- Blog
- 04.07.2022
- Data Fundamentals, Dev Dialogues
Data Has State – Data Functions and Design Patterns
This is the final article in a five-part series on data integration. The series covers the following foundational topics:
- Data-Oriented Programming needs Data Integration – App and format proliferation, the challenge of a process oriented mindset, data colocation vs integration, data integration methodologies and boundaries
- Creating Highly Consumable Quality Data with Data Integration – Data quality, centralization and interdependence, semi-structured data considerations
- Create Data Driven Organizations with a Good Data Culture – ETL and data science teams, interfacing with the wider business
- Data Change Management – Iterate Rapidly and Track Lineage – Change as an opportunity, low-code/no-code, data lineage
- Data Has State – Data Functions and Design Patterns (this article) – data processing functional design patterns, and the development lifecycle

Statefulness is unique to software that integrates data. It means that data processing software can never be fully understood in isolation. What happens next always depends very much on what happened before. This has a big impact on the ability to iterate data processing solutions quickly and reliably.
The goal of data integration is to combine data in a highly consumable way to extract joined up information and insights. Integrated data meeting that criteria is fit for purpose and therefore has good data quality. But the quality of the software is not related to the quality of the data. Even if the data processing software ran well, it does not mean the data ended up fit for purpose.
For example, if a report was wrong, or an ML algorithm unreliable, none of the following justifications would be helpful:
- The data processing software adhered 100% to the specification
- It ran in the cloud
- It was written in the latest fashionable programming language
- There were no errors or warnings when it ran
- It ran very quickly
- It was fine last week
None of the above statements say anything about the data. They all fundamentally come from a process-oriented viewpoint. The arguments would be more valid in a stateless, lambda, or microservices environment, but not in data processing. So what is it about data processing functions specifically that makes them so different?
Data processing functions
There is a lot of good contemporary material on design patterns that is relevant to transactional processing within application architectures. Examples include REST and object oriented design.
For these transactional, “stateless” types of functions, things are relatively simple. All the input data is passed into the function through formal, well-defined parameters. The function calculates whatever it needs to, and returns all the outputs back to the caller.

A well designed stateless function has two further important properties:
- The function is deterministic. Meaning that, if you run it again providing the exact same inputs, you will always get back the exact same outputs.
- There are no “side effects.” Meaning that the function does absolutely nothing in the background to change any data stored elsewhere. This is the definition of “stateless.” Stateless functions are guaranteed to be independent from each other, and they have no “memory” from previous invocations.
For a data processing function, however, it is a different story. There are usually still some formal inputs and outputs, but the function’s main purpose is to interact with – and change – data in some way:
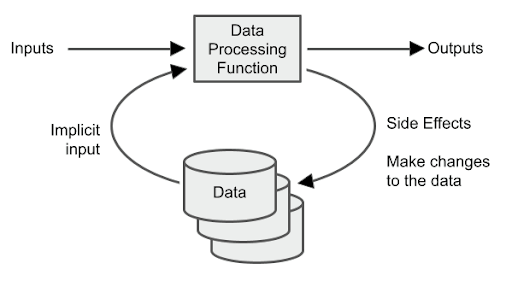
In fact, side effects on the data are the primary goal of data processing functions. The word “state” that I used in the title literally means this data.
The function will change the data in some way, and will also use the existing data as an implicit input when deciding what to do. That means no more guarantee of being deterministic.
Side effects also lessen the role of the input and output parameters. Far more of the function’s input information comes from the data. Far more of the function’s output comprises changes to the data.
Just one invocation of the function may result in many data records being updated: potentially very large numbers. One single row is just one tiny data point. All data integration considers multiple records, because insight can only come from combining and comparing many records.
Best performance usually comes from bulk mode operations – which is what databases are good at – rather than row by row. Operationally this means there are special considerations for error handling in data processing functions. For example, an operation on one million records might entirely fail as a consequence of just a single unhandled data point.
These things define the difference between DataOps and DevOps. They are the top level considerations for efficiently managing the development lifecycle of data processing functions.
The data function development lifecycle
For a data processing function, the main lifecycle steps are the same as for all software: design, build, test, deploy, and then iterate.
The design of a stateless function is relatively simple. The only things the function body can use are the formal, well-defined input parameters. The specification describes those parameters and defines how to generate the output values.
In contrast, there are many more moving parts in the design of a data processing function. Much involves working out how it should interact with the underlying data (the “state”). The way the function reads and writes data depends heavily on the structures and values in the data. The formal input and output parameters are almost trivial in comparison.
The design of a data processing function is tightly coupled to the schema
At the end of the previous article in this series (on Data Change Management) I mentioned several data-oriented challenges related to data lineage. They were concerned with the way designs change over time. The main “stateful” consideration is this:
Software changes without history: data retains history
When changes accumulate over time, the data usually ends up looking like rock strata. Even though the original software has most likely vanished, the data retains a historical record of the processes that were active at the time it was collected. Some of that historical data may not even be accessible any more using the application that nominally manages it! Alterations to business rules can hide it, and business users might no longer be aware of it.
Nevertheless the historical data is still present, lying in wait to make a surprise appearance when a data processing function attempts to use it. This is another cause of the myth that source data quality is poor.
Designers of data processing functions also need to be aware of the impact they may have on other data processing functions. The “state” is a resource that is shared by all, so design changes are likely to cascade from one function to others.
This is an area where data lineage information is really useful. If there is an aggregate that reads from a star schema, the track forward data lineage will reveal it. When the logic to populate the star schema changes, should we also update the aggregate? Questions like this should be addressed in the design, and not left to the code builder.
Stateless functions can be fully understood in isolation. They can be built and analyzed standalone because there are no parameters other than the formal inputs and outputs. They are typically run many times, each invocation dealing with one single record.
Data processing functions are dissimilar, though. The main thing that a developer needs is the “state” from the underlying database. Typically one invocation reads and writes many records. Data processing functions tend to be heavyweight. Much of the performance tuning, scalability, and maintainability should come from a Low-Code/No-Code platform. Nevertheless, it is always good to try and avoid surprises, so it is best to develop using real data where possible, and certainly with realistic data volumes.
When testing a stateless function, the boundaries of what is possible are clear and finite. First, it is important to test a selection of valid values. The expected outputs for those are entirely predictable because stateless functions are deterministic. To be thorough, tests should also include a variety of edge case parameters such as zero, infinity, NaN, and -1. Some of those may be expected to produce errors. Having included all those cases, the tester can be confident that the stateless function will work under any circumstances.
When it comes to testing a data processing function, there are no such things as expected values based on input parameters. As an example, “run the daily ETL” might only require a single date as an input parameter, and would probably only produce success or failure as an output. It might update millions of records as side effects, or it might quite legitimately update nothing at all. For that reason it is vital to test data rather than software.
Every time a data processing function is executed, some data will hopefully be changed as a side effect. That is the primary goal of data processing functions, after all. So in order to run multiple tests in succession, it is important to be able to easily revert all the data. Returning the data to its prior state is what makes a test quickly repeatable.
To deploy a stateless function it is sufficient to simply overwrite it. Cloud IaaS platforms, such as AWS Lambda, provide a “deploy” button to do exactly that.
To deploy a data processing function, once again things are more complex due to the side effects. There are at least three activities which must be coordinated:
- Packaging the function itself
- Managing any of the tightly coupled schema changes that were the cause of – or a consequence of – this change. This also involves considering what other functions are impacted by the same schema changes
- Considering whether or not to update all of the historical data (plus its dependencies) as per the new logic. If this is a yes, it will require some database updates that must only ever run once, and at exactly the right time
That is not to mention artifacts that are potentially impacted in other areas, including:
- Data science – ML models that might need to be retested or retrained
- Reporting and Analytics – dashboards and extracts that might need to be redeveloped
- Governance – for example, database grants for new and changed objects, design documentation, and lineage information
- DevOps – including third-party libraries that are required by the function
As I mentioned in the previous article, redeployments should be happening often. Stateless functions are virtually invulnerable to schema drift. It is someone else’s problem to find the input parameters and supply them :-). But due to their intricate relationship with state, data functions need to be reworked more frequently. You can go some way to reducing the complexity and workload of deployments by following stateful design patterns.
Stateful design patterns
These are three general purpose, data centric design patterns that you can consider using as guides. For data products, the patterns aim to:
- Optimize development and deployment activities
- Make solutions more resilient against change
- Maximize the value obtained by the business, in a maintainable way
Use Logical Data Layers
Defining and using data tiers is the first step toward a truly data-oriented mindset. Logical data tiers are the top level of object classification in a data integration solution. This is one of the key differences between useful data integration and a data swamp.
Within a tier, you should subdivide again using different kinds of data models to form data layers for different needs. In general, data should enter via one layer, and pass through further layers as it becomes more integrated and more consumable. The following outlines a general purpose tier and layer structure:
- Staging
- Raw/Loading/Landing
- ODS
- Integration
- Third Normal Form (3NF)
- Data Vault
- ML training
- Presentation
- Star schema
- AI/ML model
- Dashboard
- Aggregate
Layer classification can be held as metadata, or it can be implied by enforcing naming and physical location standards.
Managing data by tier enables you to follow best practices for that tier. For example, it is correct to use a truncate-and-reload strategy for a loading table. Whereas that approach would be entirely inappropriate for an ODS or integration layer table.
Understanding tier placement is fundamental for compliance and governance. For example, data layers provide the foundation for permission management and for data lineage.
DataOps differs from DevOps in that the data and the schema are elevated to the status of top-level artifacts. That means they are considered peers to the data processing software that manages them. Having logical tiers with well defined models therefore becomes a great DataOps enabler.
Finally, understanding the placement of data objects within a well defined logical tier structure gives different parts of the business the opportunity to align on core entities.
Align on core entities
In this sense, “core entities” means concepts that are used in many places around the business. This especially applies to entities that are used to correlate across domains, and which are therefore vital for creating joined up insights. A good example of a core entity might be “product,” since that concept will probably be used by multiple departments.
I will use the phrase “data team” quite broadly here, to include the data warehousing, data science, BI, and analytics teams. This makes the core entity alignment pattern simple to express. The aim is that the data team should store the information for a core entity in exactly one place. They should share it widely among themselves and among business users, rather than repeating the derivations in multiple places.
For example, rather than having three separate definitions of “product group” managed by the data warehouse team, the data science platform, and the data visualization team, it is preferable to have one single definition that can be easily shared. That way there is much less chance of the definitions becoming out of step to the detriment of quality.
Inside a data warehouse, this is a good task for Third Normal Form, Data Vault and Bus Matrix structures, as I outlined in an article comparing Data Vault, Star Schema and Third Normal Form. When implemented virtually, and fronted by an API layer, this task is sometimes known as Headless BI. Sharing information widely via a “pull” model API is an example of a declarative approach.
Think declarative
A data-oriented mindset is a declarative mindset. The most important thing is thinking first about how the data should end up. How it gets there is of secondary importance. Of course, the software that shuffles the data around is important! But all of the imperative concerns about when to run what are best managed by the computers themselves.
Virtualization is a good example of declarative thinking. In an article on Data Warehouse Time Variance I contrasted the two approaches in the context of building a slowly changing dimension. With the imperative, physical implementation, there are many jobs and the operator has to run them in the correct order. Whereas with the declarative approach, an entire star schema can be virtualized. There are simply no jobs to run, and therefore no way for things to be run in the wrong order.
Similarly, when sharing information, an imperative approach would be to push data to every target. That involves at least five steps that always have to be performed in the correct order, and repeated for every single target:
- Ensure the correct privileges are in place
- Agree the schema
- Make sure the target is online
- Prepare the correct data for that target
- Perform the push
In contrast, a declarative approach would be to host a well documented API within a governance framework. That way, the targets can decide for themselves when they are ready and can pull the data they need.
Idempotence to data processing functions is conceptually very similar to determinism for stateless functions. It concerns state, and so only applies to data processing functions. The concept is to write the function in such a way that the data will end up the same regardless of the initial state. In this article I described some of the declarative design features that can be found in Low-Code/No-Code platforms.
Once you have an idempotent function, it does not matter how many times you run it or in what order: the resulting data is the same. Idempotent functions also help avoid the need for database transactions, which are an OLTP concept.

Ian Funnell
Data Alchemist
Ian Funnell, Data Alchemist at Matillion, curates The Data Geek weekly newsletter and manages the Matillion Exchange.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: