- Blog
- 06.02.2022
Creating a Modern Data Platform with Azure Synapse Analytics and Matillion ETL
We’re excited to present today’s guest blogger, Dmitry Anoshin, a data and analytics expert and thought leader and creator of the blog Rock Your Data. Today Dmitry will share his insight on working with Matillion ETL and Azure Synapse Analytics.
In today’s world, unlocking profound insights and driving business transformation with data’s full, unleashed potential requires a modernized data infrastructure. The speed of decision making is critical. Business leaders don’t have the luxury of thinking over a decision for a few weeks.
Speed matters. Without a modern data stack in place, with data where and when you need it, you simply can’t act fast enough. One of the key building blocks of modern analytics is a data platform that harnesses data’s power to reveal patterns, make predictions and deliver insights. Being able to understand and tap into these insights helps make the right decision and act on them.
A Modern Data Platform on Azure
Many companies today are looking to migrate their existing data warehouse to Azure Synapse Analytics to reap the benefits that a modern, globally available, secure, scalable, pay-as-you-go database management system offers. In addition, they also want to exploit the rich analytical ecosystem that integrates with Azure Synapse to make use of machine learning, integrate with streaming data, offload staging areas to Azure Data Lake, and exploit scalable, massively parallel, in-memory analytics with Azure Databricks.
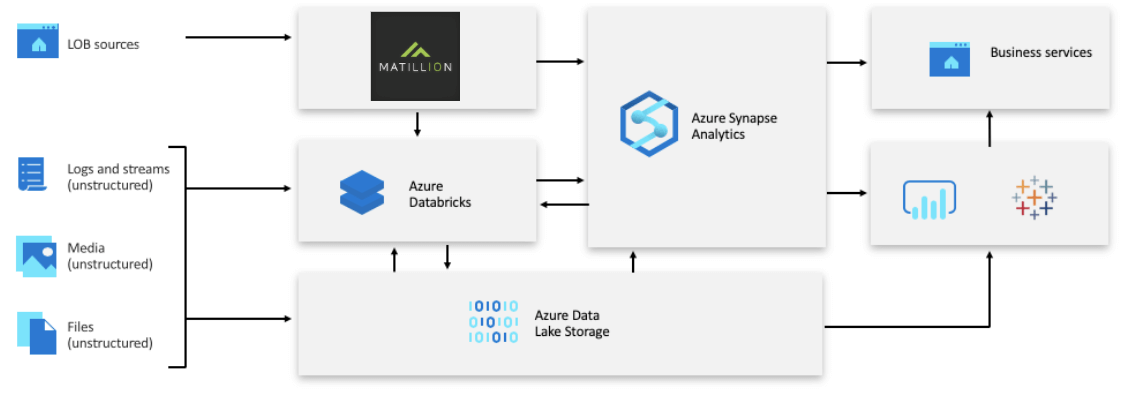
In this post, we would like to talk about Matillion ETL for Azure Synapse and how it can help you integrate and transform your data leveraging the power of Azure Synapse Analytics.
A Look at Matillion ETL for Azure Synapse
Matillion ETL is an ELT tool. ELT stands for Extract, Load and Transform. In other words, with Matillion we can extract data from source systems, load into the target data warehouse and then transform. For data transformation we are using SQL, because it is happening inside of Azure Synapse.
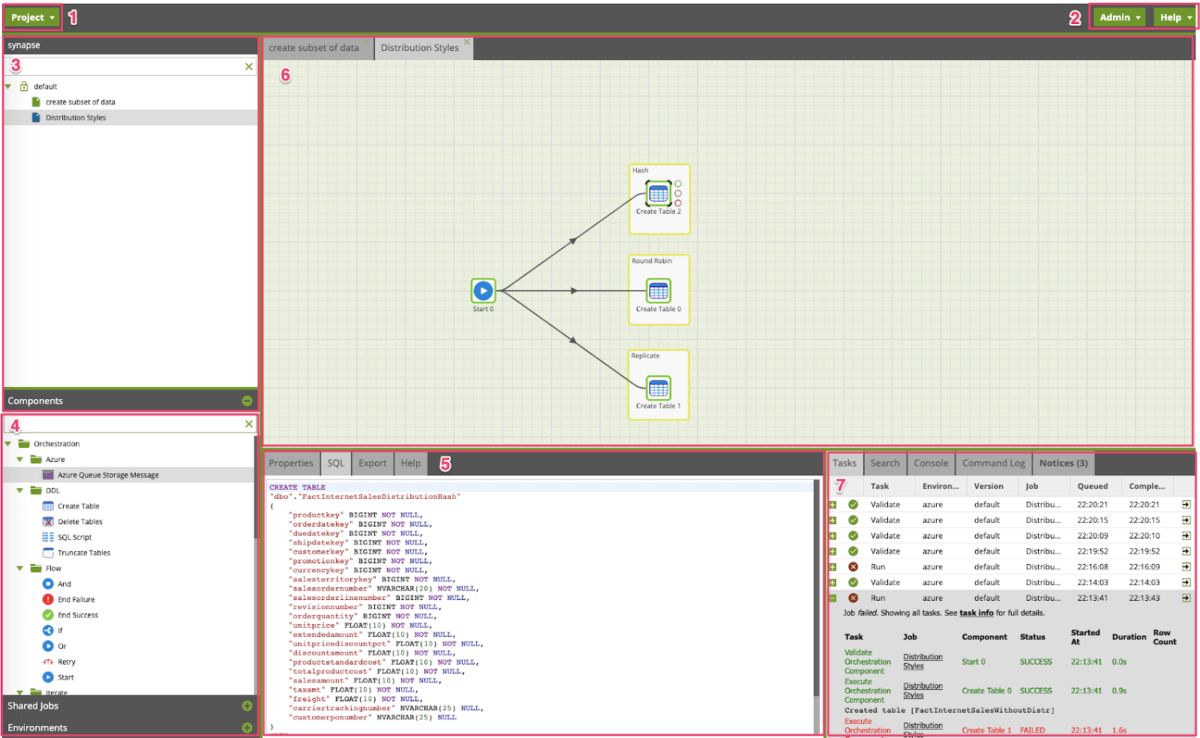
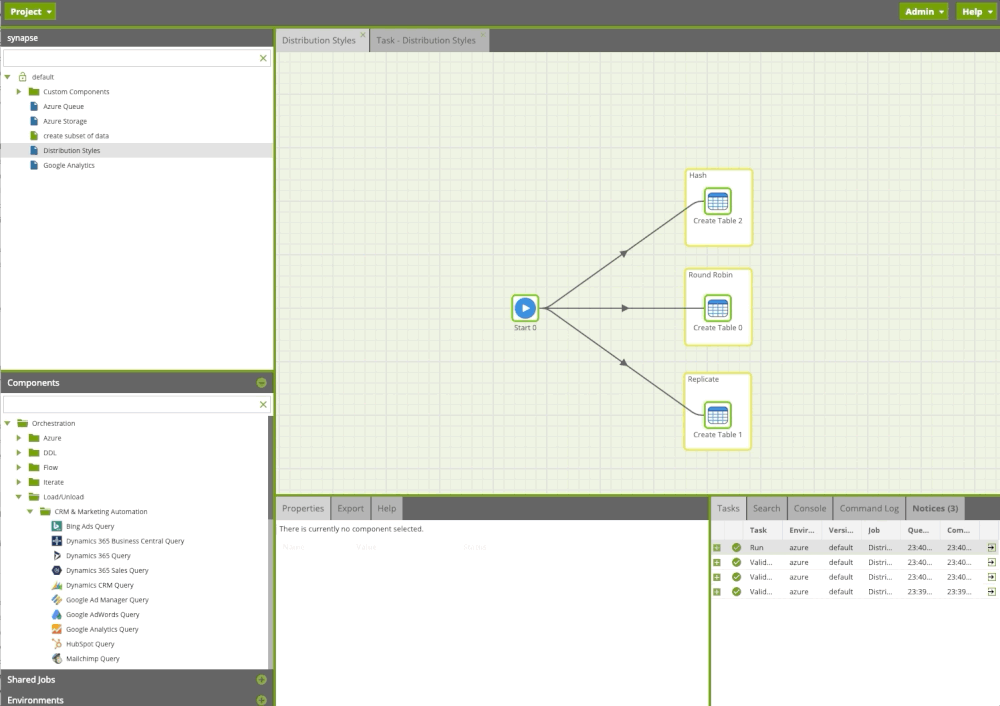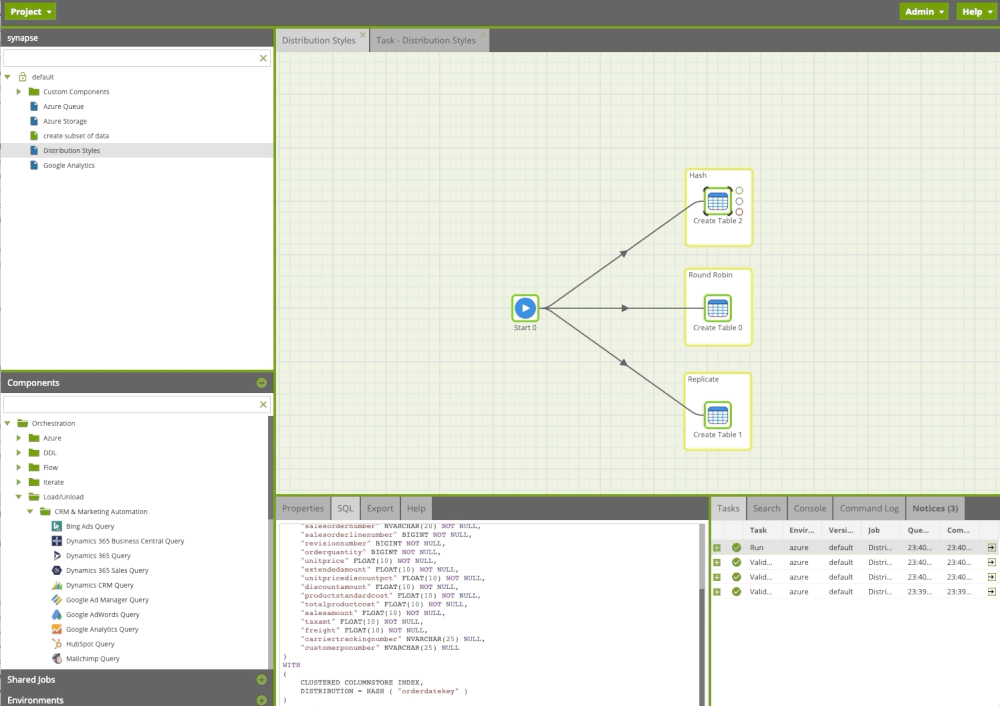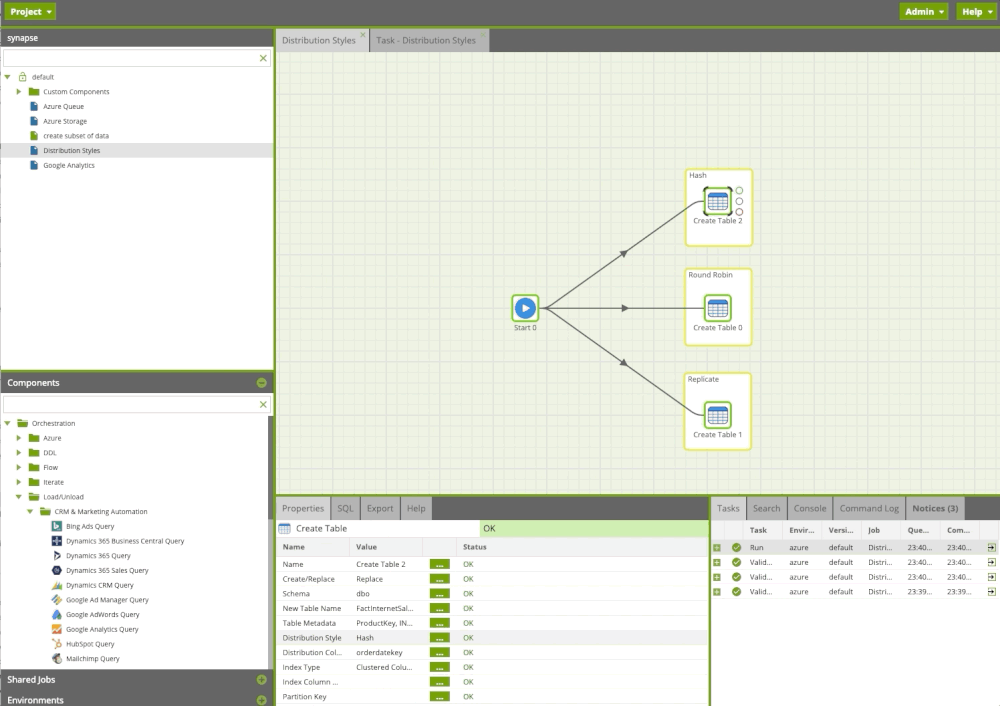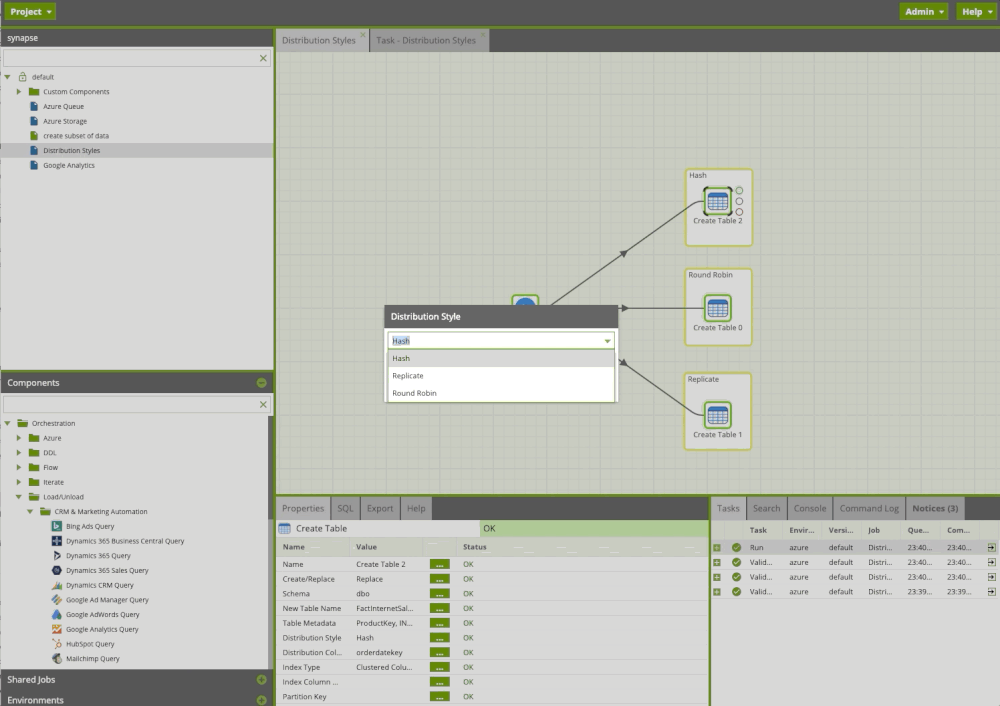
In the screenshot above, we highlighted the key areas within the Matillion ETL for Azure Synapse interface:
- Project Menu — this is the main menu for our project. We can control schedule, variables, permissions and project properties.
- Admin Options – Here, we can add new users, restart Matillion the Virtual Machine, Audit, LDAP and so on. With Help we can check who is online or get the version number. (don’t really need this for daily usage).
- Navigational Menu — This is where we have folders with our jobs. We can create a new job or folder.
- Components Menu — A list of components that we can drag and drop to the Canvas (6). Also, it has the Environments Menu, where we define the connection to our Synapse instance or Azure account. This is the place where we can check “Do we connect to Production or Development Synapse?”
- Components Tab — Here, you can find the list of things you can do with a particular component. By default, you should fill the properties tab with your table name, schema or credentials. With Sample, you can always get a sample of your data or rows count. Metadata will tell you about column names and their types. Finally, you can click on Help and get detailed information about the component.
- Canvas — This is where the magic happens. Here, we are build our data pipelines.
- Task — We mostly use the first tab, where we can see the status of running jobs.
Also, you may notice two type of jobs:

- Orchestration Job (blue) — This type of job orchestrates the pipeline, i.e. we can build dependencies, what’s run first, what to do if the job fails, and so on. For example, if we want to bring data into Azure Synapse Analytics, we will use an Orchestration Job.
- Transformation Job (green) — This type of job is responsible for the data transformations that are happening inside Synapse Analytics. In other words, everything what we can do with Synapse Analytics Data Warehouse, we can do here with visual components (SELECT, GROUP BY, JOIN, UNION and so on)
A Look at Azure Synapse
Before we go deep within Matillion ETL, let’s take a closer look at Azure Synapse Analytics. Before Azure Synapse, we had Azure SQL Data Warehouse, which existed inside the Azure Data Platform. Azure Synapse Analytics is a new, modern cloud data warehouse product for Microsoft customers. But Azure Synapse is more than just a data warehouse. With it, Microsoft did a great job of unifying the Azure Data Platform offering, bringing Azure Synapse together with other technologies such as SQL Data Warehouse, Databricks (Spark), Azure ML Service and more.
It is important to make the distinction that we are talking about Azure Synapse, the Multiply Parallel Processing data warehouse (formerly Azure SQL Data Warehouse), in this post.
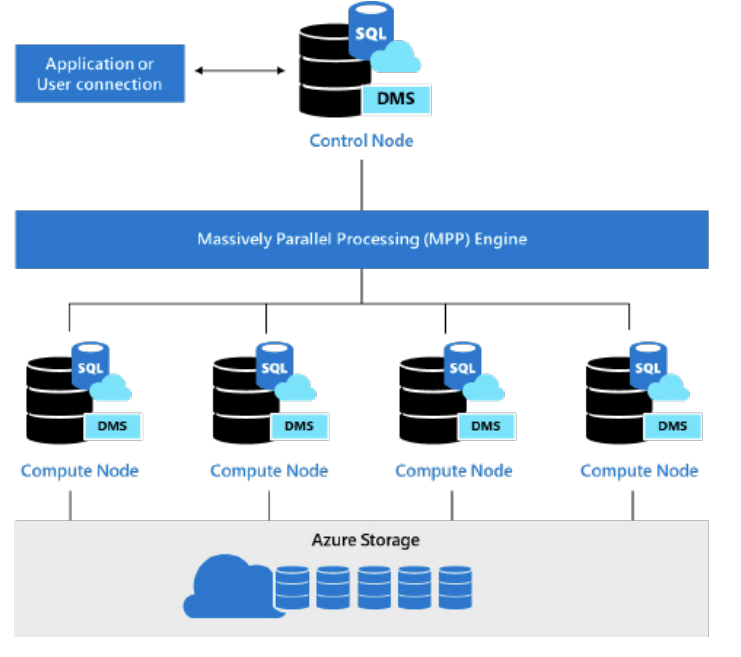
Azure Synapse is a massively parallel processing (MPP) data warehouse that achieves performance and scalability by running in parallel across multiple processing nodes. Let’s look at the key distinctions of the Azure Synapse platform and some examples of how to use Matillion ETL for data warehouse orchestration.
Matillion ETL + Synapse Analytics = Modern Analytics
Let’s get started.

A few assumptions
For this discussion, we will assume that you are familiar with the traditional Microsoft data analytics stack, including SQL Server, Integrations Service, Analysis Service, and Reporting Service. Moreover, we will assume that you have experience with Power BI, and you have migrated some of your legacy reporting from Reporting Service to Power BI. Finally, we’ll assume that you’ve heard about Microsoft Azure and even used or continue to use the Azure Data Platform that includes Azure Synapse Analytics, DataBricks, Data Lake, Azure Data Factory, and other products.
Why use Matillion ETL with Azure Synapse Analytics?
There are three major use cases for moving to Microsoft Azure Synapse:
- Modernizing or migrating your data warehouse from on-premises solution (such as Oracle, Teradata, or Netezza) to the cloud platform.
- Building a modern data warehouse or data platform in the cloud from scratch.
- Evolving your SQL Server Data Warehouse solution.
In any of these three scenarios, you will need to do two things for sure:
- Move data around
- Apply business logic
That’s why you need the right ETL tool. Traditionally, engineers will go with Azure Data Factory. It is the default choice for Azure Data Platform. However, Azure Data Factory requires data engineering knowledge and has limited pre-built components. On the other hand, Matillion ETL is a cloud-native tool that was built specifically for Azure Data Platform to help democratize the data integration process, make it transparent, and allow teams to move faster.
A Synapse Platform Use Case
For example, we would like to build a data pipeline that will load data into the Synapse Platform. We have the following data sources:
- Microsoft Dynamics 365
- Azure Data Lake
- Google Adwords
- Google Analytics
With a traditional approach, this pipeline process can take a while. But Matillion enables you to load data into staging areas almost instantly. This is how it could look in Matillion ETL:
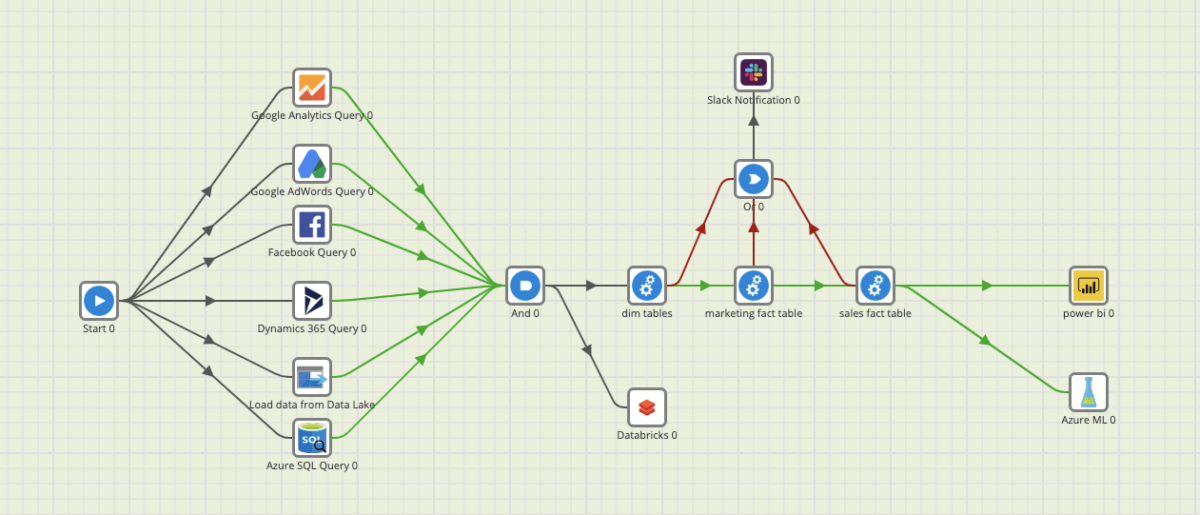
Our data pipeline Orchestration Job in Matillion ETL
First, we load staging areas. Then, we can refresh the dimension model with fact tables and dimension tables.
Finally, we can trigger other Azure Services such as Power BI, Databricks, and Azure ML.
Matillion ETL and Azure Synapse working together
Let’s look at some cool features from Matillion ETL that take advantage of the Azure and Synapse architecture.
Distribution Methods
When we design data warehouses, our goal is to minimize data movement (when a query can’t be solved without moving data among compute nodes before a join or aggregation) and minimize data skew (distributions with disproportionately more data than others).
Let’s review the key distribution methods and create them with Matillion ETL.
Hash distribution
A hash is a function where we feed in a number and then it produces an output called a hash value.
In a hash distributed table:
- Data divides across nodes based on a hashing algorithm
- The same value will always hash to the same distribution
- There is a single distribution column
- You need to be aware of data skew and NULLs
- Rows with the same hash will go to the same bucket. We want to minimize data movement
Hash distributed data
Round-robin distribution
A round-robin distributed table distributes data evenly across the table but without any further optimization.
In a round-robin distribution:
- Data is distributed evenly across nodes (moving data at query time is expensive)
- It’s an easy place to start, because you don’t need to know anything about the data
- You get simplicity, but at a cost
- You will incur more data movement at query time
Replicated tables
Replicated tables are a tool for avoiding data movement. Most optimized queries in the MPP system can simply be passed through to execute on individual distributed databases with no interactions in the other databases.
Replicated tables:
- Make a full copy of table accessible on each compute node
- Are useful for small tables
- Reduce data movement between Compute nodes before join or aggregation
- Simplify query plans
Using Matillion ETL for Azure Synapse we can easily create/recreate tables and apply distribution methods. Moreover, we can attach notes that will help colleagues to understand what is happening.
Managing Statistics
The more Azure Synapse knows about your data, the faster it can execute queries against it. It is crucial for an MPP platform like Azure Synapse to collect statistics after loading data. We can easily leverage Matillion ETL and refresh the statistics after a load job. Up to date statistics will help us to create accurate query plan using cost optimizer and execute queries fast.
One of the first questions to ask when you’re troubleshooting a query is, “Are the statistics up to date?”
Managing Partitions
Matillion ETL can also help you manage table partitions in Azure Synapse. Partitions are a common technique that enables you to divide your data into smaller groups of data. In most cases, table partitions are created on a date column.
The main goal of partitions is to improve query performance. However, keep in mind that creating a table with too many partitions can hurt performance
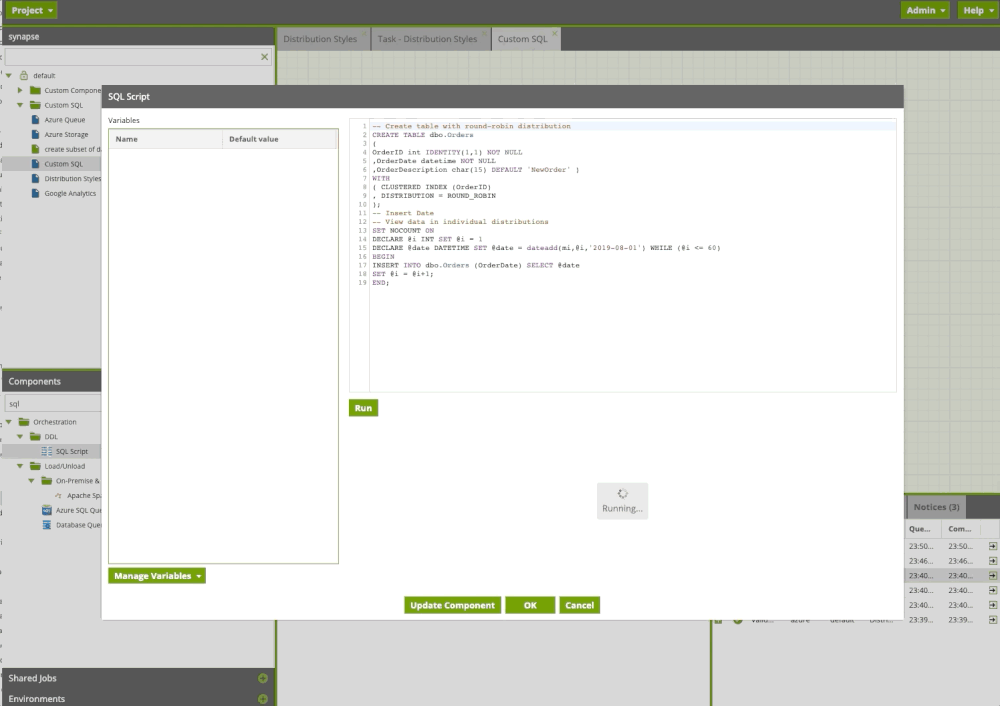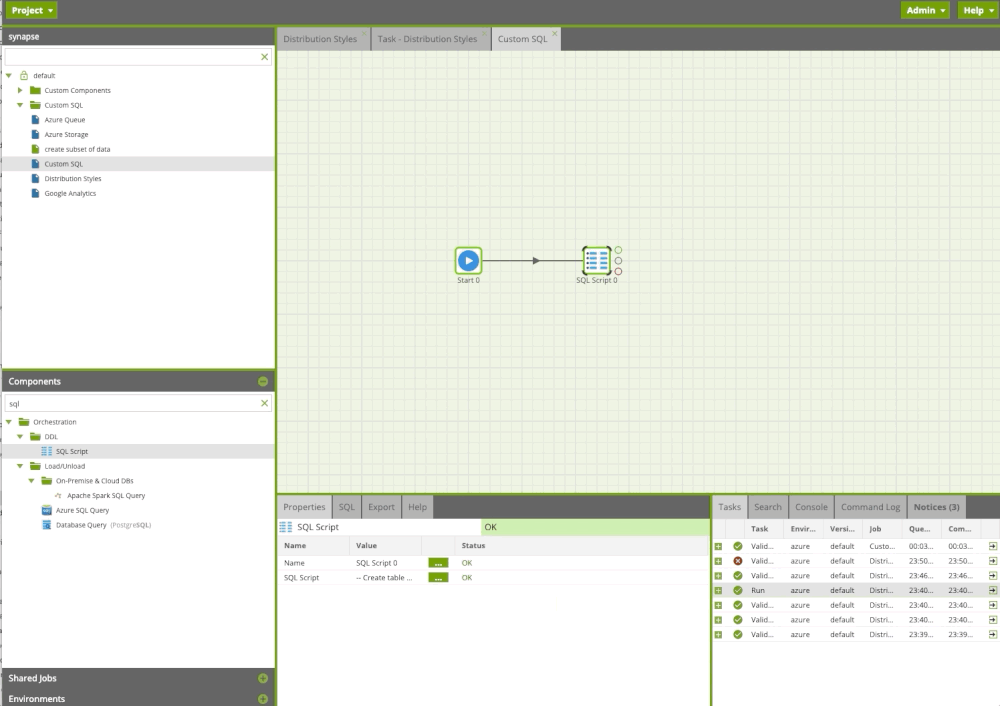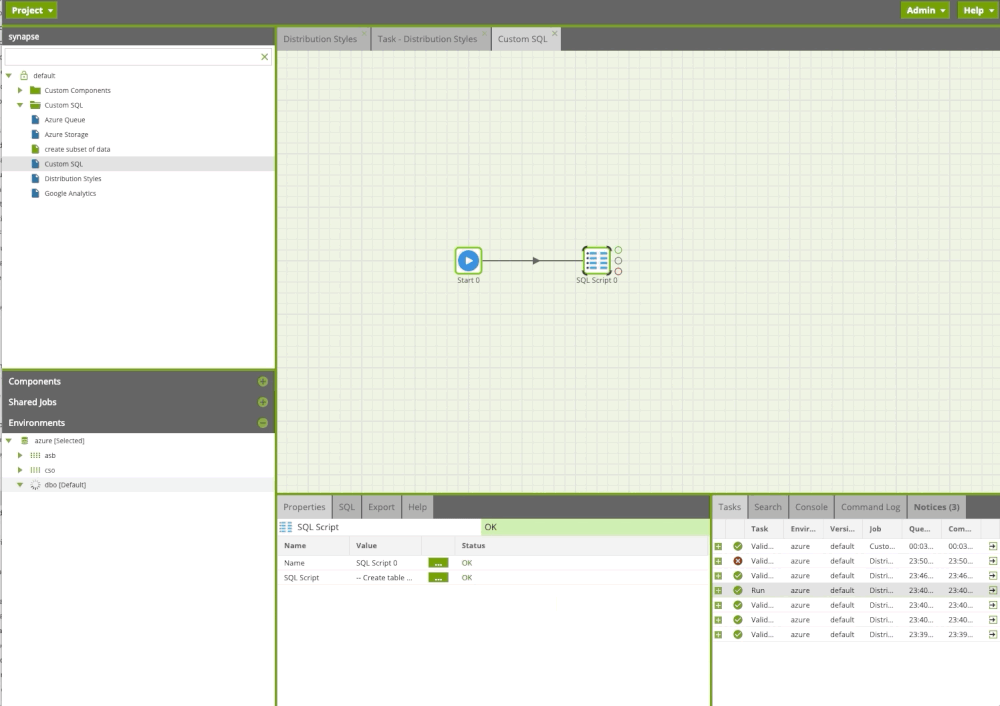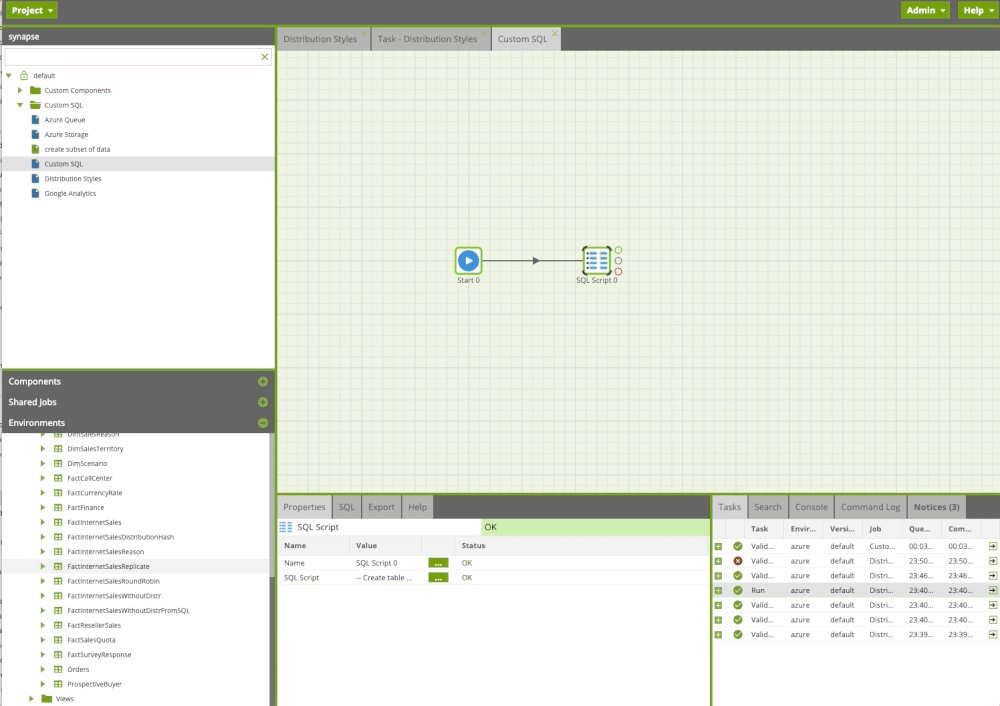
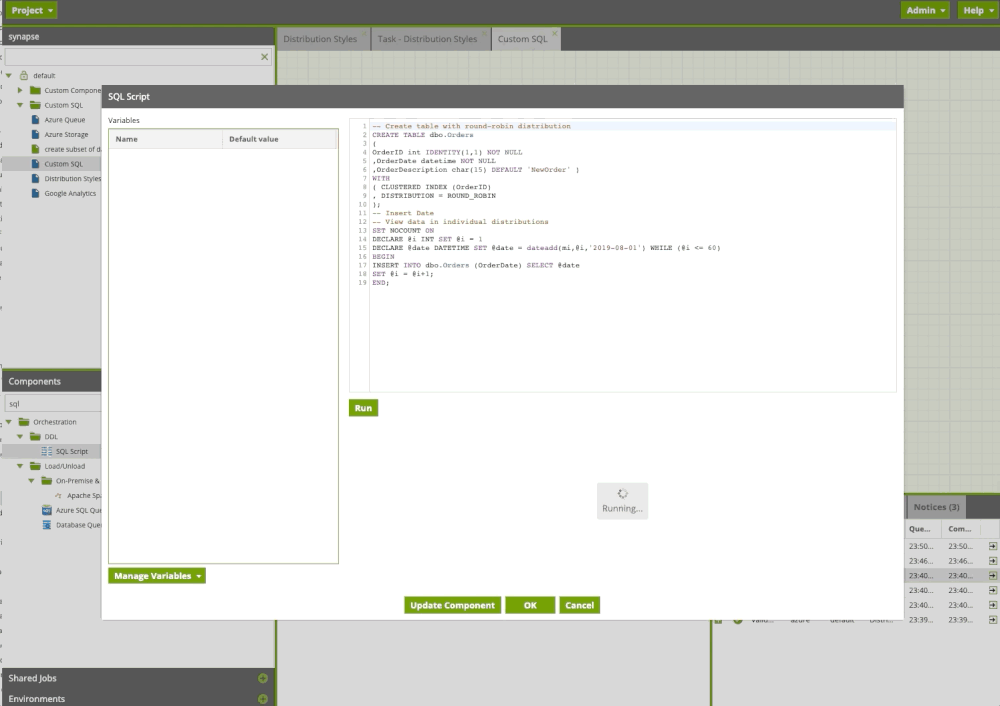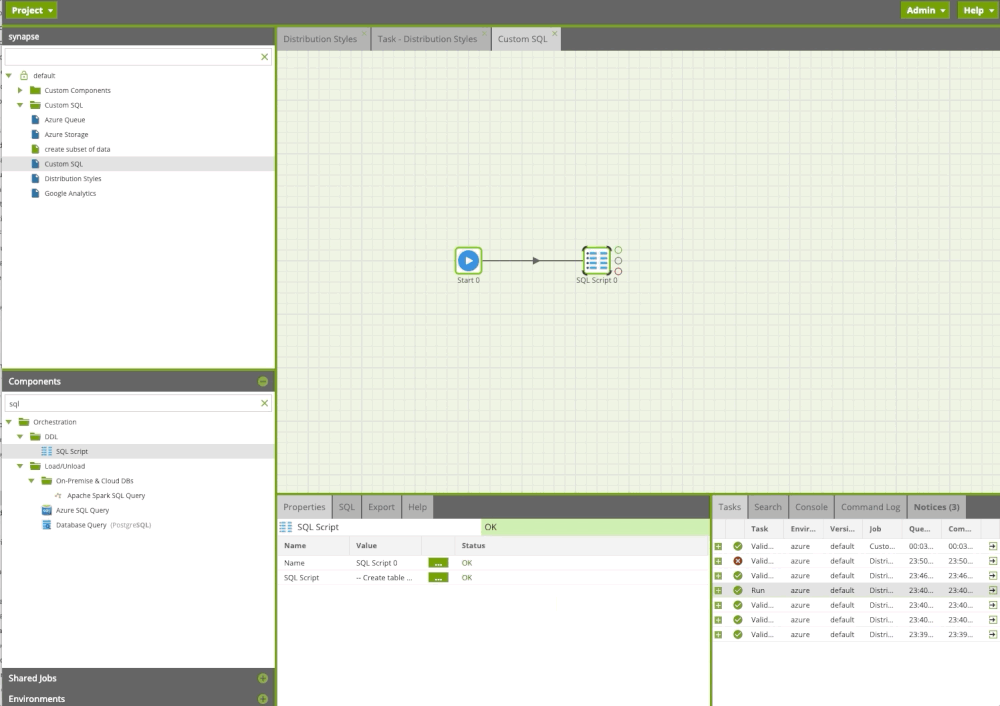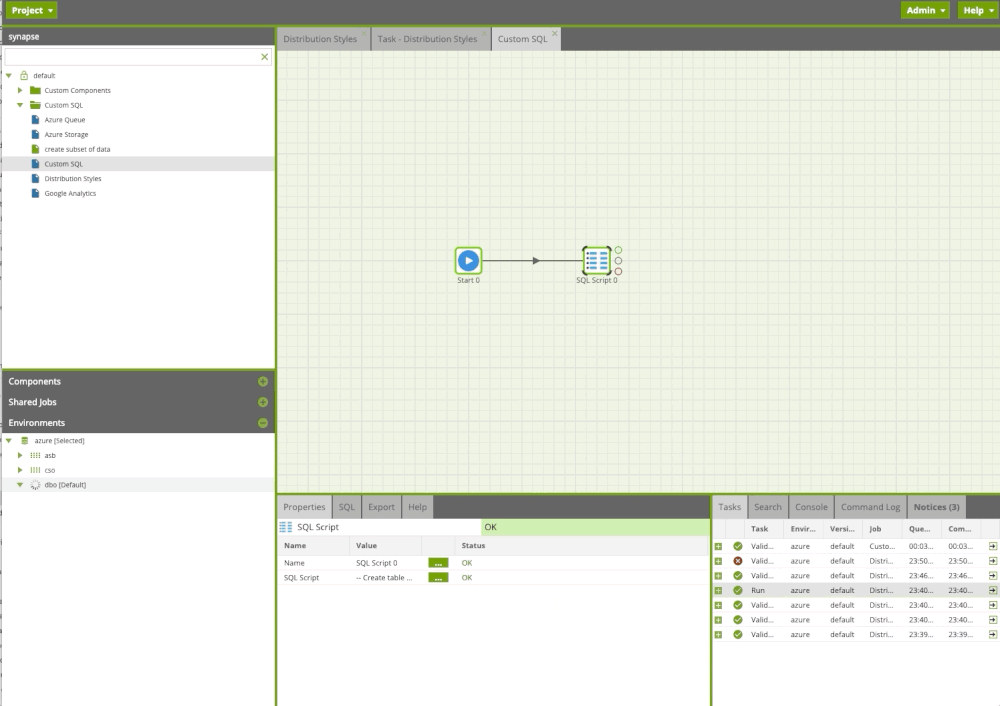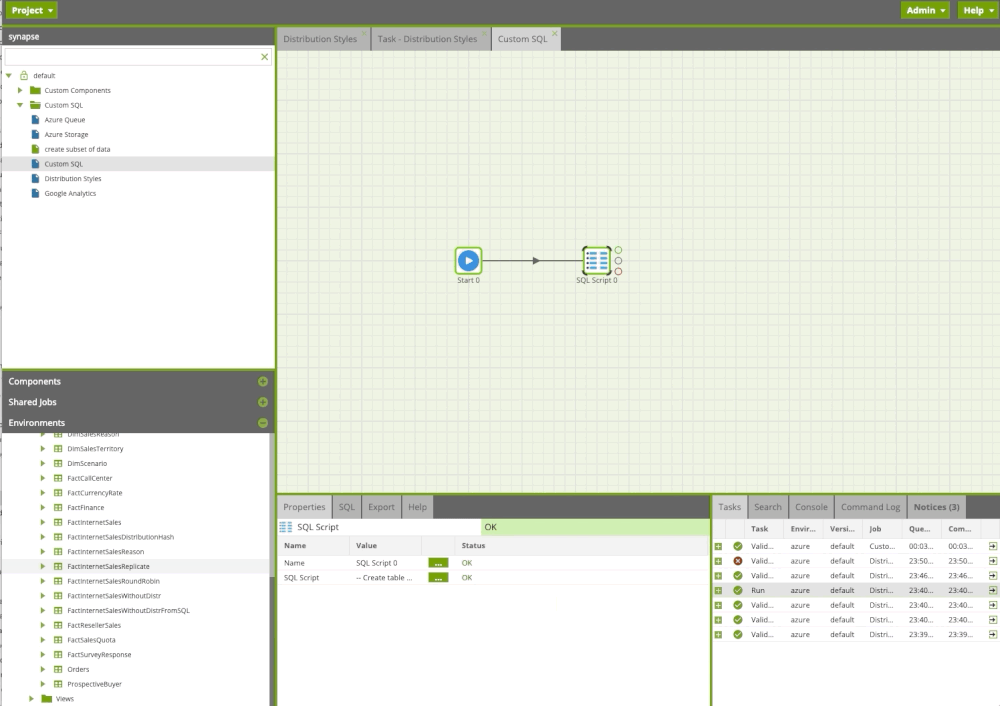
Creating custom SQL
Often users need to execute custom or existing SQL or run a procedure. With the SQL Query component in Matillion ETL, we can do this easily. In the example below, we run custom sql scripts including procedure.
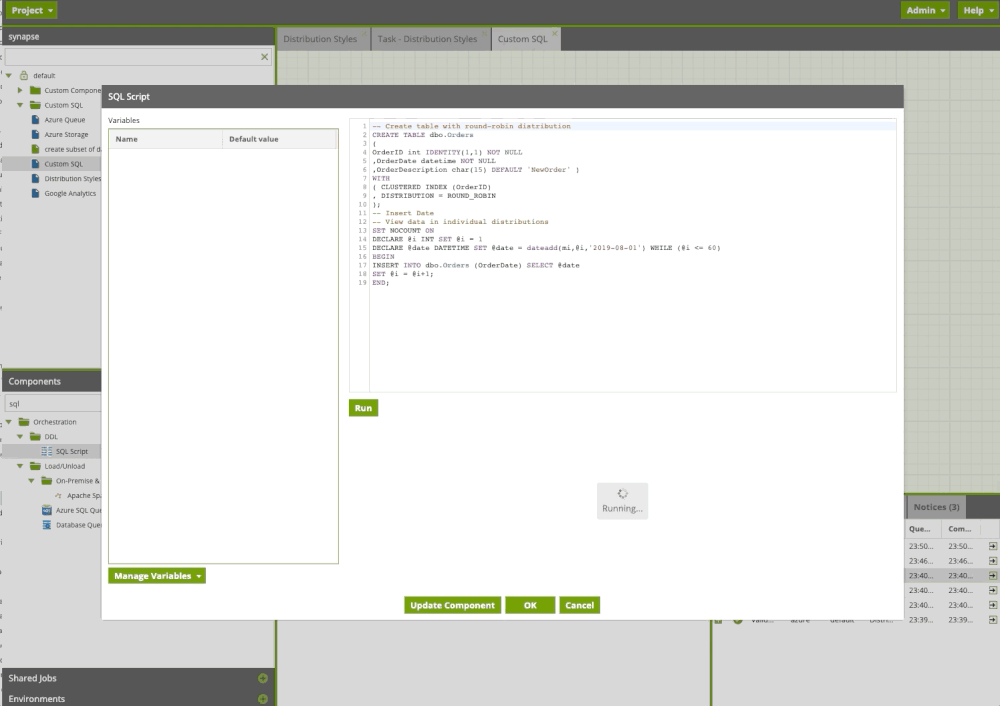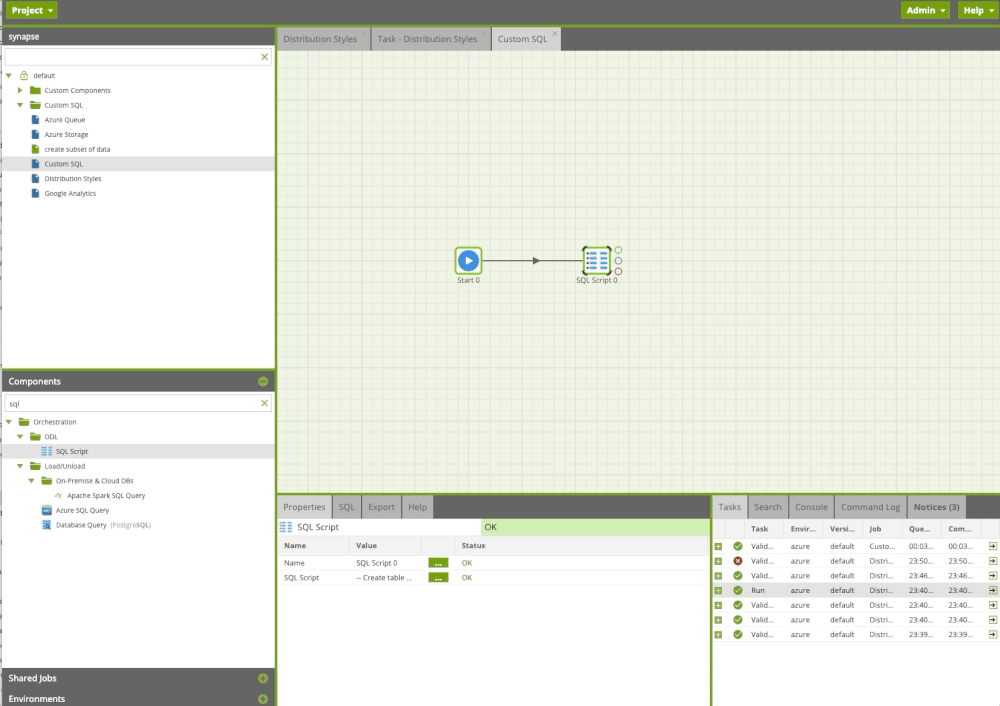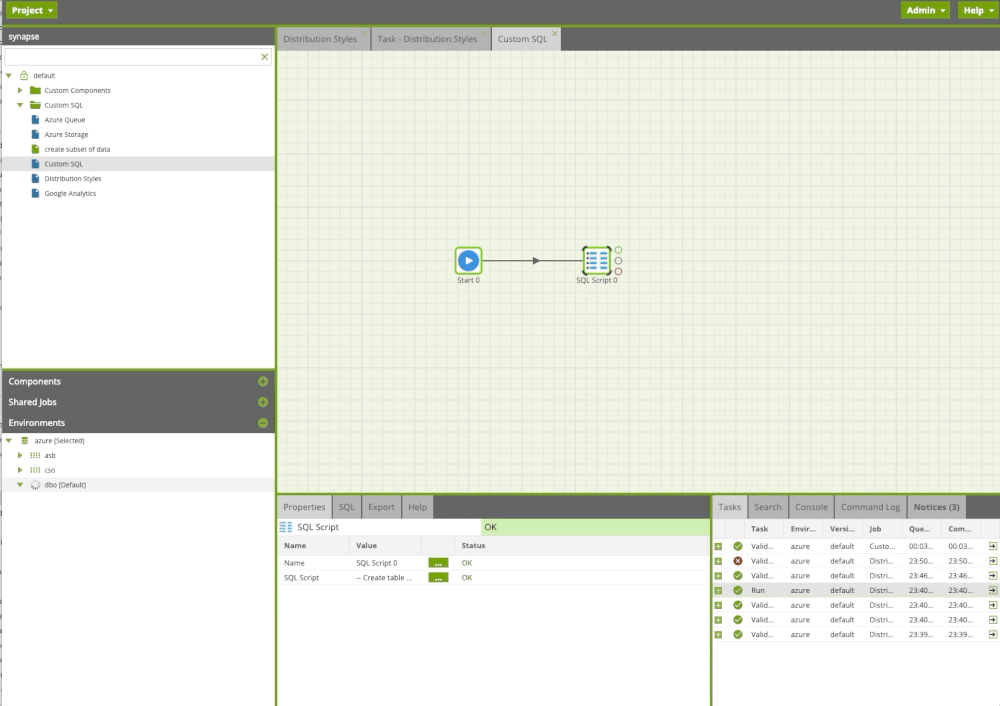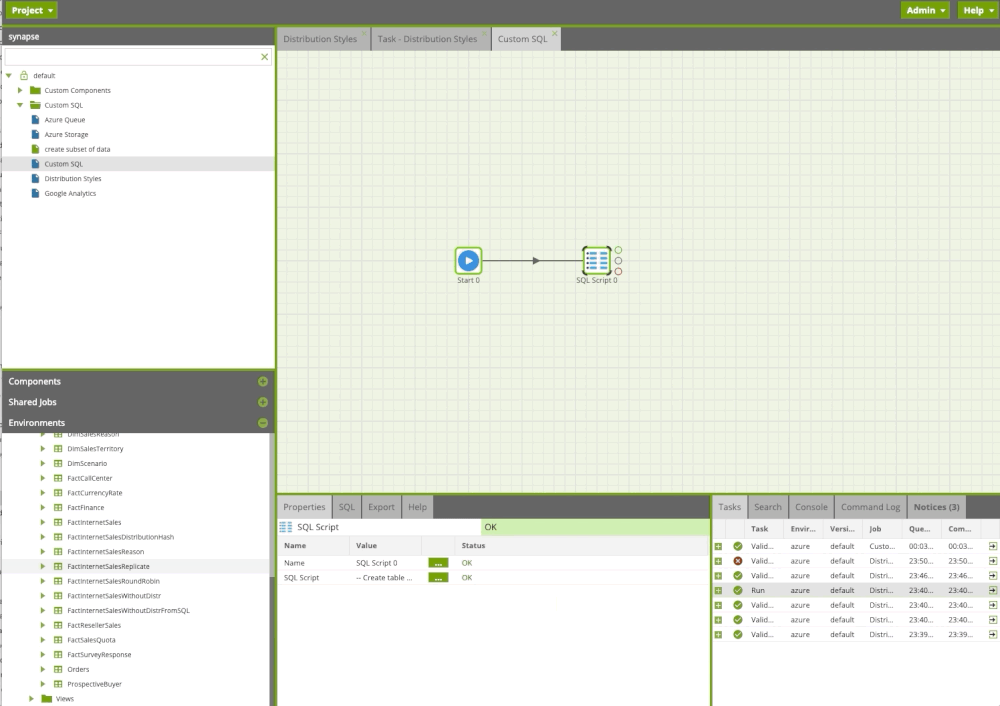
Custom SQL Component
Creating an Azure Queue
It is often desirable, especially with large workflows, to run Matillion ETL jobs in a remote, automated fashion and receive feedback in a similar manner.
Using the Azure console, we can create a Queue for our storage account and leverage it in Matillion ETL.
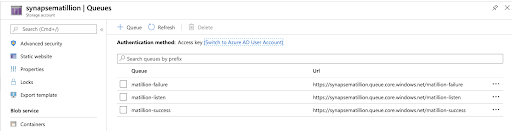
Matillion ETL has a specific component that we can drag and drop to our flow and then to a Queue, triggering a specific job inside or any action outside of Matillion . For example, we trigger another job that sends a Slack notification.
Loading data from third-party APIs
One of the key benefits of Matillion with Azure Synapse Analytics is fast time to market. It means that you can build your data pipelines fast. Almost every organization is using digital marketing resources such as social media, SEO, paid search and so on. It is critical to collect all data from third-party services and consolidate the data into your Azure Synapse data platform.
Matillion’s pre-built connectors do a great job of getting this done quickly.
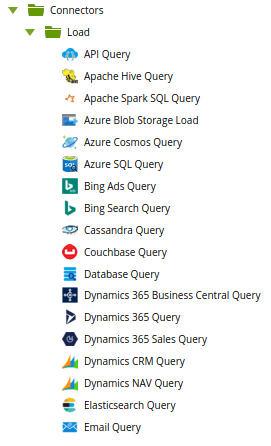
With traditional Microsoft SSIS or cloud based Azure Data Factory, it will take a long time just to develop these connectors.
In example below, we bring in Google Analytics data, where we can specify SQL code or choose the tables and columns.
Data Transformations in Azure Synapse
Assuming we successfully load raw data into the staging area of our data platform, the next step is to build the business layer for our data users with metrics and dimensions. Users can write queries, connect BI tools or use this data for data science.
Matillion ETL transformation components allow us to transform our data and leverage SQL without writing a single line of code. We can design our flow and build sophisticated data pipelines using drag and drop components. It is like Microsoft Integration Service, but it’s in the cloud and you have only Azure Synapse components.
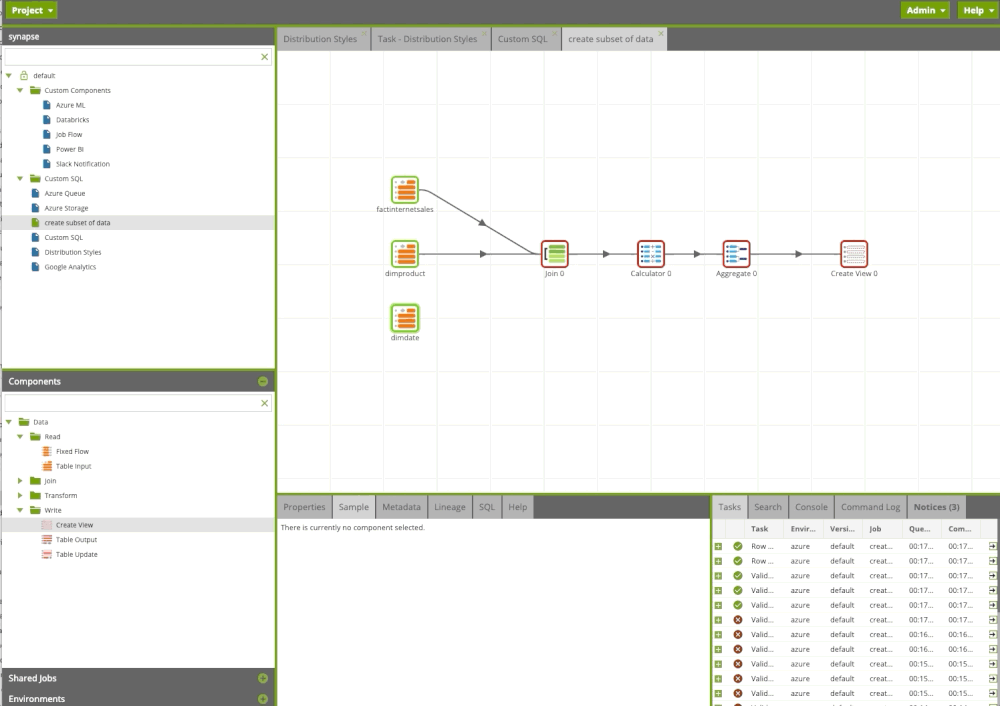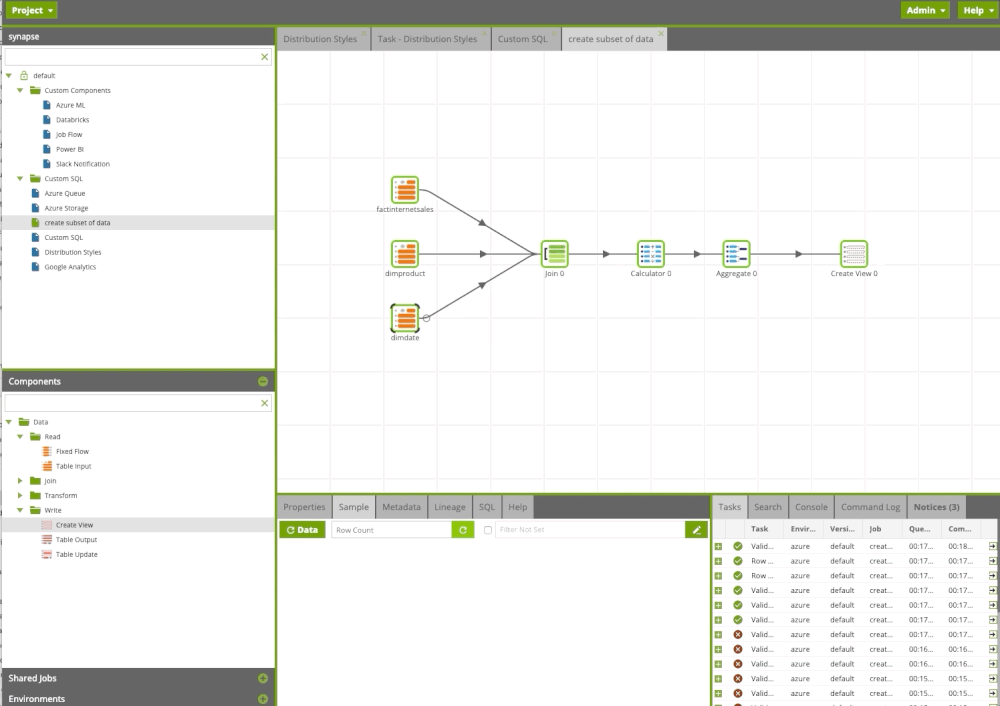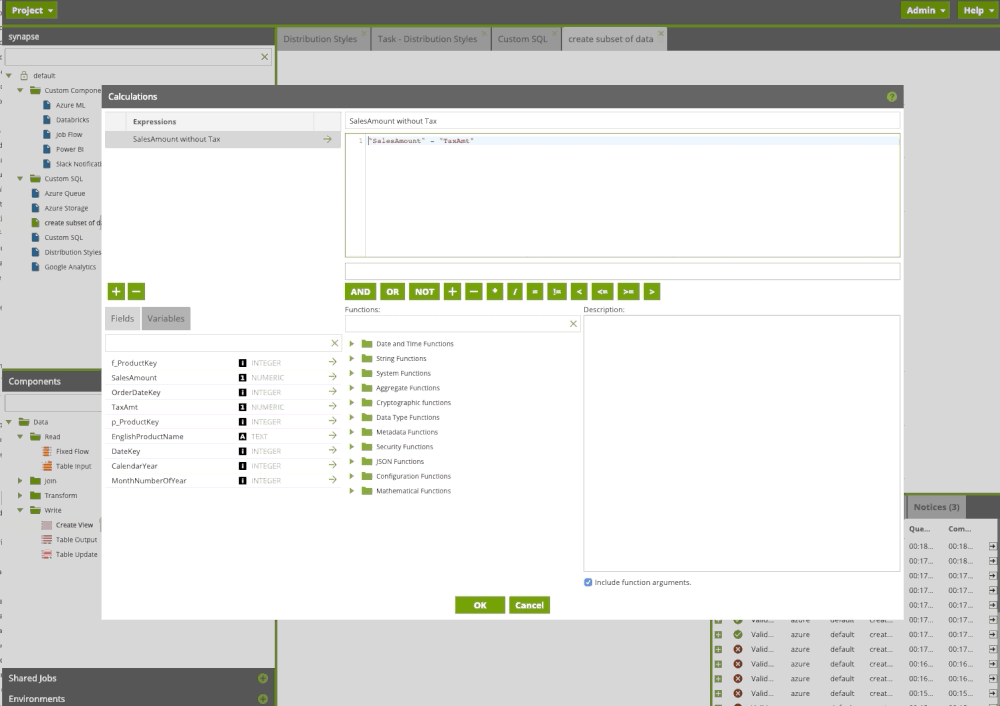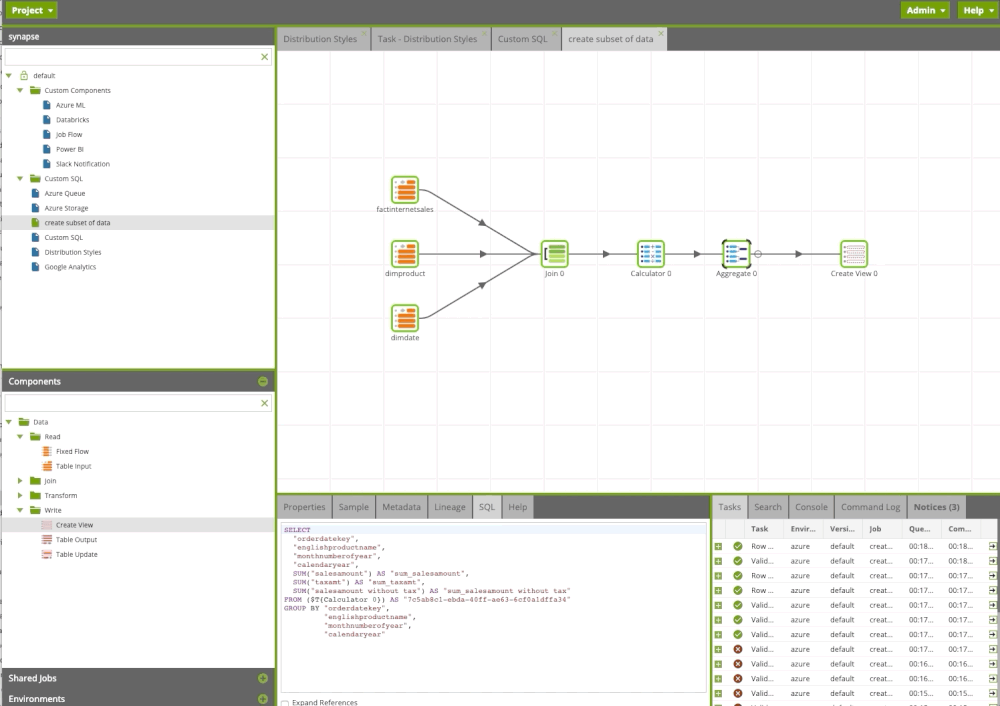
We can always add a copy code
Shared Jobs
In the example above, we saw an example where we were able to trigger a Slack notification from within Matillion ETL for Azure Synapse:
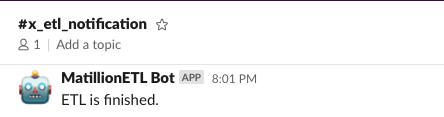
With Matillion ETL, we can create these custom components with specific actions and logic and control them with Matillion variables. These jobs are called Shared Jobs.
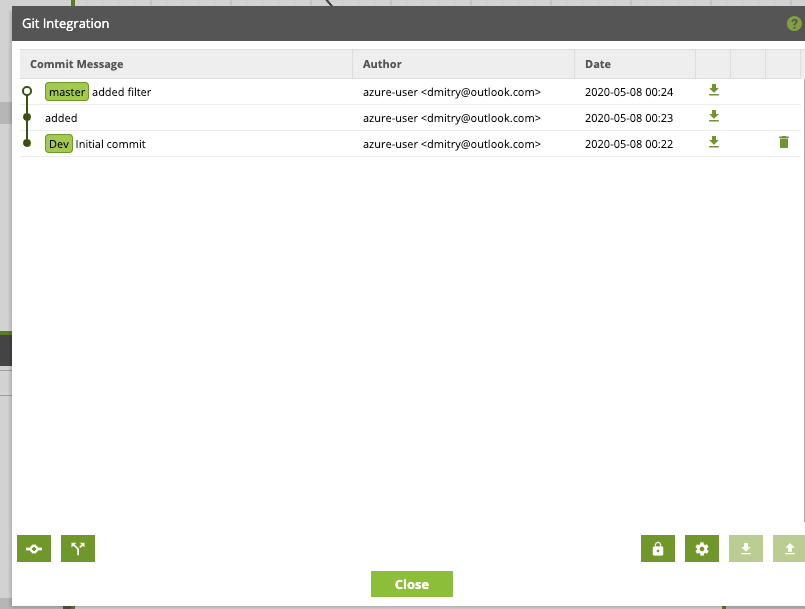
Version Control
Matillion ETL also has versioning features to help you manage versions of your ETL Transformation and Orchestration Jobs. Versioning supports many use cases, but perhaps the most salient is to be able to capture your development at a point in time to designate as “live” or “production”.
Doing a Matillion ETL proof of concept
If you want to see for yourself how Matillion ETL can benefit your Azure Synapse environment, I recommend doing a Proof of Concept.Matillion ETL for Azure Synapse includes a free 30-day trial so you can set it up within your infrastructure and work with your data.
About the author
Dmitry Anoshin is a technologist and recognized expert in building and implementing Modern Cloud Solutions. He has over 10 years of experience with analytics. He worked across different industries in Europe and North America and delivered end-to-end analytics solutions. His main interest now is Cloud Analytics with AWS, Azure, and GCP. Moreover, he is the author of 6 books related to analytics solutions including the first book about Snowflake – Jumpstart Snowflake: A Step-by-Step Guide to Modern Cloud Analytics. You can find more blog posts about modern analytics in his blog. Dmitry is running several useg groups including Tableau and Snowflake in Canada and often presenting at conferences and meetups. Finally, he is running a Cloud Computing course at the University of Victoria.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: