- Blog
- 12.22.2021
Multi-Tier Data Architectures with Matillion ETL

Matillion is a cloud native platform for performing data integration using a Cloud Data Warehouse (CDW). It is flexible enough to support any kind of data model and any kind of data architecture. It is possible to dive right in with the Matillion toolset and get productive quickly, designing and building data transformation and integration jobs.
One important best practice is to build upon the best possible foundation. This applies especially to enterprise scale data integrations, which tend to be the most sophisticated. The overall data architecture of a solution provides this foundation, and is a vital part of automation and long term maintainability.
In this article I will talk through all the most widely used architecture variations in a data integration solution. To begin with, it’s important to distinguish between a data architecture and an application architecture.
Data Architecture vs Application Architecture
Much contemporary material on architecture tiers applies to application architectures. There is general advocacy for “three tier” (or “three layer”) patterns which look broadly like this:
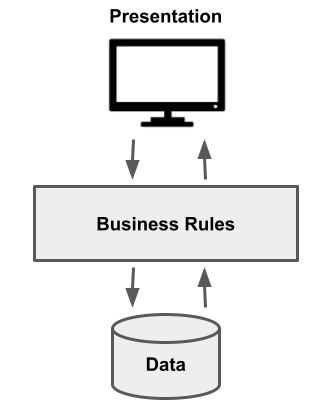
There is some kind of presentation interface, such as a web page or an app, that users connect to. It is ultimately backed by some kind of data storage layer – usually implemented as a structured or semi-structured database.
Importantly, the presentation interface is not simply let loose directly on the data. We have moved on from the two tier client-server applications of the 1990s! Instead there is a middle tier that mediates between the two: governing the access requests and interpreting the data correctly for presentation.
The interpretation logic is in the form of business rules. The contents of the database can look very different to what appears on the screen. It’s the business rules that tell the presentation interface how to interpret the data correctly. For the sake of argument, an example of a business rule could be that order header codes 17, 99 and 101 all mean that the order has been shipped. The database would contain those codes but the interface would display “shipped”.
All of the application architecture details above are for background information. It’s just the first part of an enterprise data integration architecture.
The more general considerations in an enterprise data architecture are listed below.
- How to interpret the source data (the business rules I mentioned above)
- Delivering operational reporting
- Enterprise reporting requirements, such as Customer 360, golden record processing, proactive alerting, fraud detection, Next Best Action, and many more
- Data integration
- Sync back operations, helping to make insights actionable
In the next few sections I will focus on the different enterprise data architecture variations in turn. Each one will describe how the architecture influences the factors in the list above.
Single-tier data architecture – ODS
This is the simplest data architecture for a cloud data warehouse, and is sometimes also known as “Operational Data Stores” (ODS), or “Persistent Staging Area”.
Data is independently replicated from all the source systems into the target CDW, where it becomes colocated inside the CDW. The work is usually done by CDC processes such the one found in Matillion Data Loader 2.0. The CDC processes keep each set of target data in step with its individual source system.
Despite not not being integrated, the ODS areas in the CDW are a good source for independent operational reporting. The most important requirement is that the CDC process keeps them sufficiently up to date.
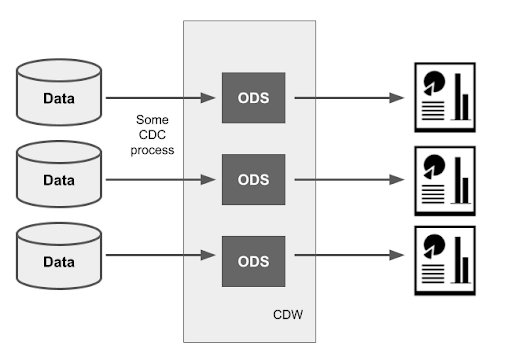
This design is quick to implement and should be highly automated, including the ability to replicate schema drift from source to target.
There is no interpretation of data at all: it is just copied from place to place without applying any business rules. Any transformations or filters that are needed must be done in the reporting layer. Consequently the reports can become complex, because they have to be aware of all the quirks and workarounds in the different source systems.
The main benefits of this architecture are
- Quick to deliver operational reporting, especially to reduce the load on the live systems. The reports can simply be exact copies of the originals that were running against the source systems.
- It is a good way to build and keep a data audit trail
- The CDC process can be a physical one that really copies data. Alternatively, this architecture can be implemented using virtualization or federation
- An opportunity to quickly lift-and-shift reporting to a cloud data warehouse
However, integrated enterprise reporting requirements cannot be met well with this architecture. There is colocation but no real data integration. All of the data in every ODS remains logically siloed by its system of origin.
Wherever multiple reports exist that use the same source data, every single one must repeat all of the same filters, conditions, corrections and workarounds that are needed.
If you find many reports that have included client-side blending or mashups, it is usually a sign of unmet data integration needs. This data integration can most scalably and sustainably be provided by implementing one of the more sophisticated multiple-tier data architectures.
Two-tier data architecture: Data marts
This architecture starts out the same as the single tier, with ODS areas being maintained by CDC processes.
In a two-tier architecture, there is an additional layer of transformation, which brings the data into a number of star schema data models.
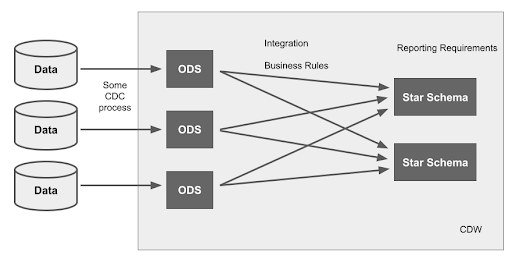
Star Schemas are designed to meet specific reporting requirements, and represent gold standard consumability in that respect. Most reports are built from the star schemas. For this reason, the star schemas are known as the presentation layer in the data architecture. This is the main cause of the misconception that a star schema is a data warehouse.
The transformations that take data from the ODS layer into the star schema perform a dual function:
- They integrate the data by applying all the necessary business rules to interpret the different source system data correctly
- They fit the data into the target dimensional structures, which are optimal for specific reporting needs
In a two-tier architecture, it is still possible to run operational reporting directly from the ODS layer. So this architecture does deliver both operational reporting and data integration (and consequently, enterprise reporting too).
If you only have a small number of star schemas, and the source systems don’t change much, then this architecture is a good choice.
The main disadvantage of this approach is that transformations such as filters on source data must be repeated for every single star schema. You end up having to carefully apply the same rule in multiple places. The consequences of this are:
- This architecture becomes expensive to refactor whenever the business rules need to be updated – for example, whenever changes occur in the source systems.
- Larger implementations end up with a confusing maze of data flows, in which many tables in many ODS’s feed data into many dimensional objects.
- Data models built this way can be difficult to alter and repopulate once the data has been loaded, especially if historical data is not retained at source.
It is natural to base a first presentation layer design on specific reporting requirements. But it can soon become limiting. The maintenance tends to follow a regrettably common path toward problems. Here is a worked example to explain how it happens:
| Business user | Data warehouse team |
|---|---|
| (User 1) I need a report on shipped Orders at Header level please | |
| OK, done. I discovered and implemented the business rule that codes 17, 99 and 101 mean "shipped" orders. The Order Header fact table is all yours! | |
| (User 2) Love that report on shipped Order Headers! Can I please have the same but for all the Line Items in every Order | |
| No problem at all. I heard that the rule is only to use codes 17, 99 and 101 for shipped orders. I have copied that logic and implemented a new Order Line fact table | |
| (User 1 again) We have a new depot and they use code 107 to mean "shipped". My Order Header report is not showing any of their data. Please can you fix it? | |
| Sure thing. I have fixed the shipped Order Header table so it includes code 107. I tested it and data from the new depot is coming through now! | |
| (User 3) Why are the totals in the Order Line report completely different from the totals in the Order Header report? I don't trust this system. |
Now there is a lack of trust in the figures, and the business can’t make quick, confident decisions based on the data.
What went wrong? The data warehouse developer did their job and updated the logic for the Order Header fact table. But they did not know (or forgot, or it was out of scope) that the exact same rule should have been applied to the Order Line fact table too.
The root cause is that a two tier data architecture does not fully provide one of the core aspects of data integration: subject orientation.
With subject orientation, all of the data on one subject is held in just one place, and in a consistent format. There is no need for individual star schema data feeds to have to deal with codes 17, 99, 101, 107 and whatever else. All the input data is conformed to a unified model with consistent, well defined semantics. There is much less scope for star schemas to become out of step with each other. This is essentially the “enterprise data warehouse” part of a three-tier data architecture.
Three-tier data architecture – The enterprise data warehouse
This architecture also starts out the same as the single tier, with ODS areas being maintained by CDC. It also ends up with star schemas that look exactly the same to end users as they would in a two-tier architecture.
The critical difference with a three-tier data architecture is the extra layer in the middle. This is the unified data model with consistent, well defined semantics that I mentioned at the end of the previous section.
The middle layer is the enterprise data warehouse. It can be implemented using Data Vault or 3rd Normal Form, and is sometimes referred to as the “normalized” layer for that reason.
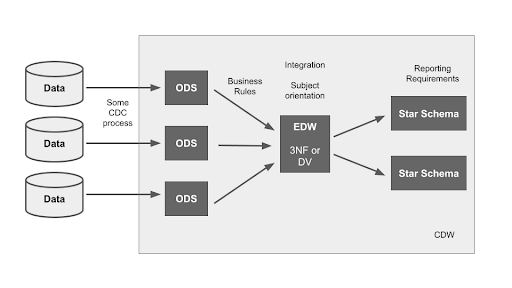
Two data transformation stages are required in a three-tier data architecture:
- From the ODS layer, applying all the necessary business rules to interpret the different source system data correctly, and converting it into a subject-oriented, integrated EDW model that is not tied to any one particular source system.
- From the EDW into star schemas, to fulfill whatever reporting requirements come along. The star schemas are rather throwaway in this architecture. They can easily be dropped and recreated. Alternatively they can often be entirely virtualized.
In this approach, the data structures in the middle tier are the single source of truth. Data can be read from there with consistent semantics into any number of star schemas.
Not everything that appears in the middle tier needs to immediately go into a Star Schema. This is another way that the reporting requirements and the long term storage become more loosely coupled.
To continue the example I used in the previous section, with a three-tier architecture, you could build as follows:
- In the data feed from the first two ODS’s, among the transformations would be these business rules:
- Codes 17, 99, and 101 mean “shipped” orders, so transform that cryptic code into a simple “shipped” flag.
- Bring in all orders, even though the only report requested so far is just for shipped orders.
- In the data feed from the last ODS (the new depot), among the transformations would be these business rules:
- Code 107 means “shipped” orders on this system, so transform it into the same “shipped” flag appropriately.
- Once again, bring in all orders, confident in the knowledge that it’s easy for everyone to consistently distinguish shipped orders
- In the data feed from the EDW to the two star schemas, filter using the new, simple yes-or-no “shipped” flag. No knowledge is needed about whatever esoteric codes the source systems happen to use: all orders are simply either shipped or not.
- The data is coming from just one place: a unified “orders” table. Changes applied here will automatically cascade into all affected star schemas
- The data model is normalized, meaning that there is no duplication. The status of an order is automatically cascaded onto the order lines.
In this way, the three-tier architecture results in the best of both worlds: the simplicity of star schemas plus the resilience of a normalized data model. This architecture is suitable
for every data integration task, from the simplest right through to the most complex.
Circular data architectures
In all of the data architectures reviewed so far, the data has remained inside the CDW after processing. This is generally a good thing, because then any suitably privileged reporting, dashboarding, or data extraction utility can connect to the CDW itself and create a report, a visualization, a dashboard, or an extract in a consistent way. Furthermore, all of them automatically take advantage of the CDW’s built-in cloud scalability while that is happening.
But joined-up intelligence and insights are also potentially valuable elsewhere, too. For example:
- Derived customer information, such as golden records and Next Best Action, are most actionable when presented back to an operational source system.
- Possible fraud needs to generate an alert in an operational system right now
This feedback of data to source is known as a sync back. When in place, data architectures become circular:
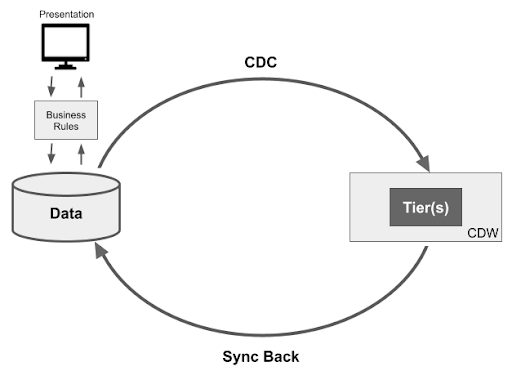
Circular data architectures avoid the irony of the cloud data warehouse itself becoming a dead end for data – just one more silo.
The sync back mechanism can either be a “push” model, in which the CDW proactively pushes data, or a “pull” model in which the CDW makes data available through standardized, governed interfaces. Examples include REST APIs and virtualization, and may include automated notification mechanisms.
Learn more about multi-tier architectures with Matillion ETL: Get a demo
To learn more about how multi-tier architectures with our Matillion ETL tool can help your business handle data and reporting in a more sophisticated way, get a demo.
Featured Resources
How to Choose Your GenAI Prompting Strategy: Zero Shot vs. Few Shot Prompts
Large language models (LLMs) produce output in response to a natural language input known as a prompt. The prompt contains ...
BlogEnabling DataOps With Data Productivity Language
Discover how Matillion leverages Git and the Data Productivity Language (DPL) to enable seamless implementation of DataOps ...
BlogCustom Connector for Public Statistics (Police API)
A demonstration of the practical steps for setting up components, manipulating and validating data, creating and scheduling ...
Share: