- Blog
- 12.20.2022
- Dev Dialogues
VaultSpeed and Matillion - get productive with Data Vault
Enterprise scale data integration makes high demands on your data architecture and design methodology. Choosing to add a Data Vault layer is a great option thanks to Data Vault's unique ability to handle long-term integrated storage of data.
This article will talk about Matillion's partnership with VaultSpeed. It will describe how the platforms work together to deliver productivity gains with Data Vault.
- Matillion is the Data Productivity Cloud - the #1 Low-Code/No-Code (LC/NC) platform for designing, building and orchestrating cloud data integration projects
- VaultSpeed is the #1 automation platform for Data Vault modeling and design
Prerequisites
To design and deploy Data Vault 2.0 solutions using Matillion and VaultSpeed, you will need:
- Access to VaultSpeed
- Access to Matillion ETL
- Some familiarity with Data Vault 2.0 concepts will be useful
What is Data Vault?
At its core, Data Vault is a data modelling technique. It is best deployed in the middle tier of a multi-tier data architecture. Data Vault 2.0 goes further to define a whole system of business intelligence, including an agile development methodology.
Data Vault has similarities with anchor modelling, and shares with RDF triplestore a natural ability to deal with business changes over time - known as schema drift. These features combine to make Data Vault well-suited to handle the largest and most sophisticated data integration challenges. It becomes more valuable the more data sources are involved.
Below is a small example Data Vault model concerning the relationship between retail customers and shops. In the center, the two "hub" tables plus a "link" model the transactional event of a customer visiting a shop. Six surrounding "satellite" tables provide all the contextual data, and deal with information security. 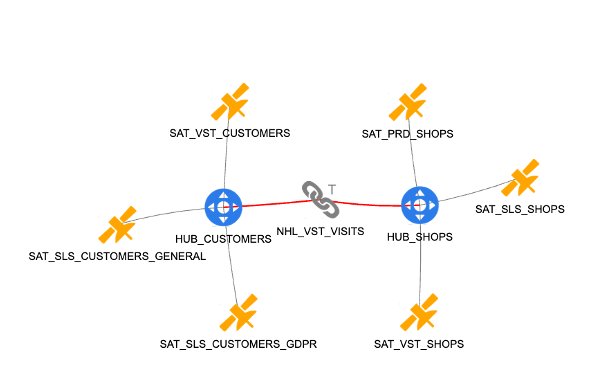 Compared to 3rd Normal Form - a widely used alternative - Data Vault is much better able to handle schema drift.
Compared to 3rd Normal Form - a widely used alternative - Data Vault is much better able to handle schema drift.
However, Data Vault is more complex to design and implement than 3rd Normal Form. Some downstream data transformation is often used to present data in a more consumable way - usually as a star schema.
As a consequence, Data Vault is well suited for productivity gains through LC/NC and automation.
Conceptual and Business models
Data Vault modeling involves converting multiple source data models into a single integrated Data Vault model.
A Raw Data Vault is used to store the unfiltered data from the source as Hubs, Links, and Satellites. The Data Vault model represents your business: it should contain the entities, attributes and relationships that are familiar to the people who work with you.
Building a conceptual data model that accurately reflects your business has a lot of value. This conceptual model contains the taxonomies and ontologies that describe various concepts in your organization. Working together with business users on a conceptual data model will uncover some of the variations in semantics, definitions, and common understanding of how the organization works.
Put your conceptual model into practice by incorporating it into the physical Data Vault model. This becomes the design blueprint for your relational database, including column names, lengths, primary keys and foreign keys.
The conceptual model never exactly matches the source data models. Differences will exist in implemented taxonomy levels. Multiple business keys will be tangled up in single source structures. Model driven automation can help streamline this. 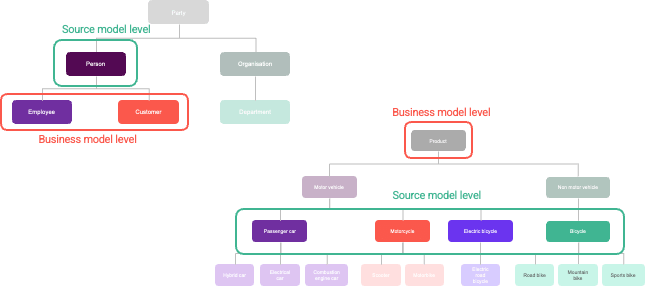 Differences in taxonomy levels in source and target data models
Differences in taxonomy levels in source and target data models
As a natural part of any healthy evolving business, conceptual models change over time. There is never one single, permanent, ideal representation that everyone agrees on! VaultSpeed's model driven automation ensures that these changes can be handled efficiently.
How VaultSpeed accelerates Data Vault modeling
VaultSpeed focuses primarily on Data Vault 2.0 to automate integrating data from various sources into a Cloud Data Warehouse (CDW).
Automating Data Vault in VaultSpeed focuses on modeling your Data Vault to match the business needs. The entire process is No-Code. The interface is a parameterized data modeler with object type and attribute type tagging. This is where the entire Data Vault model is designed. Afterwards the tool generates the DDL, alongside the transformation and orchestration logic for implementation in Matillion.
Let us explain with an example. Imagine a motor vehicle dealership that wants to keep track of their customers visiting their various outlets. There are three data sources to integrate:
- The CRM system
- The stock management system
- A data stream tracking shop visits
VaultSpeed has a seven step approach to automating this process.
Step 1 - Harvest metadata
VaultSpeed harvests metadata from each of the three sources to speed up the modeling process. It operates using JDBC, so thousands of source types are accessible.
Step 2 - Tech stack parametrization
This is how complexity in the data stack is handled. The operator selects the technologies and versions of their sources, plus the target platform. In addition there is a choice of settings for Data Vault 2.0, including the Matillion Change Data Capture (CDC) method in use. The settings related to CDC are shown in the screenshot below.  CDC parameter settings in VaultSpeed to integrate seamlessly with Matillion’s CDC solution
CDC parameter settings in VaultSpeed to integrate seamlessly with Matillion’s CDC solution
Step 3 - Business model mapping
The Data Vault model must reflect your specific organization and processes. VaultSpeed makes business model-driven automation easy. To begin, the operator can easily import an existing conceptual data model using REST API integrations. Then, using a powerful source editor, build the Data Vault model.
At this stage the operator may tag business keys, and change or add relationships, group hubs or split source entities and/or satellites. Metadata harvested from the sources give users a head start in the modeling process.
The resulting data model will be Data Vault 2.0-compliant and will be translated into structures by VaultSpeed. 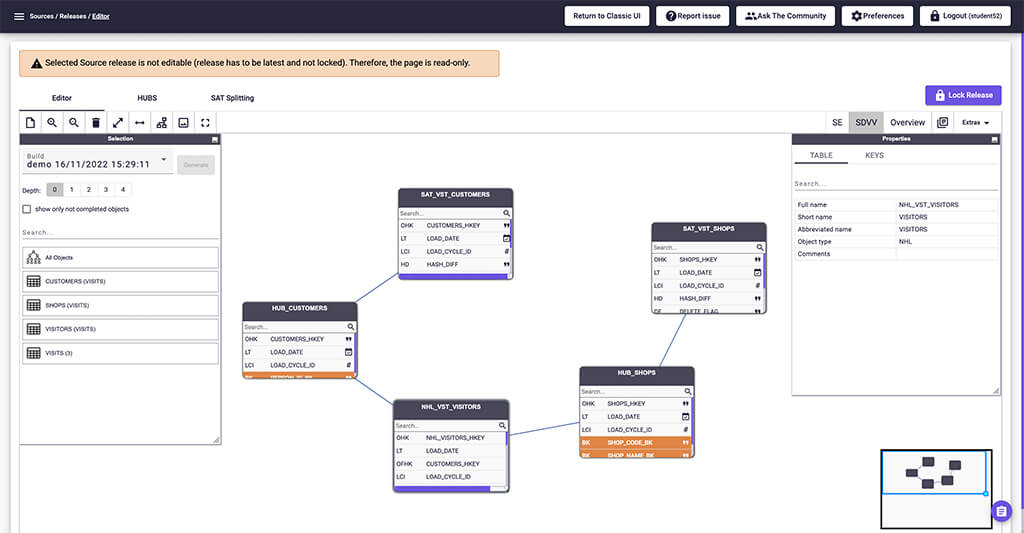 The proposed DV2 model based on your business model
The proposed DV2 model based on your business model
Step 4 - ETL & DDL code generation
VaultSpeed generates the DDL code to physically build the data model. It is deployed onto the target CDW - for example Snowflake or Databricks. This can be done either using VaultSpeed's secure agent, or with a DataOps tool.
VaultSpeed also generates ETL mapping instructions for data transformation, in the form of Matillion ETL transformation jobs.
The push of a button starts the code generation process. 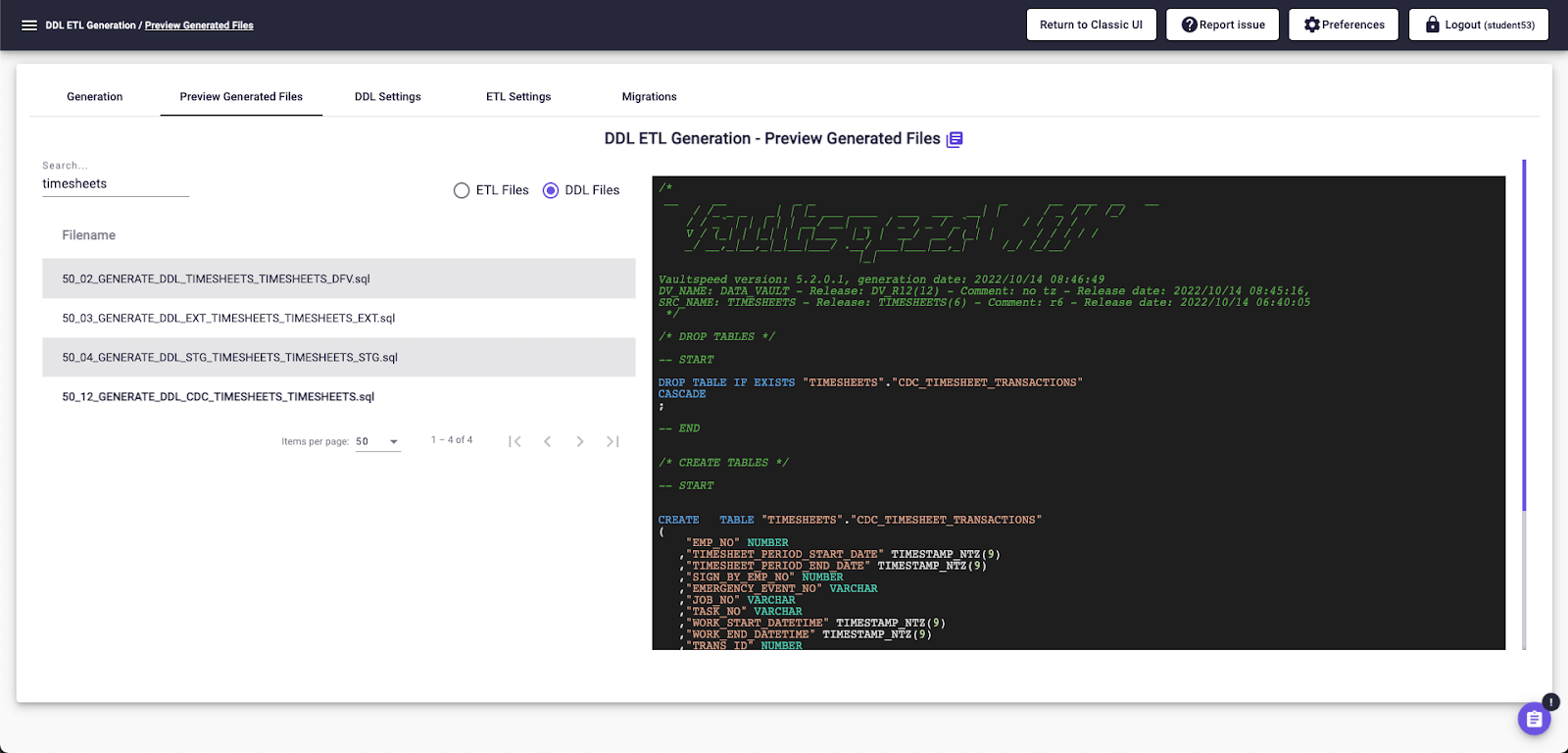 Example of DDL code generated by VaultSpeed
Example of DDL code generated by VaultSpeed
Step 5 - Pipeline deployment
VaultSpeed connects to Matillion and the underlying CDW, sending instructions to build the ETL mappings and the Data Vault model. A secure agent automatically deploys the generated jobs to Matillion. 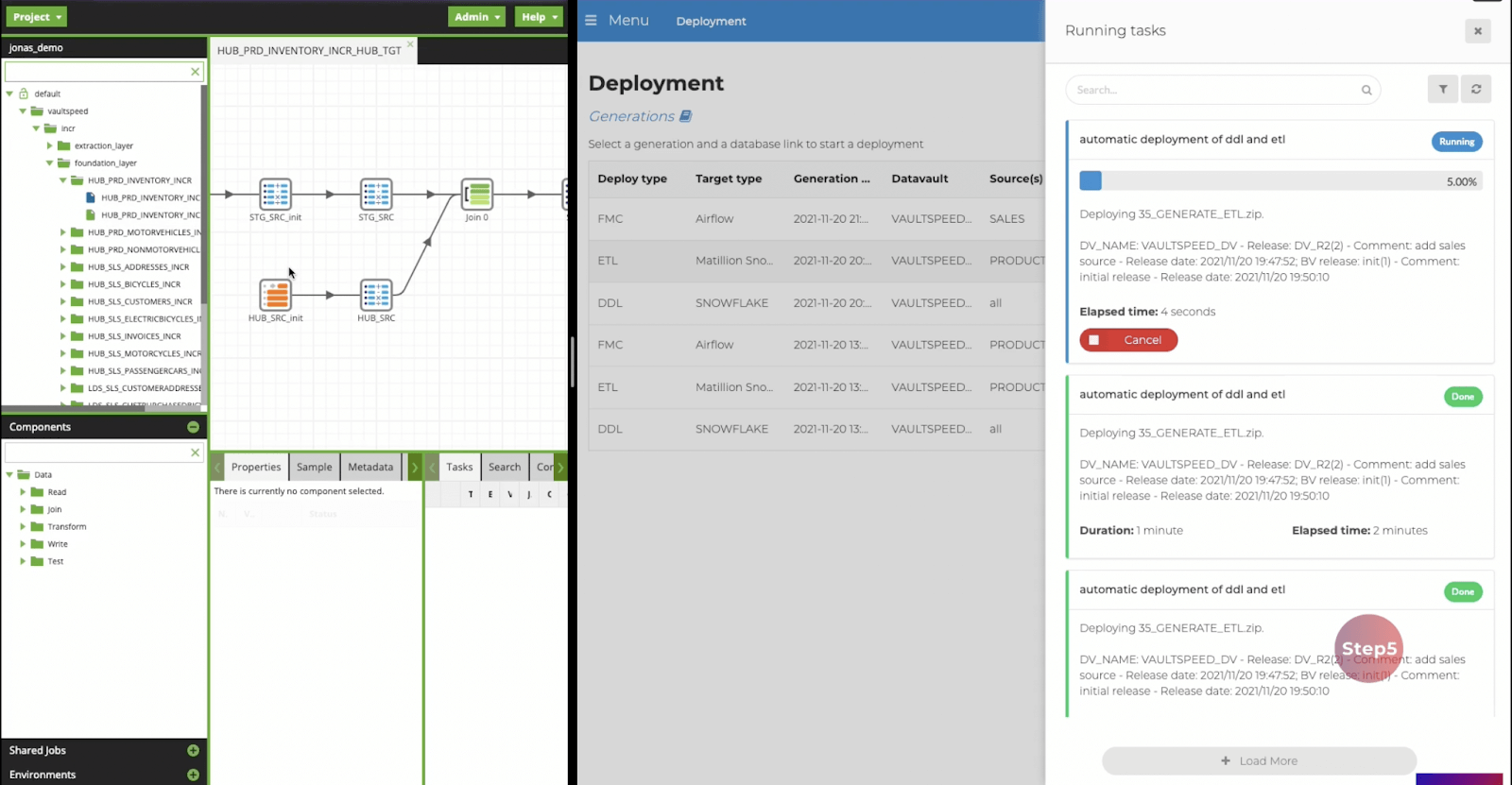 Deployment of ETL mappings into Matillion ETL
Deployment of ETL mappings into Matillion ETL
Step 6 - Orchestrated data loading
Once the pipeline is deployed, the system is ready to load data into the data warehouse, transforming it to create analysis-ready data. VaultSpeed having provided the design and model, it is at this point that Matillion takes over and provides the runtime.
Step 7 - Repeat
Whenever sources or requirements change, iterate steps 1-6 to keep your Data Vault 100% relevant and on track.  The 6 steps in the Data Vault modelling process
The 6 steps in the Data Vault modelling process
How Matillion accelerates productivity
Data Vault models are used in the middle tier of a data architecture. Matillion is used to design and implement the surrounding tiers:
- Before - data loading
- After - data transformation - for example to a star schema
Matillion acts as the orchestrator that runs the jobs designed in VaultSpeed. Matillion also ensures that the data loading, data vault tasks, and data transformations happen in the correct order.
The end-to-end data architecture looks like this: 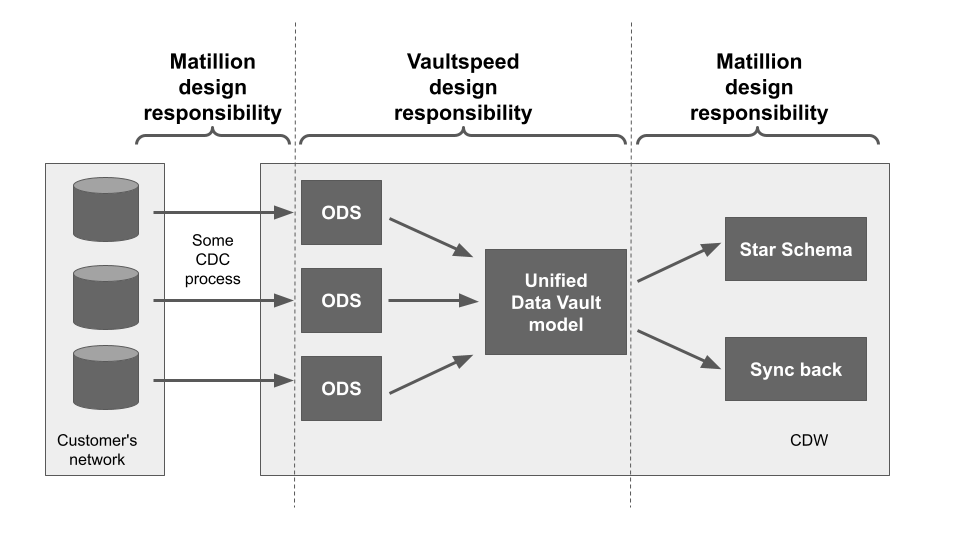 Matillion's Low-Code / No-Code data integration interface speeds up development and deployment for Data Vault, Star Schema and Third Normal Form data models.
Matillion's Low-Code / No-Code data integration interface speeds up development and deployment for Data Vault, Star Schema and Third Normal Form data models.
You may choose to use Matillion Data Loader's change data capture in either batch or CDC mode.
The process model showing how Matillion and VaultSpeed work together looks like this: 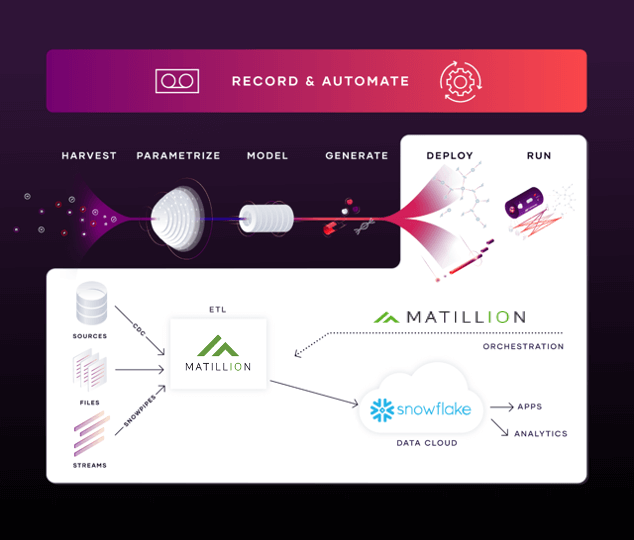 VaultSpeed & Matillion integration for Snowflake
VaultSpeed & Matillion integration for Snowflake
Next Steps
Matillion helps teams get data business ready, faster, accelerating time-to-value and increasing the impact data can have.
Get a demonstration:
Further reading:
- Create a Data Vault model business users will understand
- Why Data Vault is the best modeling method for automation
- Building a scalable data warehouse with Data Vault 2.0, by Daniel Linstedt and Michael Olschimke
- The elephant in the Fridge: Guided Steps to Data Vault Success through Building Business-Centered Models, by John Giles
Andreu Pintado
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: