- Blog
- 07.27.2022
- Dev Dialogues
Top 10 Tips for Creating Dimension Tables Using Matillion
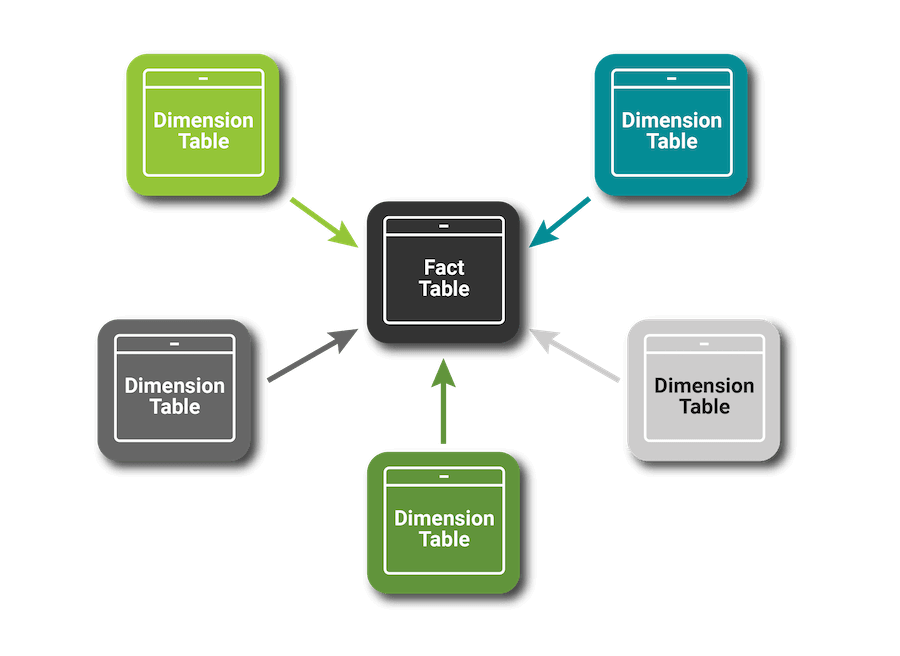
This is an article for data modelers who are using Matillion. It contains tips and best practices for implementing Dimension tables in a Star Schema design.
Prerequisites
The prerequisites for creating Dimension tables using Matillion are:
- Access to Matillion ETL
- You have already extracted and loaded the necessary data into your Cloud Data Platform (CDP) – for example, using Matillion ETL or Matillion Data Loader
Tip 1: Star Schema vs Snowflake Schema
This choice occurs whenever there is a hierarchy in a Dimension – for example date/semester/year.
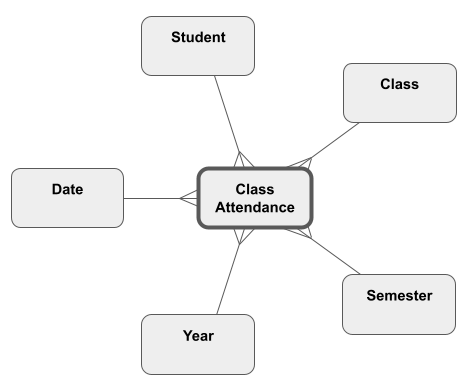
In a Star Schema, Dimension tables at all levels of the hierarchy are linked directly to the Fact table. The simplest way is to have a separate Dimension table for every level. In the Star Schema below, the date hierarchy is made up of three separate Dimension tables.
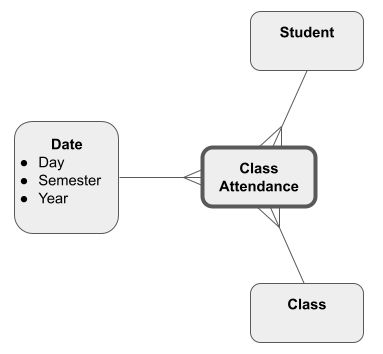
Alternatively, you can represent a hierarchy by repeating values inside the lowest-level Dimension table. In the Star Schema below, the semester and year hierarchy levels are included within the day-level ‘Date’ Dimension:
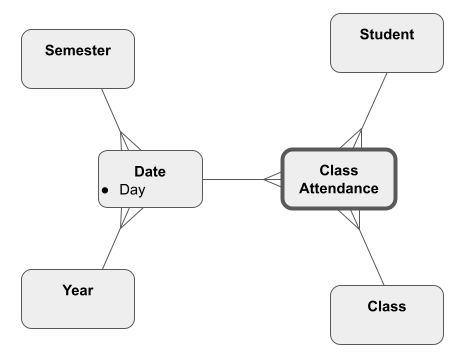
A Snowflake Schema always has a separate Dimension table for every level of the hierarchy. The difference is that higher levels are linked to other Dimension tables rather than to the Fact table. In the Snowflake Schema below, the year and semester Dimensions link to the ‘Date’ Dimension rather than directly to the Fact table.
All of the choices require some Matillion data transformation work to reliably create the repetition. This is known as denormalization.
Star Schemas have the advantage of being easier to understand. Analytic queries tend to require fewer joins overall, which makes them run faster. One DataOps consideration is that all the Dimension tables in a repeating-values Star Schema are completely independent, so they can be incrementally loaded in parallel.
Snowflake Schemas are slightly more normalized, so there is less data repetition. They are easier to maintain since there are fewer ways for the data to become inaccurate. It also means the data consumes slightly less storage space overall (see Tip 4). If you intend to implement aggregate Fact tables, there will always be a correctly grained Dimension table to use with the aggregate.
Decide whether a Star Schema or a Snowflake Schema is more appropriate, and keep to that choice |

Tip 2: Define the granularity of the table
Every Dimension table must have a clearly defined column (or columns) that uniquely identifies the rows. This is known as the natural key, business key, or unique key.
The natural key is required to successfully add data to the Dimension table. It is also needed for lookups when creating Fact table records.
Be clear about which column(s) form the natural, unique key |
Tip 3: Add a surrogate key
A surrogate key is an alternative primary key for a Dimension table. Surrogate keys form the link between Facts and Dimensions, and are easier and faster to use than natural keys. Surrogate keys are a big factor in making data more consumable.
| Deploy both a surrogate key and a natural key. |
Surrogate keys never exist at source; they have to be added by a Matillion Transformation Job.
Most surrogate keys are “meaningless,” which just signifies that there is no way to infer the business key from the surrogate key.
There are many ways to implement surrogate keys, including:
- Analytic function with high water mark
- Hash function
- A GUID-generating database function (if available)
- External token system
- Calculated (only appropriate for meaningful surrogate keys)
Tip 4: Take advantage of cloud data platform features
Modern cloud data platforms have a storage format known as column-major. It was designed specifically for the large volumes and sophisticated requirements of modern analytics.
Column-major storage enables novel compression techniques, so it’s fine to:
- Repeat the same value over and over in a Star Schema hierarchy (see Tip 1)
- Use long, meaningful descriptions rather than short, cryptic codes
Take advantage of your cloud data platform’s column-major storage to make your Dimension tables highly consumable |
Referring forward to Tip 9, the query optimizer built into any modern cloud data platform will handle views with no reduction in performance. That means it’s fine to implement Dimensions as either tables or views.
Tip 5: Numeric attributes in a Dimension
Numeric values are more commonly associated with Fact tables. But they can be appropriate for Dimension tables too. Examples include calculated, non-additive fields such as ratios. Be careful that the natural granularity of such fields is the same as the Dimension table itself (see Tip 2).
Continuous variables, such as a CSAT score, are very difficult to use as grouping or drill criteria. Banding is a great way around that. For example, you could band a CSAT score into discrete, string ranges such as “80-90%”.
Use banding with Dimension attributes that are continuous variables |
Tip 6: Handle unknown values
Real data never fits into a neatly planned dimension. This is one of the consequences of process-oriented thinking. It is technically fine to represent a misfit with a blank space. But blanks and nulls are often silently filtered out or ignored in reports, which can lead to inconsistencies.
Instead, it is better to be explicit and call out exceptions such as “Unknown,” “Other,” or “No Category.” Business users will often question these anomalies, so it is a great way to iteratively discover requirements.
Make all Dimension columns mandatory |
Tip 7: Handle unknown rows
Similarly to Tip 6, in reality, not all the Fact records will actually link to all the Dimensions they are supposed to.
To deal with this, always have a special Dimension record for Facts that don’t fit the pattern. The standard is to use positive surrogate keys for real values, and negative values for the misfits. For example, a surrogate key of -1 could represent “missing” or “unknown.”
You may take this further and use “unknown” values that are unique to your implementation. For example:
- -2 – not known yet – a shipped date for an order that has not yet been shipped
- -3 – inappropriate – when “this” kind of transaction never has “that” kind of attribute
- etc
Add an “Unknown” row to represent cases where a Dimension lookup fails |
Tip 8: Create dummy records to anticipate late arriving Dimensions
In an ideal batch schedule, all the Dimension tables get updated first. Then they are ready for the lookups needed by the Fact table updates that follow afterward.
Reality tends to be more complex. You may have a stream of Fact records joining to Dimensions that are only updated daily. Or there may be a failure updating a relatively insignificant Dimension, which can nevertheless delay the entire remainder of the processing.
Depending on your point of view, this situation is known as late arriving Dimensions or early arriving Facts.
The solution is to create dummy Dimension records from Fact data. You don’t know any of the Dimension attributes yet, but at least you do know the business keys.
Create late arriving dimension records from fact data |
There is a Matillion implementation in the “late arriving Dimension” area of the downloadable examples.
Tip 9 – Role-playing Dimensions
As designs gain sophistication with more and more Dimensions, overlaps should start to appear. For example, an order date requires a date Dimension, and a shipped date also requires a date Dimension.
In this situation, do not implement two real, separate Dimensions. Instead, implement just one underlying Dimension, and link to it multiple times. When a Dimension is linked multiple times, it is playing many different roles.
Role-playing can be done by having multiple foreign key columns on the Fact table:
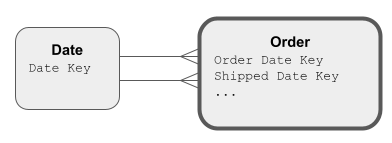
Alternatively, create a layer of views on a date Dimension table, and have the Fact table foreign keys link to the views:

A layer of views is simpler to consume, but requires extra administration. Referring back to Tip 4, there is no performance difference either way.
Tip 10 – Use a hashsum for change detection
Dimension tables are an excellent way of representing how the business has changed over time – known as time variance. For example, when sales boundaries change, a time-variant Dimension table can record today’s sales against the current boundaries, while still keeping an accurate historical record of last year’s sales against last year’s boundaries.
Part of maintaining a time-variant Dimension is repeatedly checking if any of the attributes have changed. To make this simple and efficient, implement a checksum column derived by running a hash algorithm against all the attributes.
Implement a hashsum column on every time-variant Dimension table |
A DataOps consideration is that Dimension attributes themselves are likely to change over time. A good way to help with this is to concatenate all the attributes in alphabetical order, and hash the result. In conjunction with Tip 6, this will ensure that schema drift will cause the checksum to change.
Next Steps
Try for yourself
- You will find implementations of these techniques among the Matillion ETL downloadable examples, that you can run on your own system
Featured Resources
What Are Feature Flags?
Feature flags are a software development tool that has the capability to control the visibility of any particular feature. ...
BlogHow Your Data Teams Can Do More With Marketing Analytics
Improve your marketing analytics with Matillion Data Productivity Cloud that enables businesses to centralize and integrate ...
BlogThe Importance of Data Classification in Cloud Security
Data classification enables the targeted protection and management of sensitive information. Personally Identifiable ...
Share: