- Blog
- 01.12.2023
- Dev Dialogues
Data Quality spotlight - Rank and Filter deduplication
The goal of the Matillion data productivity cloud is to make data business ready. In practice this means retaining data quality while increasing consumability.
One of the most common data quality concerns is duplication. It can happen for example when:
- Data is supplied at a different granularity to what is needed
- Reprocessing data after a failure
- There really are duplicated records at source
This article will demonstrate how to use Matillion's low code components to handle duplicates within your own data.
Prerequisites
The prerequisites for Rank and Filter deduplication are:
- Access to Matillion ETL
Duplicate records in SQL
To find duplicates you have to check if there are other records that are the same. That means looking at multiple records.
For example, among the data that appears in the sample screenshot below, the source table has at least three records with account number A-7 (highlighted). 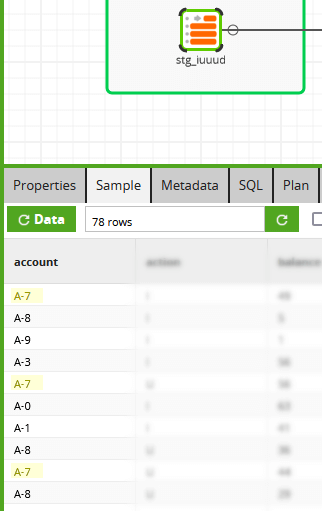 With Matillion's SQL-based ELT approach, it is easy to look at multiple records simultaneously. The RANK function is one of many "analytic" or "window" SQL functions with this ability.
With Matillion's SQL-based ELT approach, it is easy to look at multiple records simultaneously. The RANK function is one of many "analytic" or "window" SQL functions with this ability.
For deduplication, the main thing is to decide what field (or combination of fields) is supposed to be unique. This is known as the partition key of the RANK analytic function.
The RANK analytic function
The RANK function looks at individual records in the context of all the others. It collects the records into sub-groups called partitions, and sorts them into order within each partition.
To use the RANK operation you must supply
- The partition key - the column(s) that define the sub-groups
- The column(s) that sort the records into order within each partition
The RANK function adds a new column containing the ordering. In the screenshot below of Matillion's no-code interface, the new column has been named date_rank: 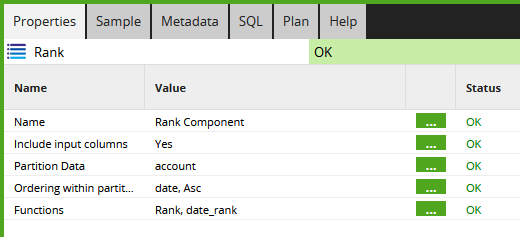 Now the duplication shows up clearly in the data sample. In total there are 7 records with account number A-7.
Now the duplication shows up clearly in the data sample. In total there are 7 records with account number A-7. 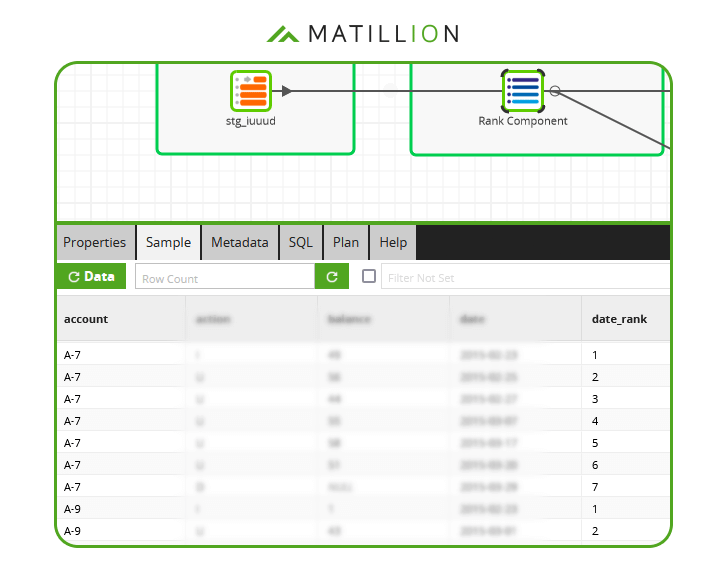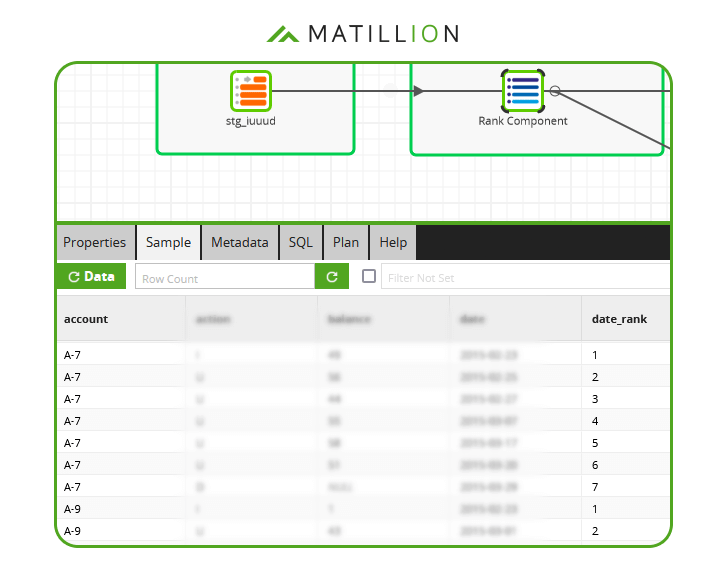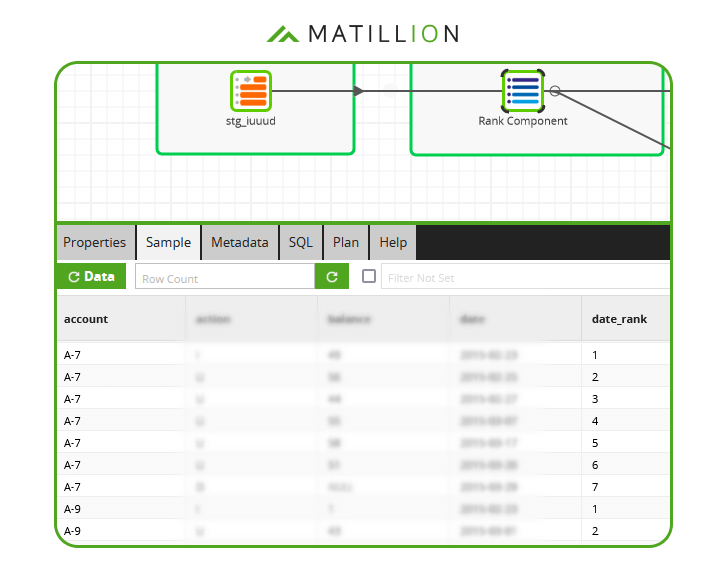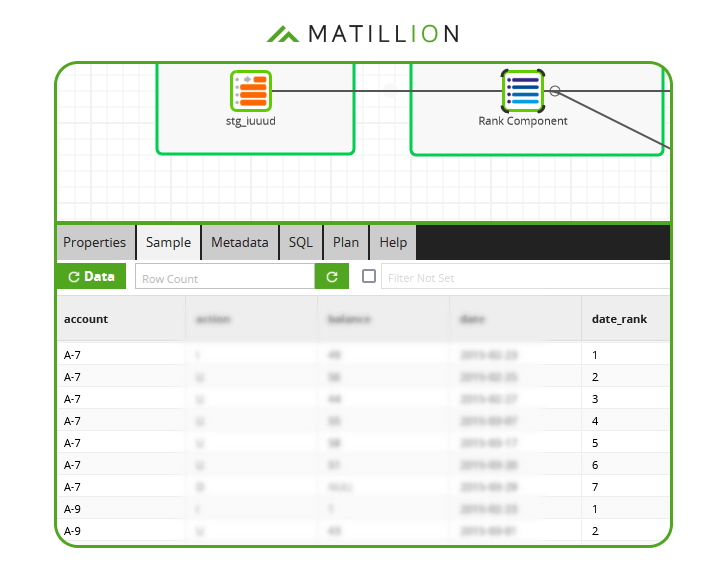 The Rank Component has partitioned the data by account number, and has made sure the new date_rank column is unique within each partition.
The Rank Component has partitioned the data by account number, and has made sure the new date_rank column is unique within each partition.
So to make the data unique by account number, choose one date_rank - conventionally the value 1 - and filter.
Filtering data
Matillion ETL's filter component applies a horizontal filter to the records. In SQL terms it adds a WHERE clause.
The next screenshot shows an implementation in Matillion ETL. It applies a filter that only passes records where the date_rank is 1. 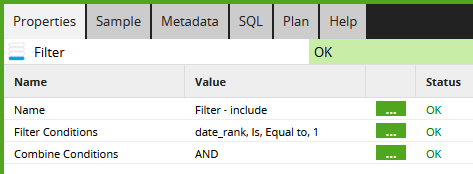 After this filter, the data is guaranteed to be unique by account number.
After this filter, the data is guaranteed to be unique by account number. 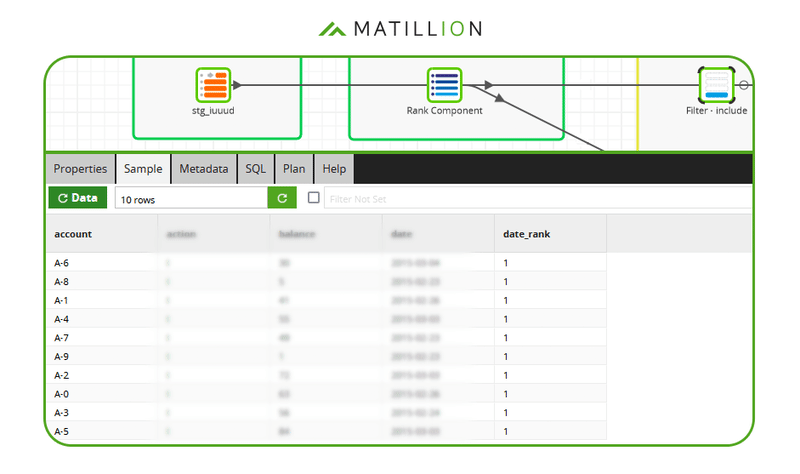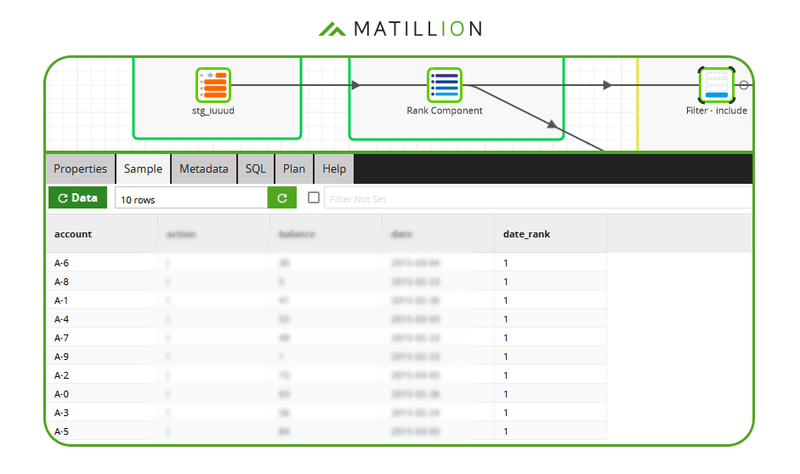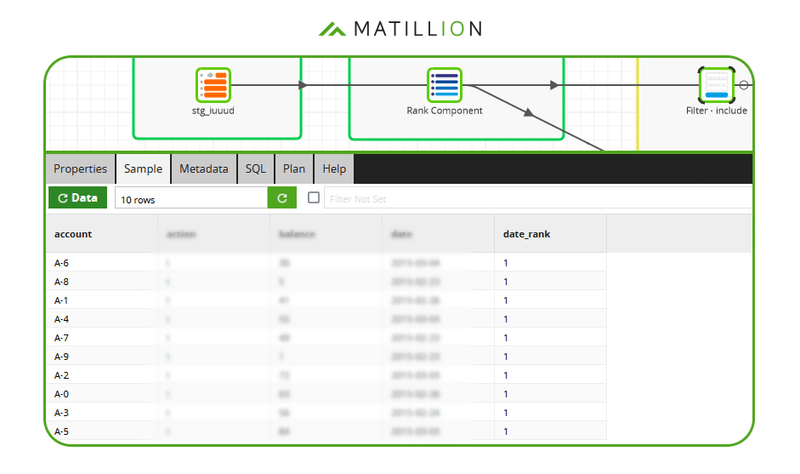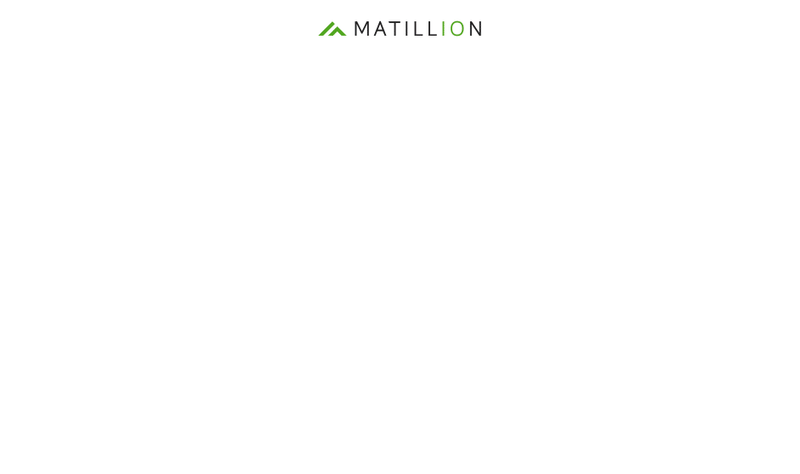 With the duplicates removed, the sample confirms that only 10 records remain in total.
With the duplicates removed, the sample confirms that only 10 records remain in total.
Now that it has been deduplicated, this data could be useful for
- An Account Hub table in a Data Vault model.
- An Account reference table in a 3rd Normal Form model.
- An Account Dimension in a star schema model. The technique demonstrated here is often used to handle late arriving dimensions.
Complementary Filters
So far I have just ignored any duplicate records. But you may choose to do something with them instead. For example
- add them into a suspense table for re-processing later
- send them to error handling and logging
The best way to do this is with a second filter component, exactly opposite to the first. In the screenshot below you can see the filter condition is for date_rank not equal to 1. 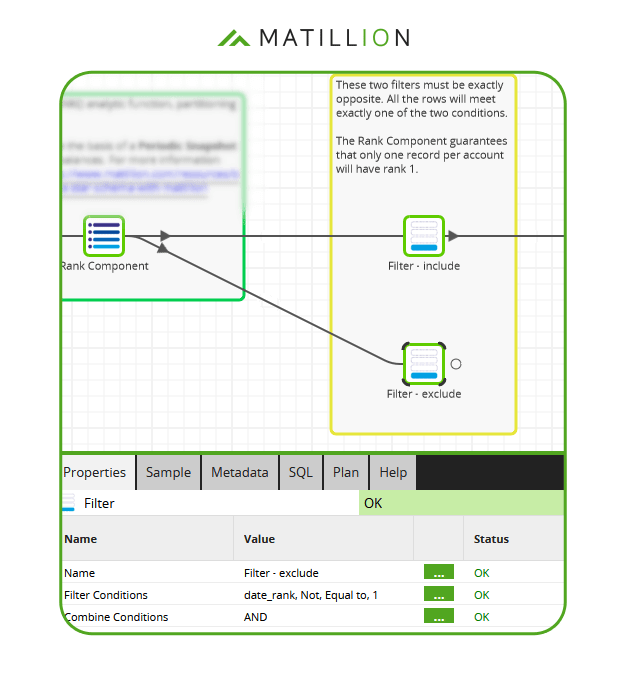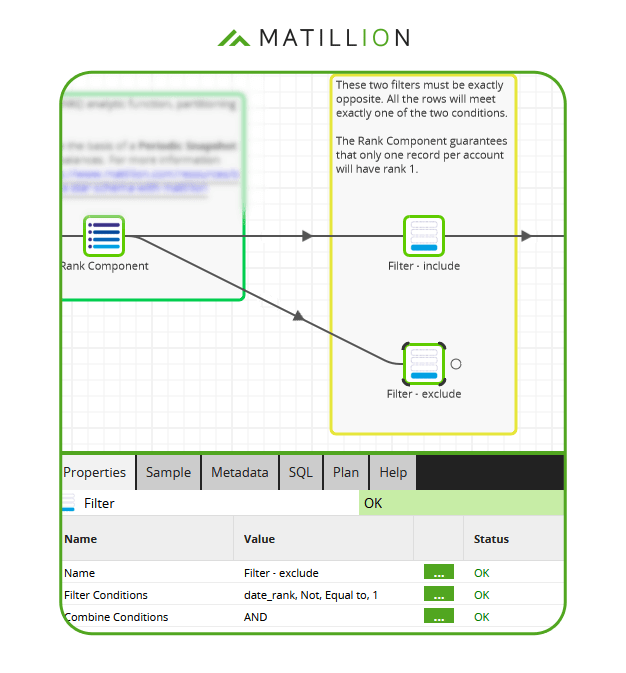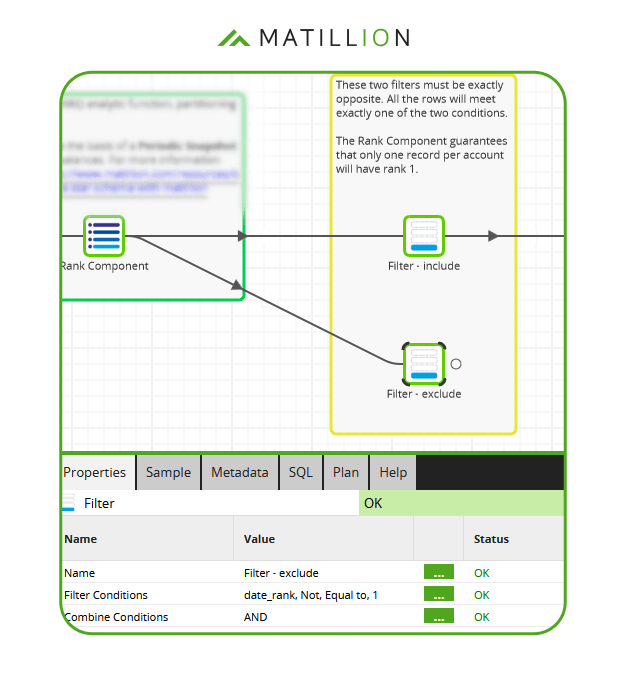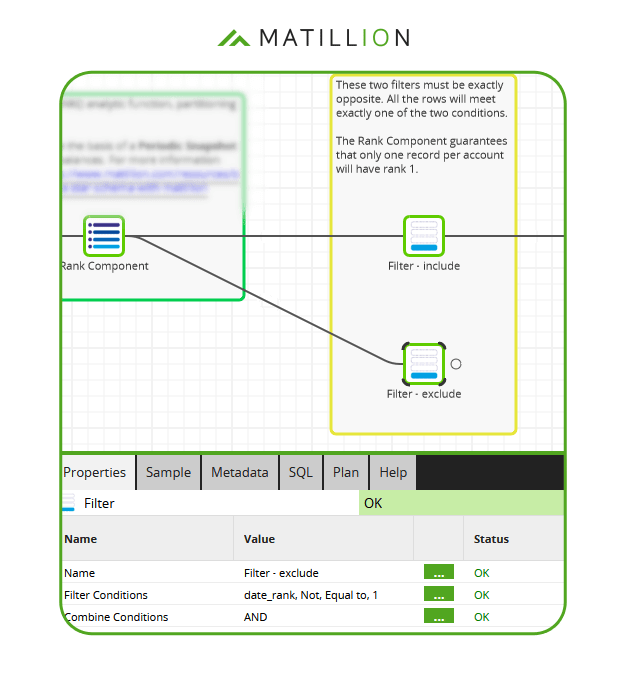 If the two filters are exactly opposite, every incoming record is guaranteed to pass exactly one of the two. This technique is known as complementary filtering.
If the two filters are exactly opposite, every incoming record is guaranteed to pass exactly one of the two. This technique is known as complementary filtering.
Next Steps
Whenever you are developing a workflow with Matillion ETL, always keep in mind the granularity you wish to end up with. Use rank and filter deduplication to adjust the granularity during data transformation.
Where possible it's best to use full data volumes while testing your workflows. Duplicate data may not show up in a small set of hand-created test data. Rank and filter deduplication helps to protect your workflows against duplication appearing in future.
For more information about how Matillion ETL and Snowflake work together in a modern enterprise data stack, download our ebook, Optimizing Snowflake; A Real-World Guide.
To learn our tips for working within AWS and Amazon Redshift environments, download our ebook, Optimizing Amazon Redshift: A Real World Guide.
To understand more about the Databricks lakehouse architecture and the benefits of using Matillion ETL for Delta Lake on Databricks, download our ebook, Guide to the Lakehouse.
Andreu Pintado
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: