- Blog
- 06.12.2020
Shared Jobs in Matillion ETL: How to Create Variables (Part 1 of 2)

This two-part blog will walk you through setting up and creating a Shared Job in Matillion ETL using variables. In Part 1, we will walk you through the setup process for Job and Grid Variables to use later in a Shared Job. Part 2 will look at creating and packaging the Shared Job.
What is a Shared Job?
There are times when orchestrating and transforming data can be tedious, due to the large amounts of data and tables to process. Users sometimes need to create many similar but distinct jobs to perform repeated functions on tables. These jobs may only have minor differences. To address this job fatigue, Matillion came up with the concept of Shared Jobs.
Shared Jobs bundle entire workflows – Orchestration jobs (and the Transformation jobs they link to) – into a custom component. Within Matillion ETL, users can create their own components using the Shared Jobs feature. Shared jobs help developers in two ways: they can help save development time when it comes to common workflows. And, you create templated jobs that you will use again and again across your projects.
Let’s look at the Matillion ETL functions and features you will need to understand in order to build your own Shared Jobs.
Job Variables
In Matillion ETL, you have the ability to create Job Variables, which, if you are familiar with programming, are essentially scalar variables. Job Variables can be used to define a reference to a value instead of hard coding a value. In the context of Shared Jobs, Job Variables can be set up within the Shared Job but with the value supplied later, since the value may be unknown to the creator of the Shared Job. This means that it is possible to create jobs that can be driven by configuration instead of fixed values. For example, if we are writing one job to process multiple tables with different names, all we need to do is set the Table Name within the job to be a variable.
How to Create a Job Variable
In this example, we have three tables of data from different warehouse orders that we want to manage. In creating a Job Variable, we only need to configure the variable once and then we can reuse it. This is helpful because it makes development easier and prevents the need to duplicate logic. As we add more warehouses, we can easily and quickly combine this data within an existing ETL flow by reusing our existing Transformation Job and just running it again with the new table name passed into the Job Variable.
First, create a Job Variable by clicking ‘+’ in the bottom left-hand corner of your Matillion ETL screen. When configuring your Job Variable, you can set:
- Name: Specify the name of the variable which you will later reference.
- Type: Specify the Matillion ETL Data Type as text, numeric, or datetime.
- Behavior: Set the branch behavior inside a job. This determines how the variable is updated when more than a single job branch is making use of it.
- Visibility: Select either Public or Private. When a variable is private, it cannot be discovered or overwritten when this job is called from a Run Orchestration or Run Transformation component. For this reason, visibility should be set to Public for use in a Shared Job, if you wish for the value to be set by the end user of your Shared Job.
- Default Value: Set the default value for this variable in this job. The default value will be used to validate the shared job during development – and is the value used if a value is not passed in by a calling job.
In this example we will be creating a variable called source_table which will be of type Text, will have a Shared behaviour, will be publicly visible, and will have a default value of orders_warehouse_1.
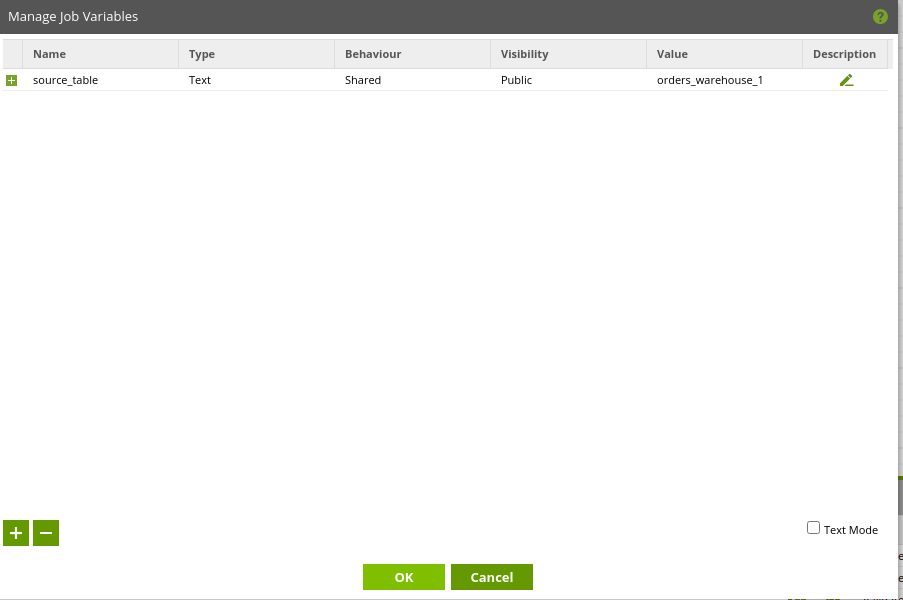
Note: because we set a Default Value of a table with the structure we require – Matillion ETL is able to read the table structure and thus the job can validate.
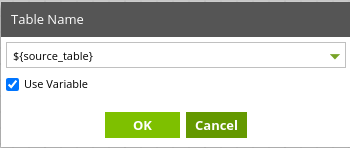
When you want to reference your new variables in your job, you will be able to use ${variable}, with ‘variable’ being the name of the variable you set. In our example, this will be ${source_table} to reference a warehouse orders table.
This simple example Transformation Job simply appends all of the rows from the source table into the target table.
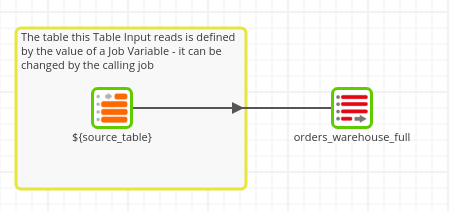
If we run this job directly, it will use the default value of the variable. However, if calling from a parent Orchestration Job, we can override this default value. Below you can see that we have brought the same Transformation Job into our Orchestration Job three times to account for each table of warehouse order data.
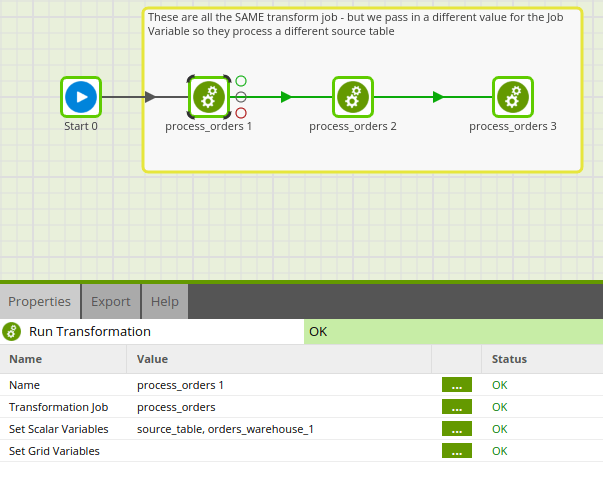
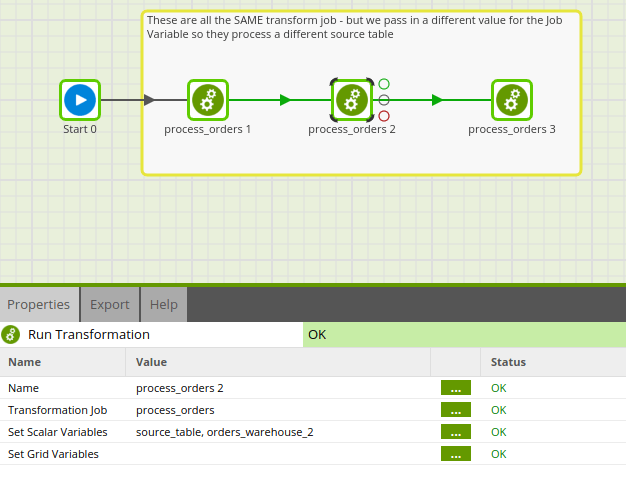
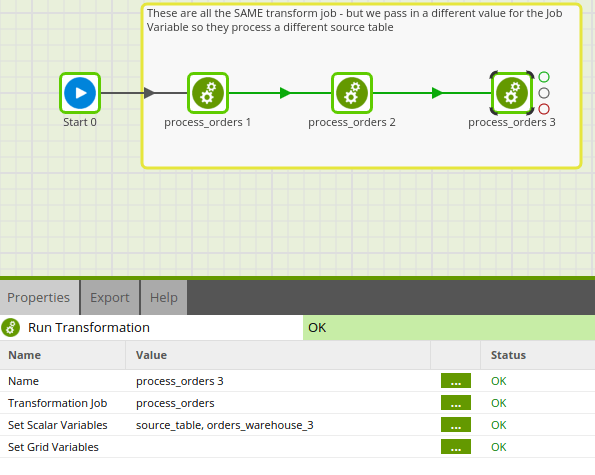
You can see from the Properties of the Run Transformation component we are running the same Transformation Job 3 times, but passing in a different value for the ${source_table} variable
To add another table, we would follow the same quick process and add a fourth run of the Transformation Job, but pass the new table name when calling it. Alternatively, if our source table structure changes, we only need to amend the one Transformation Job and the logic will be applied to the processing of all four warehouse order tables.
Grid Variables
Also common in Shared Jobs is the concept of a Grid Variable. Unlike a Job Variable, which can only hold a single value, a Grid Variable can hold multiple values (similar to a 2D array found in many programming languages). This is helpful if you have a commonly used set of values that you want to replicate in a number of different jobs: For example, filter conditions or a selection of data columns within a Data Source component (i.e. Salesforce). If we take our previous example, we realize we want to filter the order_dates from each warehouse. We can add a Filter component to our existing Transformation Job.
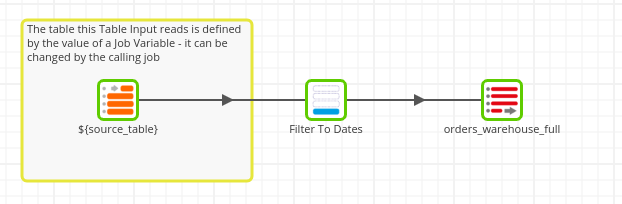
We only want dates from a specific year, so we set out filter criteria:

However, by hard coding the above it will apply to every run of the table, even if different warehouses need different filter rules. If each warehouse needs a different set of dates – we can still use a single Transformation Job by adding a Grid Variable.
To add a Grid Variable, right-click on the desired Orchestration or Transformation Job within the explorer panel and select Manage Variables>>Variables>>Manage Grid Variables.
Create a Grid Variable by clicking ‘+’ in the bottom left-hand corner. When configuring your Grid Variable you can set:
- Name: Name of the variable, which you will later reference
- Type: Matillion ETL Data Type as text, numeric, or datetime.
- Behavior: Determines its ‘branch behavior’ inside of a job. That is, how the variable is updated when more than a single job branch is making use of it.
- Visibility: Select either Public or Private. When a variable is private, it cannot be discovered or overwritten when this job is called from a Run Orchestration or Run Transformation component. For this reason, visibility should be set to Public for use in a Shared Job.
- Description: Write a description for the Grid Variable. This description has no consequence or functionality beyond being present in the dialog for editing the variable and when this job is being called through the Run Transformation and Run Orchestration components.
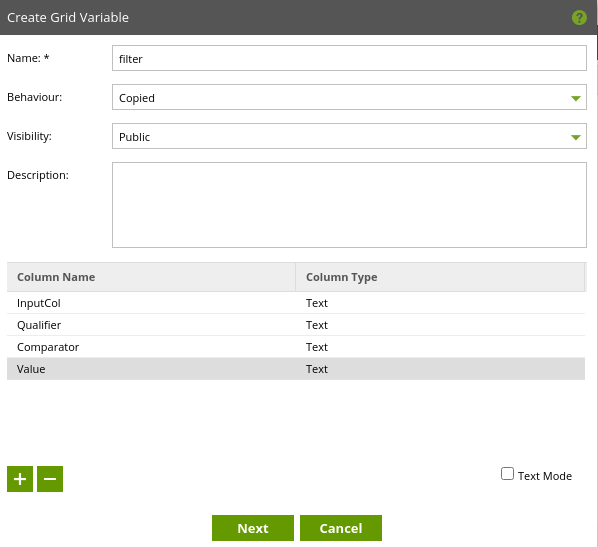
The Grid Variable needs the same columns as the Filter Conditions from the Filter component, also set the default values. Like the default value for a Job Variable, these values will be used when running the job unless values are passed in from a calling parent job.
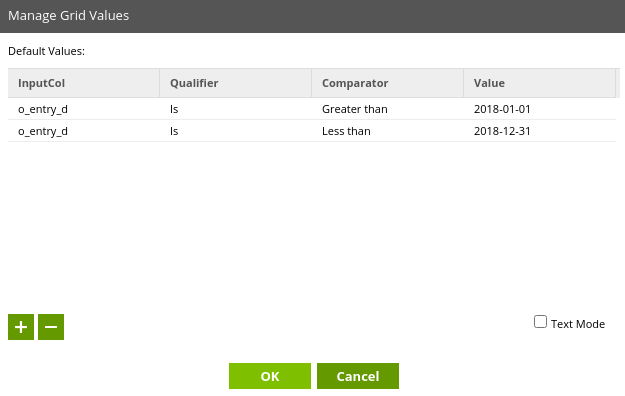
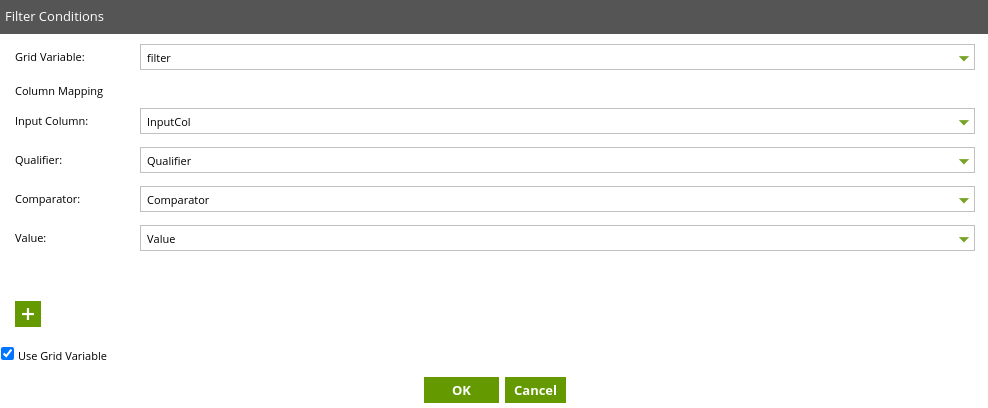
You can use Grid Variables anywhere in Matillion ETL where there is a ‘Use Grid Variable’ checkbox. Going back to the Filter component – click “Use Grid Variable”, and then map the Grid Variable columns to the component columns:
Now that our Grid Variable is set up, we can jump back into our Orchestration Job that runs the same Transformation Job for the three warehouses. We now need to set the values to pass into the Transformation Job to override the default values. Under Properties, select ‘Set Grid Variables’.
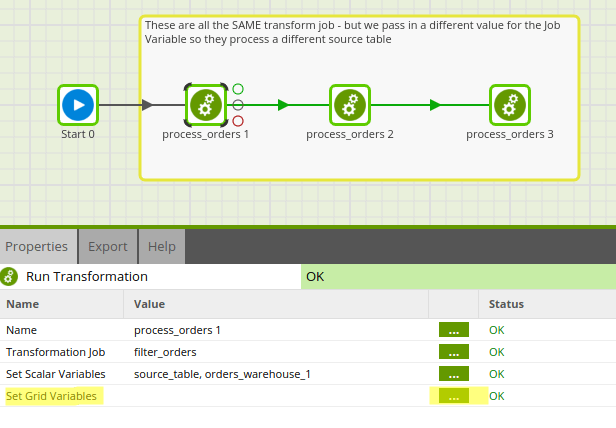
Now we can apply our Grid Variable for the filter for each table of warehouse order data. Pictured below is the filter for process_orders 1. We will follow the same steps for process_orders 2 for 2016, and process_orders 3 for 2017.
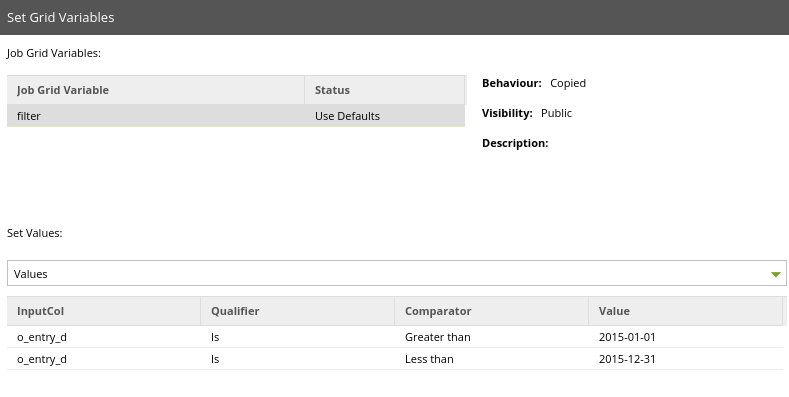
Now using a combination of the Job Variable and the Grid Variable, the same Transformation Job is running for different source tables, and filtering different dates. While this may seem like a lot of sets for a relatively simple job, the time savings when working with complex ETL jobs can be significant for your development team. You can expect faster development times, and lower overhead of maintenance of jobs since you can control changes from a single variable.
To learn more about how to configure Grid Variables, check out this video:

5:08
Next in the series: Creating a Shared Job
Now that you have a better understanding of Job Variables and Grid Variables you are ready to get started building Shared Jobs, which we will explore in Part 2 of this series.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: