- Blog
- 03.27.2023
- Dev Dialogues, Data Productivity Cloud 101
Loading structured data into Snowflake - Federation vs Replication
Building a modern cloud data stack starts with getting hold of the data from all the source systems. This is called data colocation. It's the first step towards data integration.
There are two fundamentally different ways to load structured data into Snowflake:
- Replication - physically copying, either in bulk or continuous mode
- Federation - with external tables or data sharing
Which method is right for you?
This article will explore the pros and cons of each. At the same time, it will demonstrate some of the Matillion data productivity cloud features that help make data colocation easy.
Prerequisites
The prerequisites for loading structured data into Snowflake are:
- Access to Matillion
- Structured data file(s) in Amazon S3, Google Cloud Storage or Microsoft Azure Storage
- Write privilege to Snowflake
If you need to create a new Storage Integration for external stage federation:
- Access to configure RBAC and IAM in your cloud provider
- The Snowflake ACCOUNTADMIN role
The easiest way to get started is with Matillion's no-code data replication.
No Code Data Replication
I will start with the simplest case: copying a CSV file into a Snowflake table.
The data is in a world readable location, so you can build this yourself as you follow the article. You can also watch this short video of the S3 Load Generator in action.
For AWS users, bring an S3 Load Generator component onto an Orchestration Job. Use s3://devrel.matillion.com/data/structured/flights/aircraft_ref.csv.gz as the Amazon S3 storage source:  For Azure or GCP users, start instead with a Data Transfer component. Use it to copy the file into your own Microsoft Azure Storage or Google Cloud Storage location. The HTTPS source URL is https://s3.eu-west-1.amazonaws.com/devrel.matillion.com/data/structured/flights/aircraft_ref.csv.gz
For Azure or GCP users, start instead with a Data Transfer component. Use it to copy the file into your own Microsoft Azure Storage or Google Cloud Storage location. The HTTPS source URL is https://s3.eu-west-1.amazonaws.com/devrel.matillion.com/data/structured/flights/aircraft_ref.csv.gz 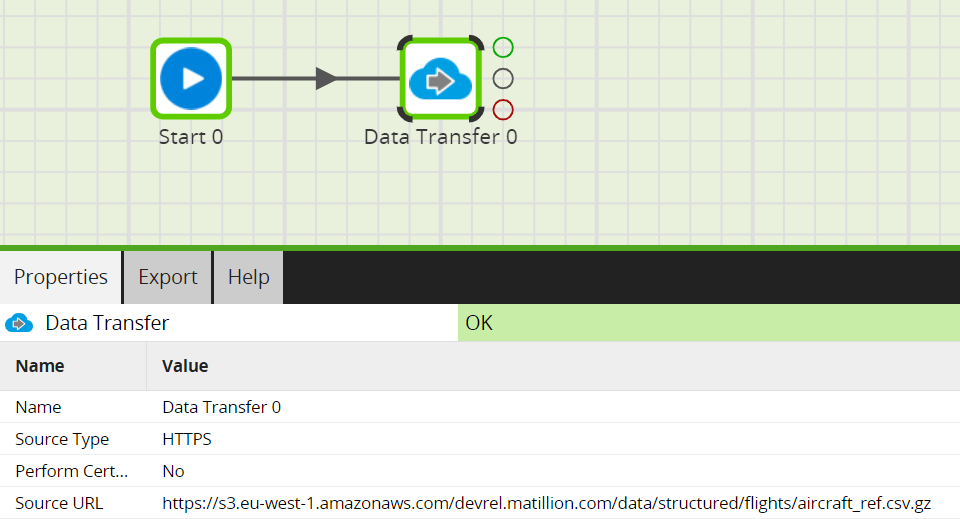 After running the Data Transfer, Azure and GCP users should use an Azure Blob Load Generator or a Cloud Storage Load Generator to pick up the file.
After running the Data Transfer, Azure and GCP users should use an Azure Blob Load Generator or a Cloud Storage Load Generator to pick up the file.
In the Load Generator select GZip compression and press "Get Sample". You should see the first rows. 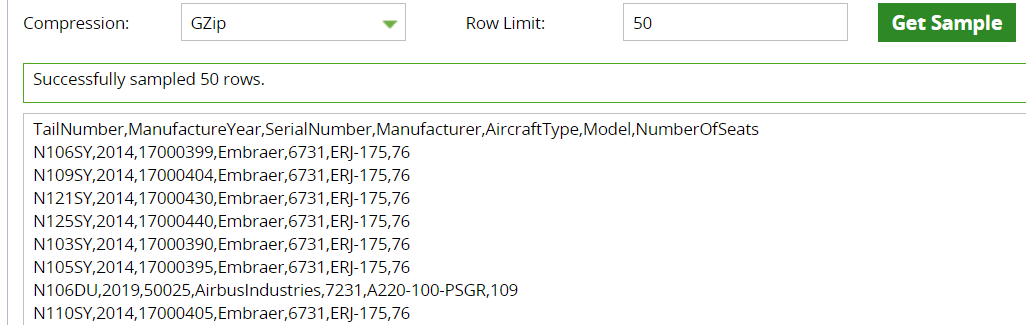 The defaults work fine with this file, and it should guess the schema correctly:
The defaults work fine with this file, and it should guess the schema correctly: 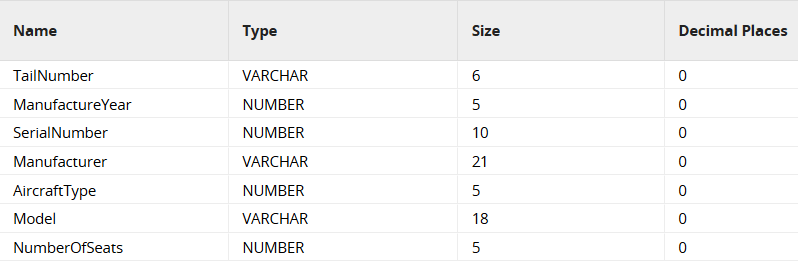 The S3 Load Generator creates two new components on the canvas: a Create Table and an S3 Load. Link them to the Start icon, and then run the job.
The S3 Load Generator creates two new components on the canvas: a Create Table and an S3 Load. Link them to the Start icon, and then run the job. 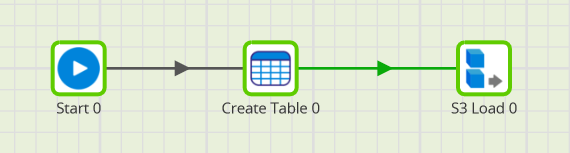 Snowflake's data loader is flexible enough to do some data transformation during the load process. In the example above, some columns are converted to numeric during the load.
Snowflake's data loader is flexible enough to do some data transformation during the load process. In the example above, some columns are converted to numeric during the load.
But really, CSV files contain strings that look like numbers, and strings that look like dates. You can reduce the risk of runtime format errors by loading all the columns as VARCHAR.
| Treat all CSV columns as VARCHAR during loading, unless you are confident the file structure will not change over time. |
Matillion has many other Low-Code or No-Code loading components. Notably the Database Query, which replicates from a structured, relational source database into Snowflake.
In the example below, the Database Query highlighted reads from a table in a MySQL database. It is a rectangular shaped dataset, the same as a CSV file. 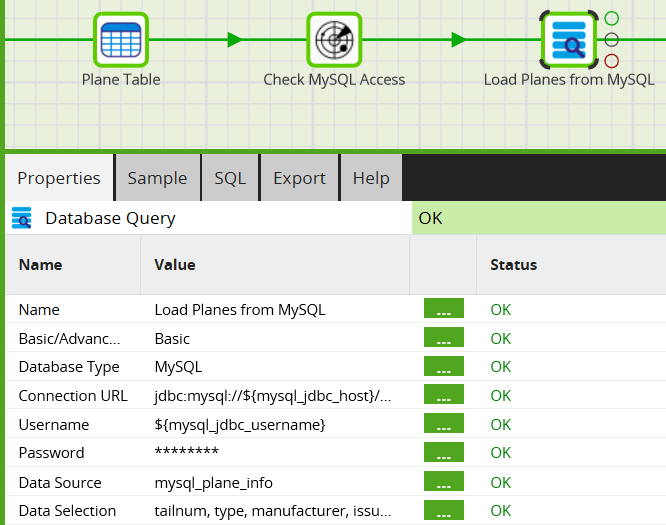 Exactly the same as the CSV example, there is a Create Table component first. Database connectivity can be vulnerable to a variety of transient network problems, so a Check Network Access shared job is there to help detect them.
Exactly the same as the CSV example, there is a Create Table component first. Database connectivity can be vulnerable to a variety of transient network problems, so a Check Network Access shared job is there to help detect them.
| For proactive network problem detection, use a Check Network Access component immediately before a Database Query. |
So far I have been talking about "bulk" loading. This is all about replicating larger amounts of data relatively infrequently.
Getting nearer to real time involves loading smaller amounts of data, more frequently. This is the goal of loading continuously.
Loading Continuously - Matillion Data Loader and Snowpipe
Matillion Data Loader (MDL) is the Data Productivity Cloud's SaaS based data loading platform.
MDL offers microbatch style incremental replication, from a variety of sources into Snowflake. For example, from Microsoft SQL Server:  MDL also offers a log-based physical change data capture (CDC) style replication. It uses an agent container to capture all database changes as an event stream. The agent writes the changes in near real time (NRT) to a cloud storage destination such as Amazon S3:
MDL also offers a log-based physical change data capture (CDC) style replication. It uses an agent container to capture all database changes as an event stream. The agent writes the changes in near real time (NRT) to a cloud storage destination such as Amazon S3:  MDL's CDC agent writes out partitioned files. The result is flexible and open, and can be read, for example, by:
MDL's CDC agent writes out partitioned files. The result is flexible and open, and can be read, for example, by:
- Matillion ETL - which has a set of Shared Jobs for this purpose
- Snowpipe - Snowflake's continuous inbuilt data ingestion service
Pros and Cons of data replication
Advantages of loading by copying - i.e. replicating - data include:
- Copying into Snowflake is the point when a schema can start to be enforced. That means well-defined, consistent column names and datatypes. It is the start of making the data highly consumable, and especially applies to file sources.
- The copy in Snowflake is easy to read. It is easy to aggregate, join and integrate with other data that has also been copied into Snowflake.
- Working on the data happens inside Snowflake, and takes advantage of Cloud Data Warehouse scalability and economics. The effect is more pronounced the larger the data sets.
- Replication brings data under your control inside Snowflake. You can choose to make all newly-loaded data immutable (never-changing). This is good practice for audit and governance.
- Snowflake itself has a DataOps feature of refusing to re-load a previously-loaded file. This helps with job rerunnability.
Disadvantages include:
- You end up with two copies of the data: one outside and one inside Snowflake. Both have a cost. It also introduces a vector for ambiguity. Which copy is right?
- Multiple copies can lead to the data culture problem in which Data Engineers, Data Scientists and BI Analysts all use the original sources. They end up repeating the same remediation and integration work.
- Loss of flexibility as the data moves from an open format into a vendor-specific format.
| For file sources, there is a good way to mitigate the two-copies problem. Move the original file into "offline" or "archival" cloud storage after it has been loaded into Snowflake. |
Data Lake Federation with External Tables
Federation is an alternative data loading approach. Rather than make a new copy of the data, federation means virtualizing. The copy still happens, but only at the moment when the data is read.
Matillion's no code interface to Data Lake Federation on Snowflake is the Create External Table component. It creates a Snowflake external table object, which is a pointer to files in an external stage.  A Snowflake external table only stores metadata such as structure and location. No data is actually held in an external table. There is a zero row count at the moment of creation:
A Snowflake external table only stores metadata such as structure and location. No data is actually held in an external table. There is a zero row count at the moment of creation: 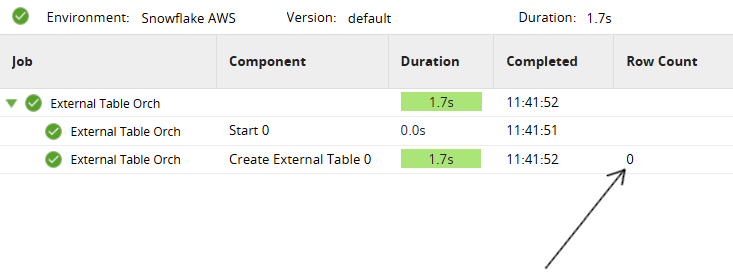 Since they contain virtualized data, external tables are read-only. But everything else about them works exactly the same as ordinary Snowflake tables. That means external tables can blend straight into any Matillion data integration job, as you can see in this external table demonstration video.
Since they contain virtualized data, external tables are read-only. But everything else about them works exactly the same as ordinary Snowflake tables. That means external tables can blend straight into any Matillion data integration job, as you can see in this external table demonstration video.
Pros and Cons of data federation
Advantages of loading by virtualizing - i.e. federating - data include:
- The effect is immediate
- There is less scope for ambiguity and argument since there is always only ever one copy of the source data
- You only pay to store one copy of the data
- External tables are just as easy to read as ordinary tables. They can be aggregated, joined and integrated with other Snowflake data using the ordinary SQL of a Matillion transformation job
- Working on the data happens inside Snowflake, in exactly the same way as for ordinary Snowflake tables
- The source data remains in an open format
Disadvantages include:
- You can't enforce your own schema: it is dictated by the contents of the files
- Every read has a data transfer and compute cost
- You may need to periodically refresh the external table
- External data files may not be fully under your control. The data may not be immutable. Audit and governance must include the external storage area too
- Certain optimizations may not be available - such as columnar data access
Next Steps
This has been a quick guide to the pros and cons of the two main ways to load data into Snowflake: replication and federation.
I have talked exclusively about structured data in this article. That means data with rows and columns, like CSV files and relational database queries. In a future article I will discuss semi-structured data more generally.
Snowflake supports other kinds of external tables too, including Apache Hive and Apache Iceberg. You may also consider using Secure Data Sharing to share data with another account, or on the Snowflake Marketplace.
For more information about how Matillion ETL and Snowflake work together in a modern enterprise data stack, download our ebook, Optimizing Snowflake; A Real-World Guide.
Andreu Pintado
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: