- Blog
- 07.28.2022
- Dev Dialogues
Top 10 Tips for Creating Fact Tables Using Matillion
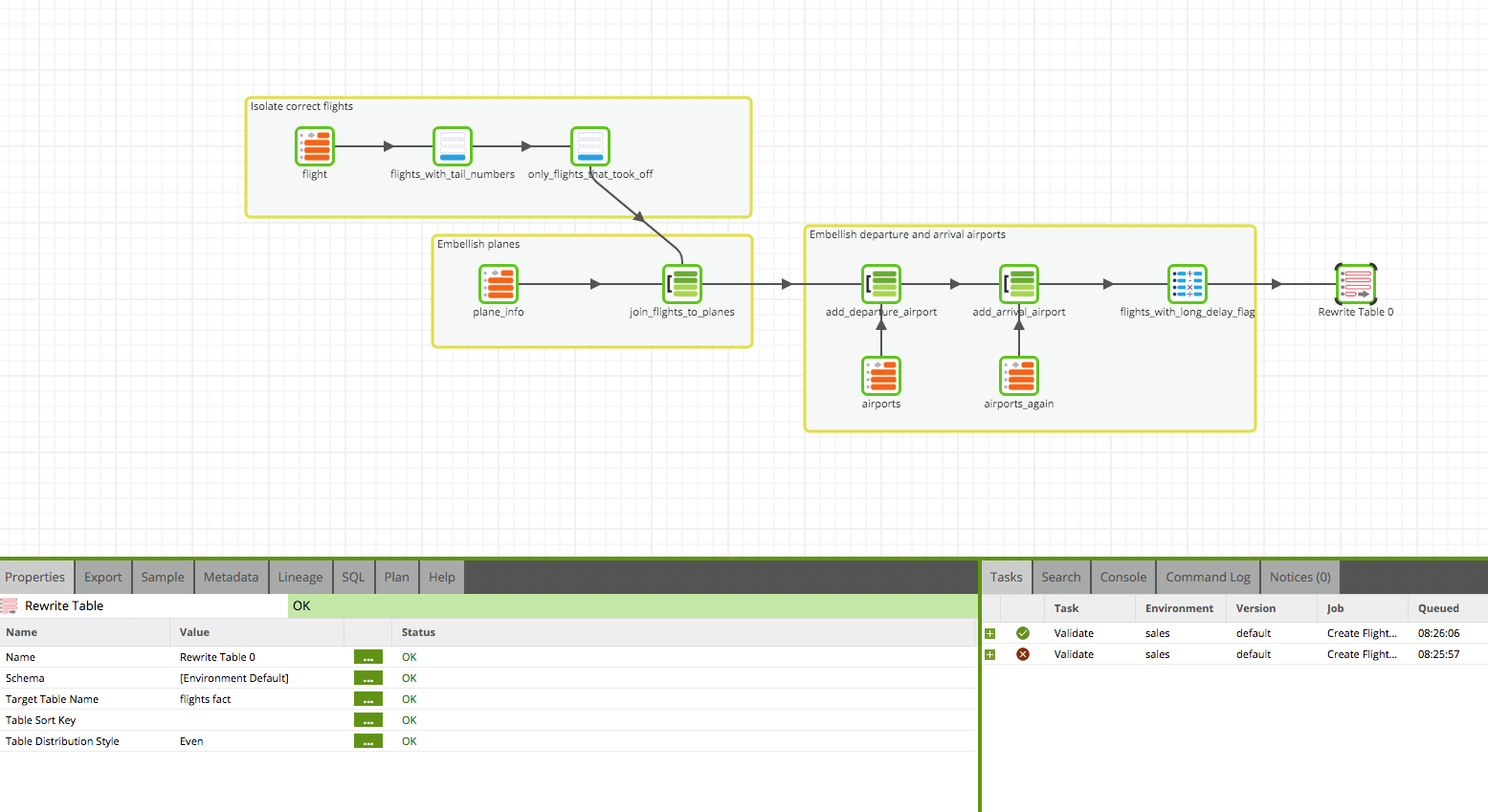
This is an article for data modelers who are using Matillion. It contains tips and best practices for implementing Fact tables in a Star Schema design.
Prerequisites
The prerequisites for creating Fact tables using Matillion are:
- Access to Matillion ETL
- You have already extracted and loaded the necessary data into your cloud data platform (CDP) – for example, using Matillion ETL or Matillion Data Loader
- The relevant Dimension tables exist
Tip 1: Model a business process
The first step when designing a Fact table is to be clear about which business process is being modeled. There are many different types of Fact tables, each with its own purpose:
- Transactional Fact tables – for standalone transactions
- Factless Fact tables – for events
- Derived tables:
- Aggregate Fact tables – for ease of use
- Periodic snapshot – at predictable intervals
- Accumulating snapshot – when transactions are updated repeatedly
Be clear about the purpose and type of every Fact table |

Tip 2: Set up Transactional Fact tables
Transactional Fact tables store data at the most granular level available for the process being modeled. The attributes are typically numeric and are not known in advance.
It is important to store single values at the lowest possible grain. Derived fields, such as ratios, should be calculated downstream (see tips 4 and 5).
Most transactions are never updated after they happen, so it is safe to simply insert new records using a Table Output component. But if the business process does allow updates, the Matillion Transformation Job will need to handle them. Provided the transactions have a unique identifier, a good method is to use a Table Update component.
From a DataOps perspective, in the event of an error or corruption it is useful to be able to reload selected transactions in bulk. Even if there is no unique identifier, reloading is usually still possible using date ranges.
Decide how to handle updates to transactional Fact records |
Transactional Fact tables are widely used, and are the default type. However, they do have one blind spot: events that did not happen. For example, the information that a product was on promotion, but no sales were made. This is a candidate for a Factless Fact table.
Tip 3: Consider Factless Fact tables
For business processes that focus on events, there may be no measures beyond the information provided by the Dimensions.
As an example, a Fact table for class attendance would record all the classes that a particular student attended on a particular day.
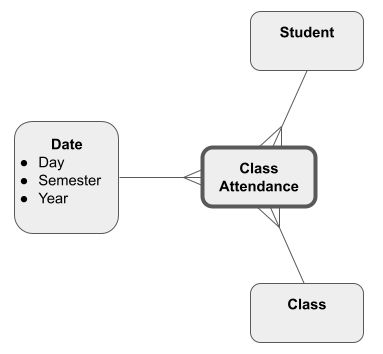
For this kind of data, the event either happened or it did not: The word “factless” means there are no extra attributes in addition to the Dimensions. All the value comes from the Dimensions alone.
However, to make Factless Fact tables easier to use, it is often helpful to add a numeric counter that always contains the value 1.
Add a numeric counter to factless fact tables |
Tip 4: Create Derived tables
Several further types of Fact tables can be created from Transactional or Factless Fact tables.
Aggregate Fact tables
These Fact tables are useful when there is a complication or performance issue with generating the required insight in a data presentation tool. Use cases include:
- When the logic is complex – an aggregate makes it easier to share and re-use
- When the logic is expensive – an aggregate means not having to do it over and over
Aggregates are usually simple tables, with reduced dimensionality, or none at all.
Periodic snapshot
Periodic snapshots are useful to bring a predictable, regular cadence to Transactional Fact tables. This kind of insight is hard to see by looking at the granular data.
As an example, an “end of day balance” periodic snapshot would show all the account balances at the end of every day. All the information comes from the transaction Facts, provided you can sum them and keep a running total.
Periodic snapshot tables are a useful starting point for trend analysis and month-on-month comparisons.
Accumulating snapshot
These snapshots are useful to track entities that go through a defined lifecycle. Once again, all the information is in the granular data but is hard to reach that way.
As an example, an invoice is created, then sent out, then paid, then cleared. It gathers information along the way – such as a Paid date – but remains the same invoice throughout.
Accumulating snapshots provide a shortcut to the current state of operations – for example, how many unpaid invoices there are right now.
To help with simplicity and maintainability, populate Derived Fact tables from other Fact tables |
Tip 5 – Use the lowest level granularity
Stick to the natural granularity of the business process being modeled, which should be the lowest grain available. It can be helpful to look for a naturally unique key, such as a transaction identifier (see tip 2).
Another way to think about this is that the granularity should be the intersection of all the Dimensions you intend to link.
It can be tempting to try and shoehorn multiple granularities into a single table. For example: transactions, plus their line items, plus maybe daily snapshots too. After all, the Dimensions are virtually identical. However, “multigrain” tables are much more difficult to understand, and should be avoided.
Use a consistent grain for transactional and factless Fact tables, storing data at the most detailed level available |
Keeping data at the lowest level of granularity gives the most flexibility. You can always roll up, but you can not roll back down.
Tip 6: Implement Fact table measures
Fact tables work best with numeric attributes, especially if the values can easily be aggregated. Often this is by summing – such as amounts, or counters (see tip 3).
To support attributes such as ratios that have to be calculated dynamically, just provide the clearly defined base metrics that the calculation requires.
Have a default aggregation rule for every measure |
Tip 7 – Take advantage of cloud data platform features
Modern cloud data platforms have a storage format known as column-major. Among other things, it is able to handle wide records without any reduction in query performance.
This introduces the option of storing free text fields in line with the rest of the (mainly numeric) Fact table attributes. Free text is unpredictable but can be mined for information such as sentiment.
So for example, in a feedback Fact table, it is feasible to store both:
- A numeric sentiment score – for analysis and reporting
- The original text – for use by data scientists who may wish to analyze it in many different ways
Sharing data in this way contributes to a healthy data culture.
Consider storing long text fields inline in Fact tables |
Tip 8: Use surrogate keys
Well designed Dimensions have a unique surrogate key column, plus a special record to handle missing information.
Creating Fact records in a Matillion Transformation Job mostly involves using Join components to look up the surrogate keys from Dimensions using a business key. If no match is found, default the surrogate key to the special “missing” value in the Dimension. That way, the foreign keys in the Fact table will always have a value.
Make all foreign key columns on Fact tables mandatory, and left-join to Dimensions |
Tip 9: Use Conformed Dimensions… when it makes sense
Implementing a “conformed” Dimension means that whenever anyone in the business talks about a certain “by” criteria, they are all referring to one single, common definition. In other words, multiple Fact tables link to the exact same Dimension table.
This is a powerful design pattern, with two major benefits:
- It becomes very simple to drill across – between Fact tables – at any level of aggregation. This underpins cross-departmental performance analysis
- It becomes much more likely that totals from different Fact tables will match
But conformed Dimensions come at a price. There must be a clearly defined owner, and the data must be made widely available. Every Fact table in the business must reference that single, shared Dimension table rather than a department-specific one.
In turn, this introduces a DataOps constraint. The conformed Dimension must be updated and made available to everyone before any new Fact data can be added.
The choice of whether to use conformed Dimensions is political, not technical |
Tip 10 – Create “stub” Dimension records for early arriving Facts
Referring back to the DataOps coordination constraint in Tip 9, if a Fact table is being updated before the relevant Dimension(s) are fully available, it is known as an early arriving Fact. The necessary surrogate keys might not all be available.
One approach is to use a well-known “missing” value as the surrogate key, as described in Tip 8. But that introduces a DataOps pain; remembering to update all the foreign keys later once the Dimension is fully available.
There is an alternative. By definition, the Dimension’s missing natural key is known, because it is used for the lookup. So there is enough information to create a new “stub” Dimension record, with all the attributes set to “unknown”. Later, when the Dimension data becomes available, the process just has to update one single dimension record. This is much simpler from a DataOps perspective.
Create stub dimension records for early arriving facts, using only the natural key |
Next steps
Try for yourself:
- You will find implementations of these techniques among the Matillion ETL downloadable examples, that you can install and run on your own system
Read Building a Star Schema with Matillion.
Learn about Dimension tables.
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: