- Blog
- 03.01.2023
How to use the Matillion ETL sample jobs
Matillion ETL users are able to access a set of pre-built sample jobs that demonstrate a range of data transformation and integration techniques. The sample jobs are available when creating a new Project in any Matillion ETL instance version 1.66 or later.
This article will show how to configure and run them.
Prerequisites
To use the Matillion ETL sample jobs, you will need:
- Access to Matillion ETL version 1.66 or later
- Access to a cloud storage area: S3, Blog Storage or GCS. You must be able to write to the chosen location.
You must either be using Matillion ETL for the first time, or else creating a new Matillion Project. Tick "Include Samples" in the Create Project dialog. 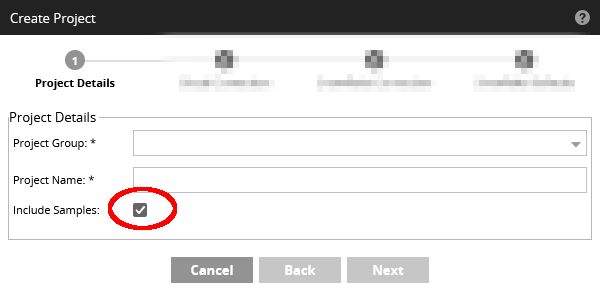 After completing the Create Project dialog, you will find the sample jobs have been installed into the folder structure.
After completing the Create Project dialog, you will find the sample jobs have been installed into the folder structure. 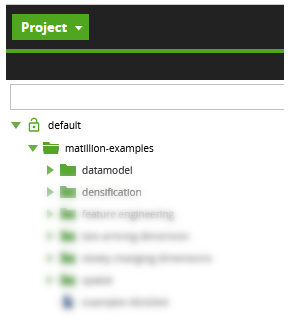 To run the sample jobs in your own system, you must configure some Environment Variables.
To run the sample jobs in your own system, you must configure some Environment Variables.
Environment Variables for the sample jobs
The Matillion ETL sample jobs run on your own cloud data warehouse. Some of them download public datasets. The jobs are configured by setting Environment Variables in the Project > Manage Environment Variables menu. 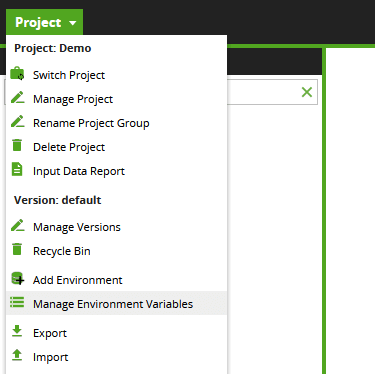 You will need to set either two or three Environment Variables, depending on your cloud platform and cloud data warehouse.
You will need to set either two or three Environment Variables, depending on your cloud platform and cloud data warehouse. 
The examples_storage Environment Variable
This variable is always required. Set the default value to the name of one of your cloud storage areas. You must have write access to it.
If you are using AWS, set examples_storage to your S3 bucket name
- Do not include the s3:// prefix
- Do not include any subfolders
- Choose a bucket in the same Region as your CDW
AWS example:  If you are using Azure, use a Container in a StorageV2 account. For example, if your StorageV2 account is named myacc, and your container is named abc then set examples_storage to myacc/abc
If you are using Azure, use a Container in a StorageV2 account. For example, if your StorageV2 account is named myacc, and your container is named abc then set examples_storage to myacc/abc
- Do not include any prefixes such as azure://, abfs:// or wasb://
- Do not include any substructure inside the container
- Choose a storage account in the same Geography and Region as your CDW
Azure example:  If you are using GCP, set examples_storage to your GCS bucket name
If you are using GCP, set examples_storage to your GCS bucket name
- Do not include the gs:// prefix
- Do not include any subfolders
- Choose a bucket in the same Location as your CDW
GCP example: 
The examples_schema Environment Variable
This is required for CDWs that differentiate between Databases and Schemas:
- Snowflake
- Amazon Redshift
- Azure Synapse
- Google BigQuery
Set the default value to the name of a database schema, in the default database, where example tables will be created. For example: 
The examples_database Environment Variable
This is only required for Delta Lake on Databricks, which does not differentiate between Databases and Schemas. Set the default value of examples_database to the name of the Delta database that will hold the example tables. For example: 
The examples_dataset Environment Variable
This is only required if you are using Google BigQuery. Set examples_dataset to the name of the dataset, in the default project, that you want to hold the example tables. 
The examples_storage_integration Environment Variable
This is only required if you are using Snowflake on GCP. Set the default value of examples_storage_integration to the name of a Storage Integration for the Matillion Cloud Storage Load component to use. 
Jobs in the datamodel folder
This large set of related jobs appears under matillion-examples. 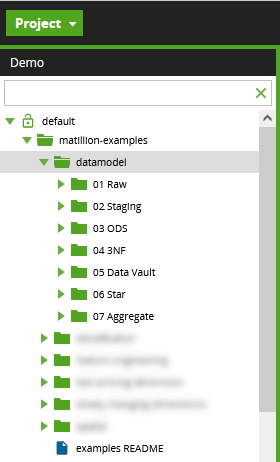 The jobs illustrate how to use Matillion to push data through the multiple data layers typically found in an enterprise data warehouse.
The jobs illustrate how to use Matillion to push data through the multiple data layers typically found in an enterprise data warehouse.
- Raw / Landing - just for data extraction and loading
- Staging - for technical fixes such as adjusting datatypes and relationalizing semi-structured and unstructured data
- ODS - to mirror one source system at a time. Often the result of a Change Data Capture (CDC) process.
- 3NF and/or Data Vault - a centralized, subject-oriented data model. This is typically where data integration occurs
- Star Schema - meeting specific reporting requirements, and representing gold standard consumability
- Aggregate - may be used for simplification or performance
To run the jobs, work through the subfolders in order, running the job that is alphabetically first in each subfolder.
The data underpinning these examples is used in the Analysis of Exponential Decay article.
Jobs in the densification folder
This set of related jobs appears under matillion-examples.  The jobs illustrate how to use Matillion to perform data densification. This is typically useful when preparing data for AI/ML. Various techniques are demonstrated, including:
The jobs illustrate how to use Matillion to perform data densification. This is typically useful when preparing data for AI/ML. Various techniques are demonstrated, including:
- Fixed value
- Last-known
- Rolling Mean
- Linear Regression
- Linear Backfill
To process the data, run the Orchestration Job within this subfolder. There is a full description in this Matillion article on numeric densification.
You can use this Tableau Public dashboard to compare the techniques visually. 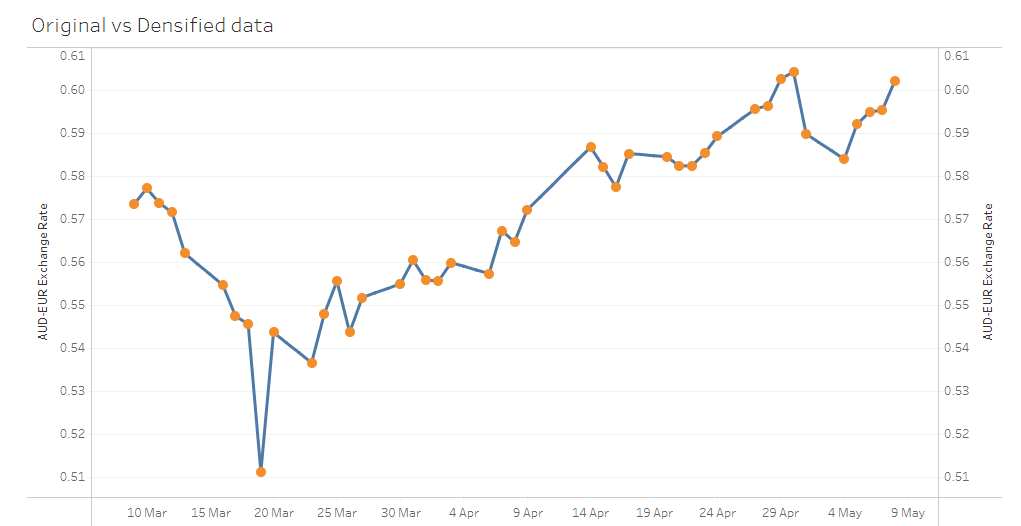
Jobs in the feature engineering folder
This set of jobs appears under matillion-examples.  The jobs show various ways that reporting and analytics teams can work on data to make it optimal for consumption by humans - via reports and dashboards. In this context their work is known as data transformation.
The jobs show various ways that reporting and analytics teams can work on data to make it optimal for consumption by humans - via reports and dashboards. In this context their work is known as data transformation.
Similarly, data science teams work on data to make it optimal for consumption by machines - via algorithms and AI/ML. They describe their work as feature engineering.
This article on Data-Driven Organizations and Data Culture gives much more detail and context. Examples include:
- Surrogate keys - used in Data Vault and in Star Schema Dimension Tables
- Contingency tables - used in the Matillion article on verifying the accuracy of forecasts
To process the data, run all the Orchestration Jobs in this subfolder.
Jobs in the late arriving dimension folder
This set of related jobs appears under matillion-examples.  The jobs demonstrate how to use Matillion ETL when building a star schema, whenever fact records sometimes have to be processed before all the dimensions have been completed.
The jobs demonstrate how to use Matillion ETL when building a star schema, whenever fact records sometimes have to be processed before all the dimensions have been completed.
This is known as handling Late Arriving Dimensions or Early Arriving Facts.
To fully process the data, run the "example LAD EAF orchestration" job.
If you prefer to step through the mechanics in more detail, run the sub jobs one at a time using context-click / Run Component. The last transformation job in the set is a simple example of data having "state":
- When you run it for the first time, the job adds one new record
- If you run the same job again, without changing anything else, there is nothing more to add and the job does nothing
Jobs in the slowly changing dimensions folder
This set of related jobs appears under matillion-examples.  All star schemas contain slowly changing dimensions in some shape or form. These jobs illustrate two main techniques for creating and maintaining them:
All star schemas contain slowly changing dimensions in some shape or form. These jobs illustrate two main techniques for creating and maintaining them:
- Physical dimension tables (type 1 and type 2)
- Virtualized dimension tables (type 1, type 2, type 3 and type 6)
Virtualized dimension tables are generally simpler to manage, and less can go wrong with them. Also they offer a great way to delegate authority in a Data Mesh architecture. Virtualized dimensions do require a 3NF or Data Vault layer to hold the underlying data.
To try it out, first run the "example scd ddl" job, to create the database objects.
Then run "example scd extract and load" repeatedly, to load initial data and build up some history. After each run, use the "example scd viewer" job to sample the data in the dimensions.
Jobs in the spatial folder
This set of related jobs appears under matillion-examples. These jobs are only installed for CDWs that have a built-in spatial datatype. There is also a dependency that the built-in geographic distance function works with a mixture of points and lines.  These jobs demonstrate how to perform spatial joins that add location awareness to Matillion data integration.
These jobs demonstrate how to perform spatial joins that add location awareness to Matillion data integration.
The sample data includes earthquake points and tectonic plate boundaries. To process these data sets, run the Orchestration Job within this subfolder. Full details are in this article on Geospatial Data Integration. You can use this Tableau Public dashboard to view the output from the Matillion jobs. 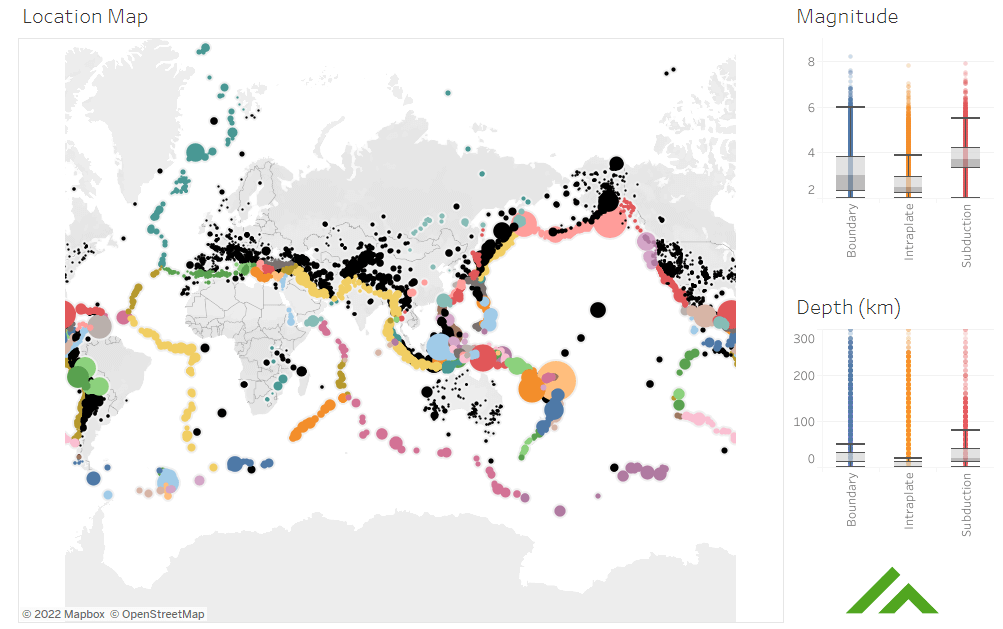
Next Steps
Try the sample jobs in your own environment! They should all run without alteration after the necessary Environment Variables have been set up.
The jobs are MIT licensed. Full details are documented in the examples README job.
Andreu Pintado
Featured Resources
Custom Connector for Public Statistics (Police API)
A demonstration of the practical steps for setting up components, manipulating and validating data, creating and scheduling ...
BlogMastering Git At Matillion. An In-Depth Guide To Merging
Merging in Git is the process of integrating changes from one branch into another. Merging is the backbone of collaboration in ...
BlogWhat is an API?
What is an API? An API is an application programming interface that is a way for two or more computer programs or components ...
Share: