to convert between models. More prosaically: looking for the data that you need from among the data that has been supplied
- Ensuring the correct granularity and the correct interpretations are used
It’s fine to have “data quality” checks when populating a 3NF model. But remember that data quality is a business problem that may have a technical solution. The best way to get data quality problems fixed is to have them addressed at source via a robust data rejection and audit process. Many data “quality problems” turn out just to be interpretation problems: The data quality is actually fine: the issue is with the reader. 
3NF is the first place where semistructured datatypes are not appropriate. Semistructured data in a 3NF model usually represents an inappropriate postponement of data integration.
A good 3NF model should have the minimum amount of data redundancy and the maximum information density. So the same data should not be stored in multiple places. If you are thinking about storing information that can be derived or calculated, then maybe a star schema or aggregate would be a better choice.
The main problem with 3NF models is that the structures are rigid and don’t lend themselves to capturing change over time: neither change to data values nor to data structures. This is one area where Data Vault comes into its own.
Data Vault models
Every Data Vault model is also a third normal form model. So all of the features and comments in the previous 3NF section also apply to Data Vault. There are some extra rules in Data Vault to help with long term flexibility and maintainability. This makes Data Vault an even better choice as the data model for large scale data integration.
One of the key observations in Data Vault is that the nouns defining the business don’t often change. A sentence I used in the example at the start was “pieces of industrial equipment that all have a built-in fan.” Core business concepts such as “equipment” and “fan” should be understandable by anyone in the business. In Data Vault they become known as Hub tables.
The things that change much more frequently are the details surrounding those core business concepts. For example, properties that differ among the various kinds of fans. Those details are important, but they are subsidiary to the core entities and are always attached to exactly one core entity. In Data Vault, this is known as Satellite information.
Something that often breaks 3NF models is when relationships change. In 3NF you might model that one piece of equipment has exactly one fan. But when a new piece of equipment comes along that has two fans, the model can’t hold that information and needs rework. Data Vault entirely sidesteps that problem by using Link entities with no restrictions on cardinality.
When populating a Data Vault model, the transformations have much in common with those you saw in the previous section for 3NF. For example you could prepare data to copy into a simple Data Vault model with a Matillion ETL transformation job like this:
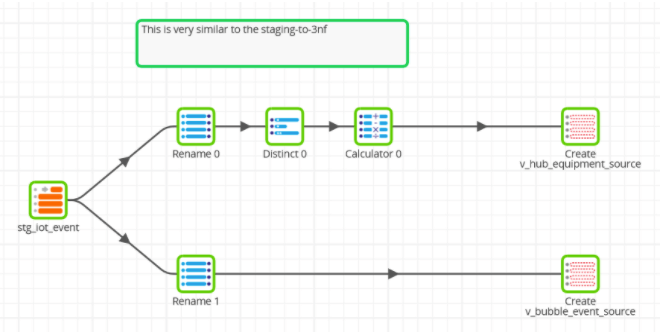
When copying data into Data Vault structures there are three main choices:
- Build the Data Vault logic as Matillion ETL transformation jobs. Data Vault implementations typically double or triple the number of tables required in an ODS, so this approach is good for a quick proof of concept but is not very maintainable.
- Use Matillion’s own extensibility features, such as Shared Jobs, as shown in the screenshot below. This is better than hand coding, although lacks sophistication and flexibility
- Use a dedicated Data Vault modeling platform, such as VaultSpeed, in combination with Matillion. This is the best enterprise class automation option.
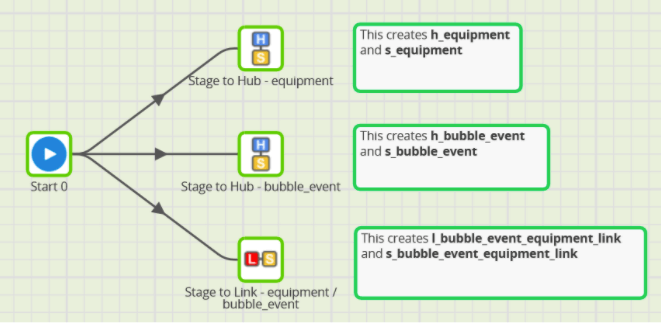
Some Data Vault models differentiate between “business” Data Vault and “raw” or “technical” Data Vault models. A “raw” or “technical” Data Vault model can be useful to facilitate ingestion from a single operational system. Only a business Data Vault model helps with data integration.
Data Vault deliberately goes some way to being a schema on read data model
- There is no limit to the number of Satellite tables you can implement for one Hub. It’s very common to have one different Satellite table per source system. Alternatively the Satellite tables may be split out by update frequency, or for information security reasons. This is simple and convenient to model. But for every Hub entity, the consumer has to decide which Satellite table (or combination of them) has the correct information. This aspect of Data Vault is close to the concepts behind sixth normal form and RDF triplestore. For this reason it can be appropriate to use semi-structured datatypes in a satellite table, even though it is technically a 3NF model.
- Data Vault link entities are always deliberately modeled as many-to-many relationships. If there is useful insight deeper than that (for example: one piece of equipment really does always only have one fan) then the consumer has to work that out for themselves
Both the above features have the effect of somewhat postponing the data integration problem. Data is not fully integrated until the interpretation has been done, downstream of the Data Vault.
In addition, both 3NF and Data Vault are well known for often requiring many relational joins during queries. This is one more factor that makes the data models more difficult to consume.
These are some of the reasons why Dimensional Star Schema data models are widely used as another way to deliver gold standard consumability.
Dimensional “Star Schema” data models
There is an understandably common misconception that a Star Schema is a data warehouse. In fact, a Star Schema model is just another kind of Third Normal Form representation: but one that was designed for ultimate gold standard consumability.
Specifically, Star Schema data models use carefully thought-out, easily understandable nouns. The language is similar to that in 3NF or Data Vault models. Although in a Star Schema everything is expressed in a more highly targeted and slightly less flexible way.
Entities in a Star Schema are differentiated into dimensions and facts. Generally, if you hear somebody talking about measuring something, then that thing is a fact. If they want to measure it by something else, then the “by” thing is a dimension.
As you would guess, Star Schema models are star-shaped when they are pictured. This means a Star Schema requires very few relational joins to navigate.
- The fact table is in the middle (Bubble Event in the data model below)
- The dimensions are around the edges (there are four of them in the data model below)
- In a “star” schema, there is only ever one depth of join between the facts and the dimensions
- In a “snowflake” schema the dimensions may cascade onto one another, with more joins required
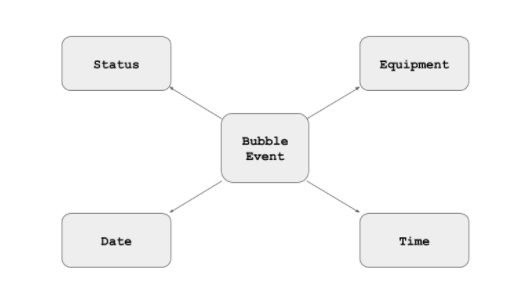
Some dimensions are universal, such as date, time, and location. Most others are specific to the business domain, and are designed according to reporting requirements.
The key benefit of a well designed star schema is that the same dimensions are used by many fact tables. This makes it very easy to reliably correlate between events and start to gain insights. As you design a dimensional model, a good sign is when the dimensions are being reused over and over. You should be able to start adding them into a grid known as a Bus Matrix, for example like this, in which every tick represents a relationship:
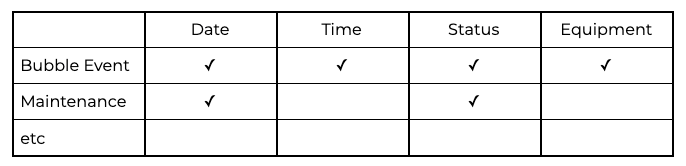
A “data mart” is often used to mean a number of closely related fact tables (i.e. rows) in a bus matrix table.
Star Schemas are usually populated from 3NF or Data Vault models. One sign of a well designed 3NF or Data Vault model is when it is easy to create a virtual star schema as a layer of views. Sometimes it can be convenient to draw data directly from Raw or Staging models, although that architecture tends to become expensive to maintain over time.
Building a dimensional model in Matillion ETL starts with table creation, for example like this:

The main data transformations are to make the joins work in a simple way. Often this uses surrogate keys or sequences, with lookups as left joins.
Data loading always has to be done in two separate parts: first maintaining the dimensions, and then updating the fact table afterwards. The ordering is necessary because the fact table requires dimension lookups that have perhaps been newly added.
Populating dimensions from a 3NF source might look like this in Matillion ETL for an equipment dimension:
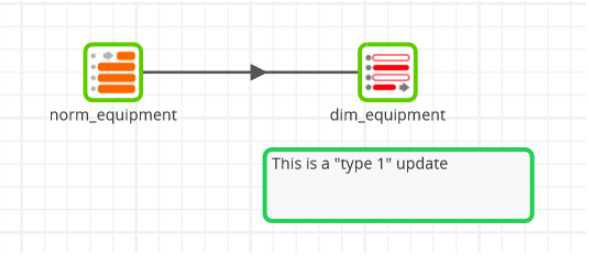
Similarly straightforward for a fan status dimension:
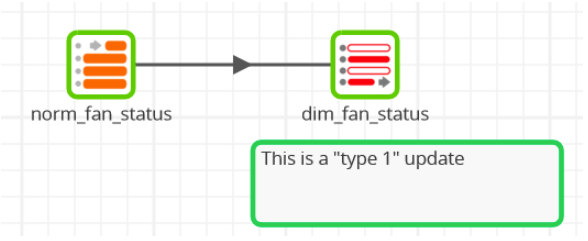
Next a screenshot of a Matillion job to prepare data for the fact table is shown below. The two dimension joins are safe to run after any new values have been added to the dimension tables.
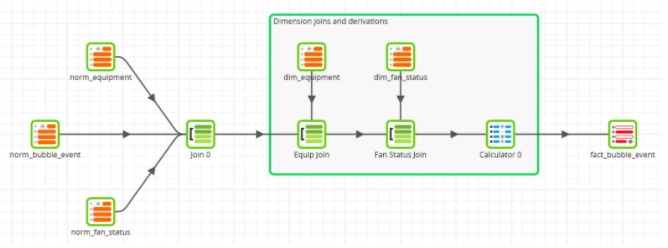
Alternatively starting from a Data Vault schema, the three updates are very similar in principle, but require more joins. Here is the equipment dimension, which has to join a Hub and a Satellite table:
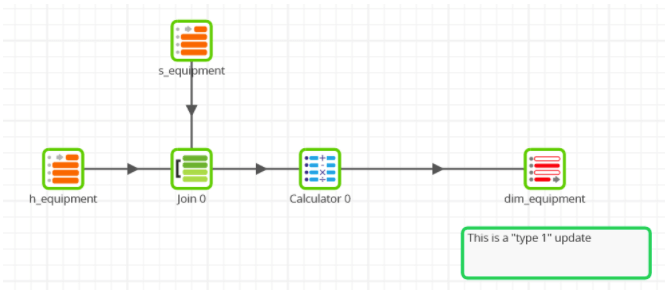
… and the fan status dimension, which just contains fixed data so requires no joins at all:
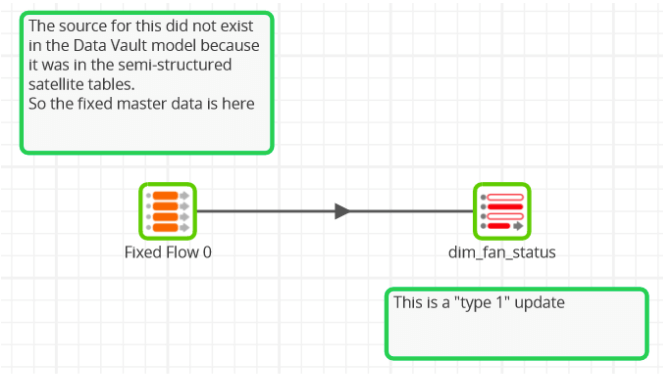
Lastly the fact table, populated from the Data Vault source tables:
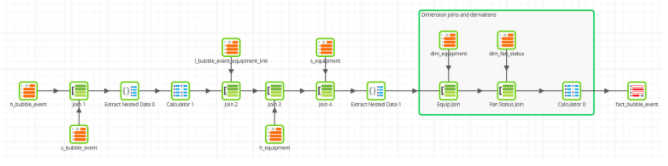
No less than seven input tables are needed this time, in contrast to the five when starting from a 3NF data model.
Notice also that I was using semi-structured data in the satellite tables, so it’s only at this late stage that you can start to unravel the last of the semantics with Extract Nested Data components. This is what postponing the data integration looks like in practice.
If you find you are doing lots of new semantic work at a granular level, it might be an indication that something is missing from the 3NF or Data Vault model. Sometimes this can get quite politically charged. To use my tongue in cheek example from earlier, is “artificial sweetener” the same as “sugar”? There are no technical solutions for this kind of question. They are business problems, and require input in the form of more business rules.
You might recall this data model from the “Structured, Unstructured, and Semi-Structured” article. The bubble events I have been using are from a chemical reaction. The main reason they are being monitored is to gain insight into how soon the reaction is likely to finish, so the factory can efficiently prepare the next batch.
The Star Schema I have presented here does contain enough information to find out how much the reaction is slowing. It is possible to average the number of seconds between bubble events over time.
But that’s actually quite a complex piece of analysis in itself. It’s likely to be needed over and over again, so it’s a great candidate for an aggregate data model.
Aggregated data models
Aggregates don’t add anything that does not already exist in the source data. Like dimensional models, they are an attempt to deliver data in the simplest, most consumable way.
You can technically create an aggregate from any other kind of data model, although it is most commonly done from a dimensional model in which the semantics are clearly documented and widely understood.
The main cases for creating an aggregate are:
- When it’s complicated for a consumer to get the information they need. The aggregate removes the complication from the consumer.
- When it’s time-consuming, or otherwise expensive, for a consumer to get the information they need. The aggregate removes the expense from the consumer, for example by summing a large amount of input data to produce a compact output
Aggregate data models are usually very simple. Often there are no joins at all, and the data can be simply given to the consumer for presentation. These Tableau dashboards are all examples of aggregates, which have been supplied to Tableau by Matillion.
Sometimes aggregate data models can be the basis of the return part of a circular data architecture. This means taking data from the data warehouse to the source systems in a sync back operation. Householding and golden record processing are examples of this.
An example of an aggregate data model in Matillion ETL is shown below. It takes data from one fact table and two dimension tables, and aggregates by hour. 144,560 input rows are converted to 176 rows of output, which is much more manageable for a small R server or a visualization tool to handle.
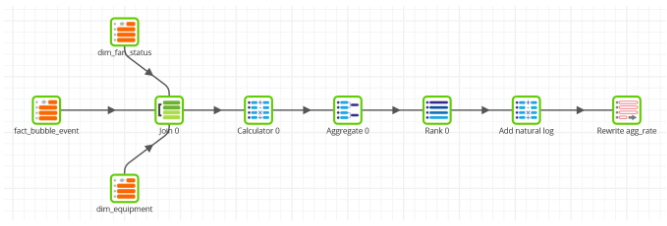
One of the final transformations is a natural logarithm pushdown. The reason for this will be made clear in a future article on the analysis of exponential decay!
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: